 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePack: Representation Packing of Vision Foundation Model Features Enhances Diffusion Transformer
Dec 12, 2025The superior representation capability of pre-trained vision foundation models (VFMs) has been harnessed for enhancing latent diffusion models (LDMs). These approaches inject the rich semantics from high-dimensional VFM representations (e.g., DINOv3) into LDMs at different phases, resulting in accelerated learning and better generation performance. However, the high-dimensionality of VFM representations may also lead to Information Overload, particularly when the VFM features exceed the size of the original image for decoding. To address this issue while preserving the utility of VFM features, we propose RePack (Representation Packing), a simple yet effective framework for improving Diffusion Transformers (DiTs). RePack transforms the VFM representation into a more compact, decoder-friendly representation by projecting onto low-dimensional manifolds. We find that RePack can effectively filter out non-semantic noise while preserving the core structural information needed for high-fidelity reconstruction. Experimental results show that RePack significantly accelerates DiT convergence and outperforms recent methods that directly inject raw VFM features into the decoder for image reconstruction. On DiT-XL/2, RePack achieves an FID of 3.66 in only 64 epochs, which is 35% faster than the state-of-the-art method. This demonstrates that RePack successfully extracts the core semantics of VFM representations while bypassing their high-dimensionality side effects.
GLASS: Test-Time Acceleration for LLMs via Global-Local Neural Importance Aggregation
Aug 19, 2025Deploying Large Language Models (LLMs) on edge hardware demands aggressive, prompt-aware dynamic pruning to reduce computation without degrading quality. Static or predictor-based schemes either lock in a single sparsity pattern or incur extra runtime overhead, and recent zero-shot methods that rely on statistics from a single prompt fail on short prompt and/or long generation scenarios. We introduce A/I-GLASS: Activation- and Impact-based Global-Local neural importance Aggregation for feed-forward network SparSification, two training-free methods that dynamically select FFN units using a rank-aggregation of prompt local and model-intrinsic global neuron statistics. Empirical results across multiple LLMs and benchmarks demonstrate that GLASS significantly outperforms prior training-free methods, particularly in challenging long-form generation scenarios, without relying on auxiliary predictors or adding any inference overhead.
Cora: Correspondence-aware image editing using few step diffusion
May 29, 2025Image editing is an important task in computer graphics, vision, and VFX, with recent diffusion-based methods achieving fast and high-quality results. However, edits requiring significant structural changes, such as non-rigid deformations, object modifications, or content generation, remain challenging. Existing few step editing approaches produce artifacts such as irrelevant texture or struggle to preserve key attributes of the source image (e.g., pose). We introduce Cora, a novel editing framework that addresses these limitations by introducing correspondence-aware noise correction and interpolated attention maps. Our method aligns textures and structures between the source and target images through semantic correspondence, enabling accurate texture transfer while generating new content when necessary. Cora offers control over the balance between content generation and preservation. Extensive experiments demonstrate that, quantitatively and qualitatively, Cora excels in maintaining structure, textures, and identity across diverse edits, including pose changes, object addition, and texture refinements. User studies confirm that Cora delivers superior results, outperforming alternatives.
Qua$^2$SeDiMo: Quantifiable Quantization Sensitivity of Diffusion Models
Dec 19, 2024
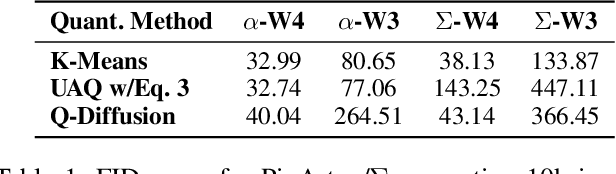

