 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Clipping for Deep Continual and Reinforcement Learning
Jul 01, 2024



Many failures in deep continual and reinforcement learning are associated with increasing magnitudes of the weights, making them hard to change and potentially causing overfitting. While many methods address these learning failures, they often change the optimizer or the architecture, a complexity that hinders widespread adoption in various systems. In this paper, we focus on learning failures that are associated with increasing weight norm and we propose a simple technique that can be easily added on top of existing learning systems: clipping neural network weights to limit them to a specific range. We study the effectiveness of weight clipping in a series of supervised and reinforcement learning experiments. Our empirical results highlight the benefits of weight clipping for generalization, addressing loss of plasticity and policy collapse, and facilitating learning with a large replay ratio.
More Efficient Randomized Exploration for Reinforcement Learning via Approximate Sampling
Jun 18, 2024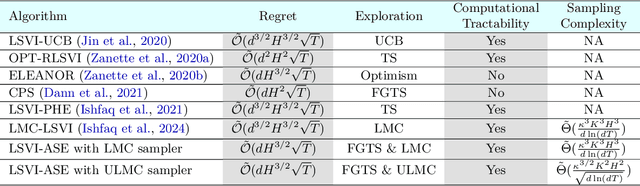
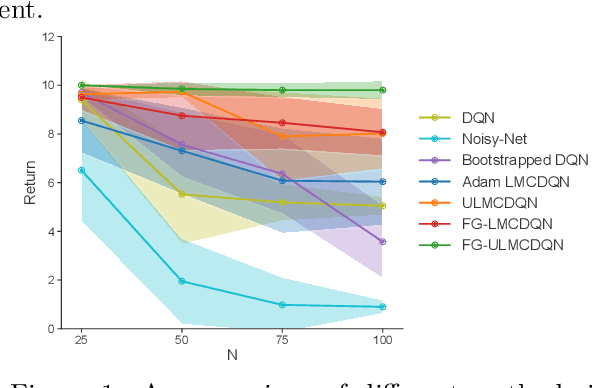
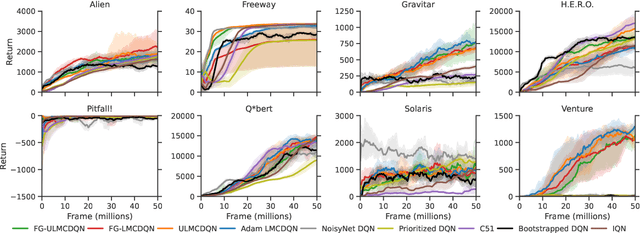

Thompson sampling (TS) is one of the most popular exploration techniques in reinforcement learning (RL). However, most TS algorithms with theoretical guarantees are difficult to implement and not generalizable to Deep RL. While the emerging approximate sampling-based exploration schemes are promising, most existing algorithms are specific to linear Markov Decision Processes (MDP) with suboptimal regret bounds, or only use the most basic samplers such as Langevin Monte Carlo. In this work, we propose an algorithmic framework that incorporates different approximate sampling methods with the recently proposed Feel-Good Thompson Sampling (FGTS) approach (Zhang, 2022; Dann et al., 2021), which was previously known to be computationally intractable in general. When applied to linear MDPs, our regret analysis yields the best known dependency of regret on dimensionality, surpassing existing randomized algorithms. Additionally, we provide explicit sampling complexity for each employed sampler. Empirically, we show that in tasks where deep exploration is necessary, our proposed algorithms that combine FGTS and approximate sampling perform significantly better compared to other strong baselines. On several challenging games from the Atari 57 suite, our algorithms achieve performance that is either better than or on par with other strong baselines from the deep RL literature.
