 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntwisting RoPE: Frequency Control for Shared Attention in DiTs
Feb 04, 2026Positional encodings are essential to transformer-based generative models, yet their behavior in multimodal and attention-sharing settings is not fully understood. In this work, we present a principled analysis of Rotary Positional Embeddings (RoPE), showing that RoPE naturally decomposes into frequency components with distinct positional sensitivities. We demonstrate that this frequency structure explains why shared-attention mechanisms, where a target image is generated while attending to tokens from a reference image, can lead to reference copying, in which the model reproduces content from the reference instead of extracting only its stylistic cues. Our analysis reveals that the high-frequency components of RoPE dominate the attention computation, forcing queries to attend mainly to spatially aligned reference tokens and thereby inducing this unintended copying behavior. Building on these insights, we introduce a method for selectively modulating RoPE frequency bands so that attention reflects semantic similarity rather than strict positional alignment. Applied to modern transformer-based diffusion architectures, where all tokens share attention, this modulation restores stable and meaningful shared attention. As a result, it enables effective control over the degree of style transfer versus content copying, yielding a proper style-aligned generation process in which stylistic attributes are transferred without duplicating reference content.
Cora: Correspondence-aware image editing using few step diffusion
May 29, 2025Image editing is an important task in computer graphics, vision, and VFX, with recent diffusion-based methods achieving fast and high-quality results. However, edits requiring significant structural changes, such as non-rigid deformations, object modifications, or content generation, remain challenging. Existing few step editing approaches produce artifacts such as irrelevant texture or struggle to preserve key attributes of the source image (e.g., pose). We introduce Cora, a novel editing framework that addresses these limitations by introducing correspondence-aware noise correction and interpolated attention maps. Our method aligns textures and structures between the source and target images through semantic correspondence, enabling accurate texture transfer while generating new content when necessary. Cora offers control over the balance between content generation and preservation. Extensive experiments demonstrate that, quantitatively and qualitatively, Cora excels in maintaining structure, textures, and identity across diverse edits, including pose changes, object addition, and texture refinements. User studies confirm that Cora delivers superior results, outperforming alternatives.
CLiC: Concept Learning in Context
Nov 28, 2023


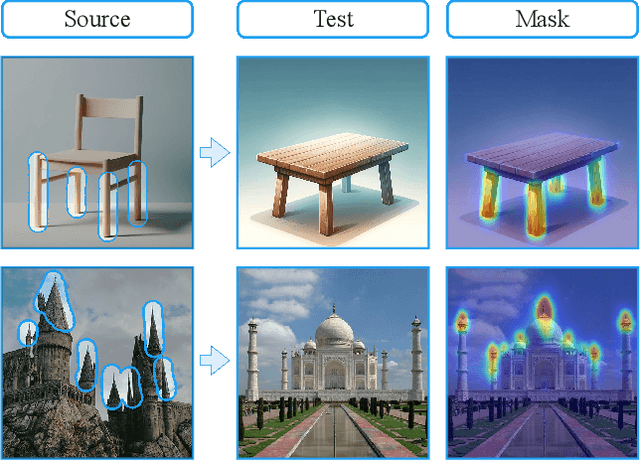
This paper addresses the challenge of learning a local visual pattern of an object from one image, and generating images depicting objects with that pattern. Learning a localized concept and placing it on an object in a target image is a nontrivial task, as the objects may have different orientations and shapes. Our approach builds upon recent advancements in visual concept learning. It involves acquiring a visual concept (e.g., an ornament) from a source image and subsequently applying it to an object (e.g., a chair) in a target image. Our key idea is to perform in-context concept learning, acquiring the local visual concept within the broader context of the objects they belong to. To localize the concept learning, we employ soft masks that contain both the concept within the mask and the surrounding image area. We demonstrate our approach through object generation within an image, showcasing plausible embedding of in-context learned concepts. We also introduce methods for directing acquired concepts to specific locations within target images, employing cross-attention mechanisms, and establishing correspondences between source and target objects. The effectiveness of our method is demonstrated through quantitative and qualitative experiments, along with comparisons against baseline techniques.
SKED: Sketch-guided Text-based 3D Editing
Mar 19, 2023



Text-to-image diffusion models are gradually introduced into computer graphics, recently enabling the development of Text-to-3D pipelines in an open domain. However, for interactive editing purposes, local manipulations of content through a simplistic textual interface can be arduous. Incorporating user guided sketches with Text-to-image pipelines offers users more intuitive control. Still, as state-of-the-art Text-to-3D pipelines rely on optimizing Neural Radiance Fields (NeRF) through gradients from arbitrary rendering views, conditioning on sketches is not straightforward. In this paper, we present SKED, a technique for editing 3D shapes represented by NeRFs. Our technique utilizes as few as two guiding sketches from different views to alter an existing neural field. The edited region respects the prompt semantics through a pre-trained diffusion model. To ensure the generated output adheres to the provided sketches, we propose novel loss functions to generate the desired edits while preserving the density and radiance of the base instance. We demonstrate the effectiveness of our proposed method through several qualitative and quantitative experiments.