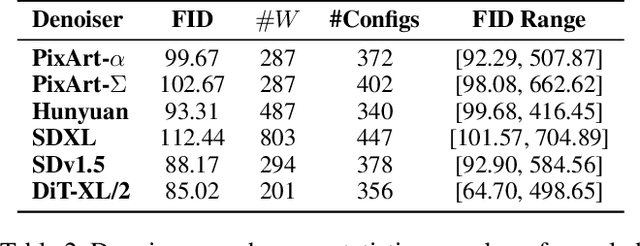
Diffusion Models (DM) have democratized AI image generation through an iterative denoising process. Quantization is a major technique to alleviate the inference cost and reduce the size of DM denoiser networks. However, as denoisers evolve from variants of convolutional U-Nets toward newer Transformer architectures, it is of growing importance to understand the quantization sensitivity of different weight layers, operations and architecture types to performance. In this work, we address this challenge with Qua$^2$SeDiMo, a mixed-precision Post-Training Quantization framework that generates explainable insights on the cost-effectiveness of various model weight quantization methods for different denoiser operation types and block structures. We leverage these insights to make high-quality mixed-precision quantization decisions for a myriad of diffusion models ranging from foundational U-Nets to state-of-the-art Transformers. As a result, Qua$^2$SeDiMo can construct 3.4-bit, 3.9-bit, 3.65-bit and 3.7-bit weight quantization on PixArt-${\alpha}$, PixArt-${\Sigma}$, Hunyuan-DiT and SDXL, respectively. We further pair our weight-quantization configurations with 6-bit activation quantization and outperform existing approaches in terms of quantitative metrics and generative image quality.
PixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
Dec 18, 2024



Recent research explores the potential of Diffusion Models (DMs) for consistent object editing, which aims to modify object position, size, and composition, etc., while preserving the consistency of objects and background without changing their texture and attributes. Current inference-time methods often rely on DDIM inversion, which inherently compromises efficiency and the achievable consistency of edited images. Recent methods also utilize energy guidance which iteratively updates the predicted noise and can drive the latents away from the original image, resulting in distortions. In this paper, we propose PixelMan, an inversion-free and training-free method for achieving consistent object editing via Pixel Manipulation and generation, where we directly create a duplicate copy of the source object at target location in the pixel space, and introduce an efficient sampling approach to iteratively harmonize the manipulated object into the target location and inpaint its original location, while ensuring image consistency by anchoring the edited image to be generated to the pixel-manipulated image as well as by introducing various consistency-preserving optimization techniques during inference. Experimental evaluations based on benchmark datasets as well as extensive visual comparisons show that in as few as 16 inference steps, PixelMan outperforms a range of state-of-the-art training-based and training-free methods (usually requiring 50 steps) on multiple consistent object editing tasks.
FRAP: Faithful and Realistic Text-to-Image Generation with Adaptive Prompt Weighting
Aug 21, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive capabilities in generating high-quality images given a text prompt. However, ensuring the prompt-image alignment remains a considerable challenge, i.e., generating images that faithfully align with the prompt's semantics. Recent works attempt to improve the faithfulness by optimizing the latent code, which potentially could cause the latent code to go out-of-distribution and thus produce unrealistic images. In this paper, we propose FRAP, a simple, yet effective approach based on adaptively adjusting the per-token prompt weights to improve prompt-image alignment and authenticity of the generated images. We design an online algorithm to adaptively update each token's weight coefficient, which is achieved by minimizing a unified objective function that encourages object presence and the binding of object-modifier pairs. Through extensive evaluations, we show FRAP generates images with significantly higher prompt-image alignment to prompts from complex datasets, while having a lower average latency compared to recent latent code optimization methods, e.g., 4 seconds faster than D&B on the COCO-Subject dataset. Furthermore, through visual comparisons and evaluation on the CLIP-IQA-Real metric, we show that FRAP not only improves prompt-image alignment but also generates more authentic images with realistic appearances. We also explore combining FRAP with prompt rewriting LLM to recover their degraded prompt-image alignment, where we observe improvements in both prompt-image alignment and image quality.
Drawing Inductor Layout with a Reinforcement Learning Agent: Method and Application for VCO Inductors
Feb 25, 2022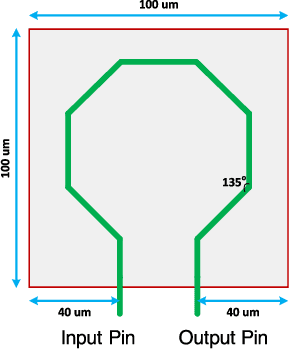
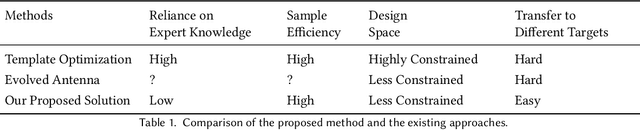
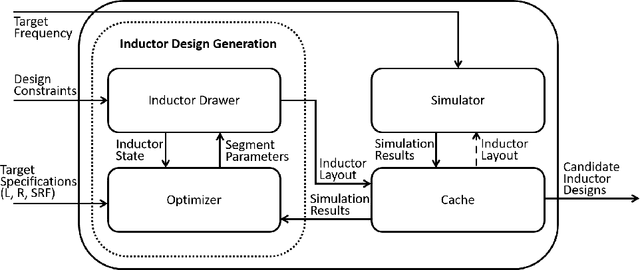
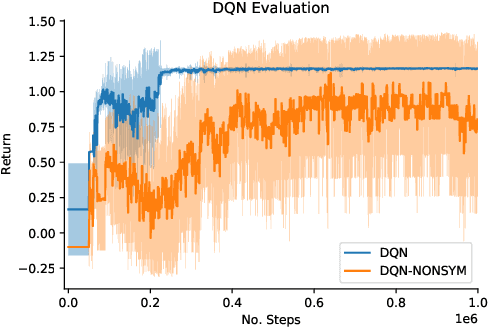
Design of Voltage-Controlled Oscillator (VCO) inductors is a laborious and time-consuming task that is conventionally done manually by human experts. In this paper, we propose a framework for automating the design of VCO inductors, using Reinforcement Learning (RL). We formulate the problem as a sequential procedure, where wire segments are drawn one after another, until a complete inductor is created. We then employ an RL agent to learn to draw inductors that meet certain target specifications. In light of the need to tweak the target specifications throughout the circuit design cycle, we also develop a variant in which the agent can learn to quickly adapt to draw new inductors for moderately different target specifications. Our empirical results show that the proposed framework is successful at automatically generating VCO inductors that meet or exceed the target specification.
Variational Auto-Encoder Architectures that Excel at Causal Inference
Nov 11, 2021
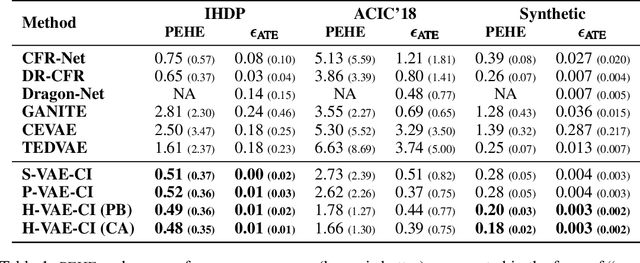