Elephant Neural Networks: Born to Be a Continual Learner
Oct 02, 2023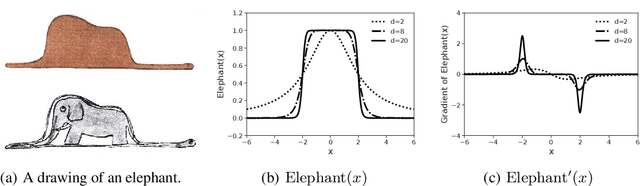
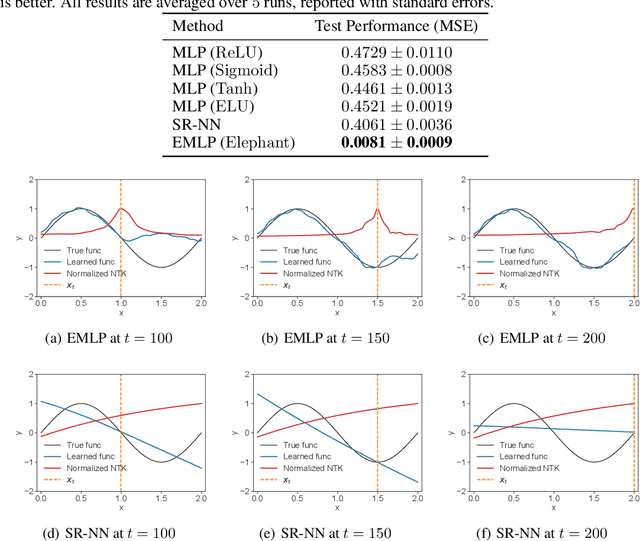
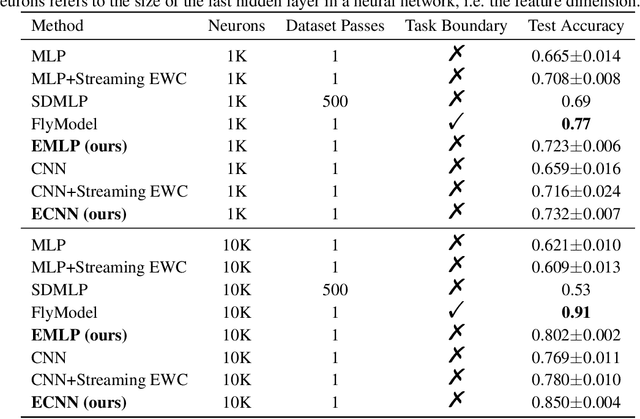
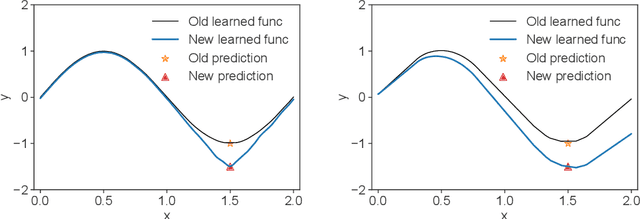
Catastrophic forgetting remains a significant challenge to continual learning for decades. While recent works have proposed effective methods to mitigate this problem, they mainly focus on the algorithmic side. Meanwhile, we do not fully understand what architectural properties of neural networks lead to catastrophic forgetting. This study aims to fill this gap by studying the role of activation functions in the training dynamics of neural networks and their impact on catastrophic forgetting. Our study reveals that, besides sparse representations, the gradient sparsity of activation functions also plays an important role in reducing forgetting. Based on this insight, we propose a new class of activation functions, elephant activation functions, that can generate both sparse representations and sparse gradients. We show that by simply replacing classical activation functions with elephant activation functions, we can significantly improve the resilience of neural networks to catastrophic forgetting. Our method has broad applicability and benefits for continual learning in regression, class incremental learning, and reinforcement learning tasks. Specifically, we achieves excellent performance on Split MNIST dataset in just one single pass, without using replay buffer, task boundary information, or pre-training.
Provable and Practical: Efficient Exploration in Reinforcement Learning via Langevin Monte Carlo
May 29, 2023
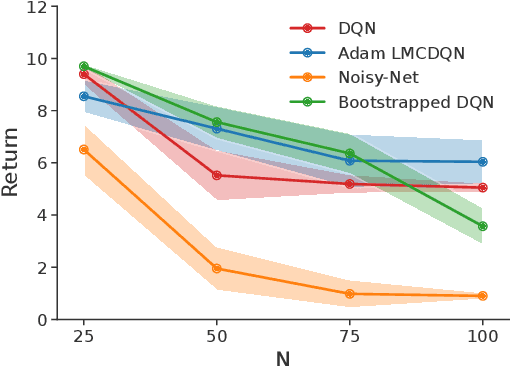
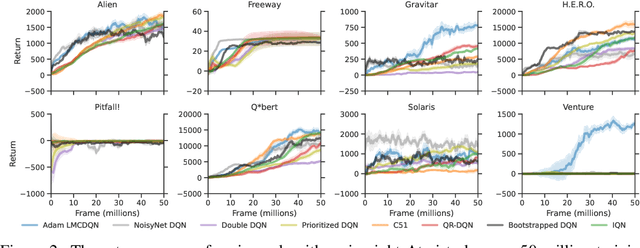

We present a scalable and effective exploration strategy based on Thompson sampling for reinforcement learning (RL). One of the key shortcomings of existing Thompson sampling algorithms is the need to perform a Gaussian approximation of the posterior distribution, which is not a good surrogate in most practical settings. We instead directly sample the Q function from its posterior distribution, by using Langevin Monte Carlo, an efficient type of Markov Chain Monte Carlo (MCMC) method. Our method only needs to perform noisy gradient descent updates to learn the exact posterior distribution of the Q function, which makes our approach easy to deploy in deep RL. We provide a rigorous theoretical analysis for the proposed method and demonstrate that, in the linear Markov decision process (linear MDP) setting, it has a regret bound of $\tilde{O}(d^{3/2}H^{5/2}\sqrt{T})$, where $d$ is the dimension of the feature mapping, $H$ is the planning horizon, and $T$ is the total number of steps. We apply this approach to deep RL, by using Adam optimizer to perform gradient updates. Our approach achieves better or similar results compared with state-of-the-art deep RL algorithms on several challenging exploration tasks from the Atari57 suite.
Learning to Optimize for Reinforcement Learning
Feb 03, 2023In recent years, by leveraging more data, computation, and diverse tasks, learned optimizers have achieved remarkable success in supervised learning optimization, outperforming classical hand-designed optimizers. However, in practice, these learned optimizers fail to generalize to reinforcement learning tasks due to unstable and complex loss landscapes. Moreover, neither hand-designed optimizers nor learned optimizers have been specifically designed to address the unique optimization properties in reinforcement learning. In this work, we take a data-driven approach to learn to optimize for reinforcement learning using meta-learning. We introduce a novel optimizer structure that significantly improves the training efficiency of learned optimizers, making it possible to learn an optimizer for reinforcement learning from scratch. Although trained in toy tasks, our learned optimizer demonstrates its generalization ability to unseen complex tasks. Finally, we design a set of small gridworlds to train the first general-purpose optimizer for reinforcement learning.
Memory-efficient Reinforcement Learning with Knowledge Consolidation
May 22, 2022


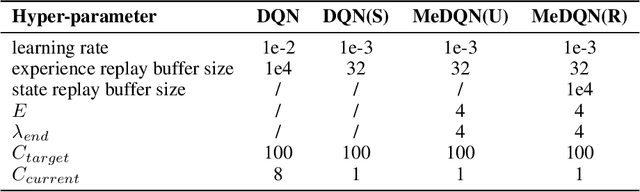
Artificial neural networks are promising as general function approximators but challenging to train on non-independent and identically distributed data due to catastrophic forgetting. Experience replay, a standard component in deep reinforcement learning, is often used to reduce forgetting and improve sample efficiency by storing experiences in a large buffer and using them for training later. However, a large replay buffer results in a heavy memory burden, especially for onboard and edge devices with limited memory capacities. We propose memory-efficient reinforcement learning algorithms based on the deep Q-network algorithm to alleviate this problem. Our algorithms reduce forgetting and maintain high sample efficiency by consolidating knowledge from the target Q-network to the current Q-network. Compared to baseline methods, our algorithms achieve comparable or better performance on both feature-based and image-based tasks while easing the burden of large experience replay buffers.