Estimating causal effects from observational data (at either an individual -- or a population -- level) is critical for making many types of decisions. One approach to address this task is to learn decomposed representations of the underlying factors of data; this becomes significantly more challenging when there are confounding factors (which influence both the cause and the effect). In this paper, we take a generative approach that builds on the recent advances in Variational Auto-Encoders to simultaneously learn those underlying factors as well as the causal effects. We propose a progressive sequence of models, where each improves over the previous one, culminating in the Hybrid model. Our empirical results demonstrate that the performance of all three proposed models are superior to both state-of-the-art discriminative as well as other generative approaches in the literature.
Reducing Selection Bias in Counterfactual Reasoning for Individual Treatment Effects Estimation
Dec 19, 2019

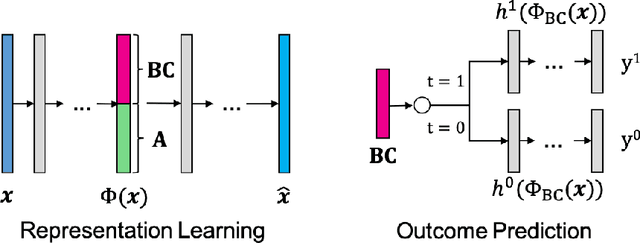

Counterfactual reasoning is an important paradigm applicable in many fields, such as healthcare, economics, and education. In this work, we propose a novel method to address the issue of \textit{selection bias}. We learn two groups of latent random variables, where one group corresponds to variables that only cause selection bias, and the other group is relevant for outcome prediction. They are learned by an auto-encoder where an additional regularized loss based on Pearson Correlation Coefficient (PCC) encourages the de-correlation between the two groups of random variables. This allows for explicitly alleviating selection bias by only keeping the latent variables that are relevant for estimating individual treatment effects. Experimental results on a synthetic toy dataset and a benchmark dataset show that our algorithm is able to achieve state-of-the-art performance and improve the result of its counterpart that does not explicitly model the selection bias.