Variational Quantum Soft Actor-Critic
Dec 20, 2021
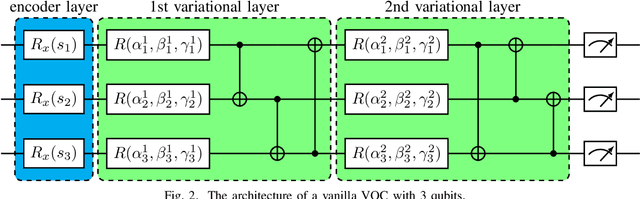
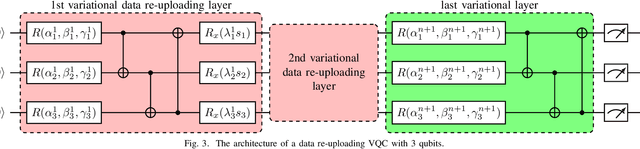
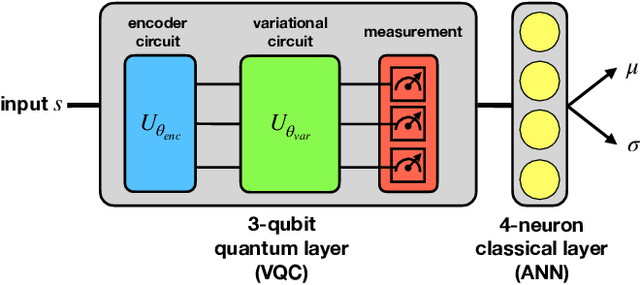
Quantum computing has a superior advantage in tackling specific problems, such as integer factorization and Simon's problem. For more general tasks in machine learning, by applying variational quantum circuits, more and more quantum algorithms have been proposed recently, especially in supervised learning and unsupervised learning. However, little work has been done in reinforcement learning, arguably more important and challenging. Previous work in quantum reinforcement learning mainly focuses on discrete control tasks where the action space is discrete. In this work, we develop a quantum reinforcement learning algorithm based on soft actor-critic -- one of the state-of-the-art methods for continuous control. Specifically, we use a hybrid quantum-classical policy network consisting of a variational quantum circuit and a classical artificial neural network. Tested in a standard reinforcement learning benchmark, we show that this quantum version of soft actor-critic is comparable with the original soft actor-critic, using much less adjustable parameters. Furthermore, we analyze the effect of different hyper-parameters and policy network architectures, pointing out the importance of architecture design for quantum reinforcement learning.
Predictive Representation Learning for Language Modeling
May 29, 2021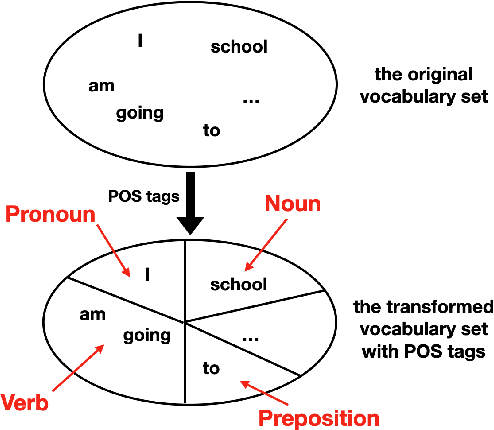
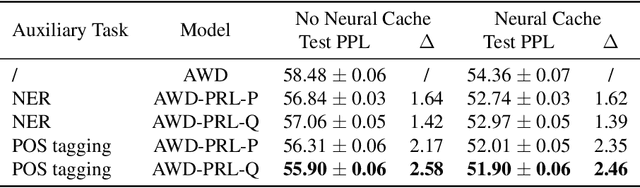
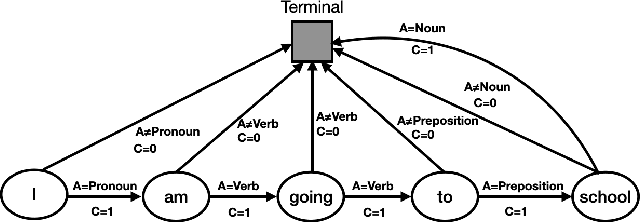
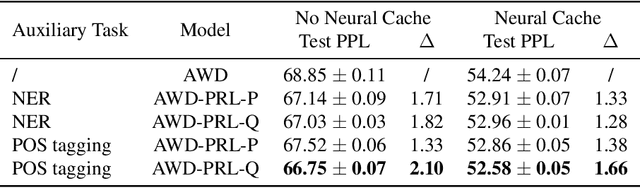
To effectively perform the task of next-word prediction, long short-term memory networks (LSTMs) must keep track of many types of information. Some information is directly related to the next word's identity, but some is more secondary (e.g. discourse-level features or features of downstream words). Correlates of secondary information appear in LSTM representations even though they are not part of an \emph{explicitly} supervised prediction task. In contrast, in reinforcement learning (RL), techniques that explicitly supervise representations to predict secondary information have been shown to be beneficial. Inspired by that success, we propose Predictive Representation Learning (PRL), which explicitly constrains LSTMs to encode specific predictions, like those that might need to be learned implicitly. We show that PRL 1) significantly improves two strong language modeling methods, 2) converges more quickly, and 3) performs better when data is limited. Our work shows that explicitly encoding a simple predictive task facilitates the search for a more effective language model.
Model-free Policy Learning with Reward Gradients
Mar 09, 2021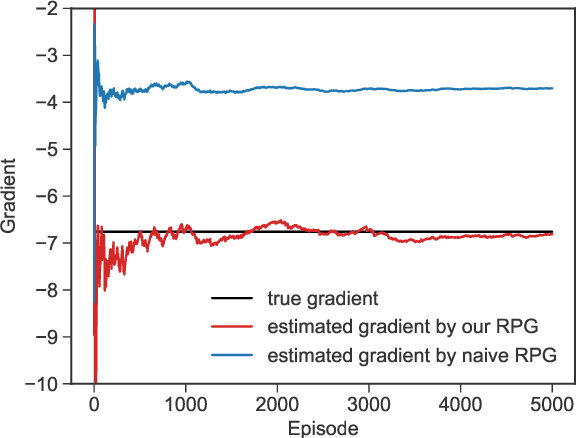
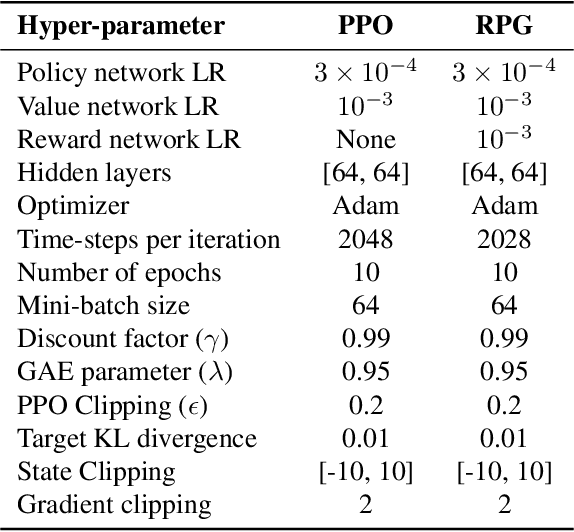
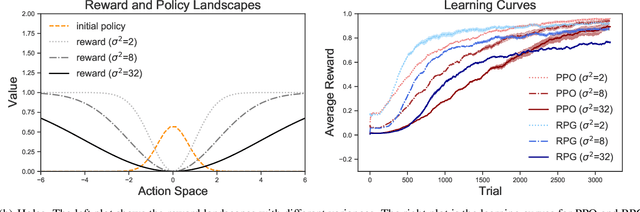
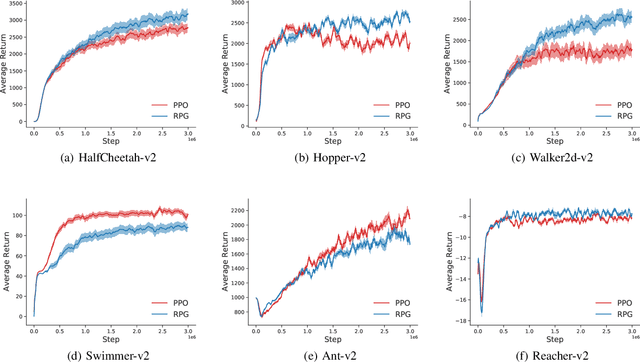
Policy gradient methods estimate the gradient of a policy objective solely based on either the likelihood ratio (LR) estimator or the reparameterization (RP) estimator for estimating gradients. Many policy gradient methods based on the LR estimator can be unified under the policy gradient theorem (Sutton et al., 2000). However, such a unifying theorem does not exist for policy gradient methods based on the RP estimator. Moreover, no existing method requires and uses both estimators beyond a trivial interpolation between them. In this paper, we provide a theoretical framework that unifies several existing policy gradient methods based on the RP estimator. Utilizing our framework, we introduce a novel strategy to compute the policy gradient that, for the first time, incorporates both the LR and RP estimators and can be unbiased only when both estimators are present. Based on this strategy, we develop a new on-policy algorithm called the Reward Policy Gradient algorithm, which is the first model-free policy gradient method to utilize reward gradients. Using an idealized environment, we show that policy gradient solely based on the RP estimator for rewards are biased even with true rewards whereas our combined estimator is not. Finally, we show that our method either performs comparably with or outperforms Proximal Policy Optimization -- an LR-based on-policy method -- on several continuous control tasks.
Maxmin Q-learning: Controlling the Estimation Bias of Q-learning
Feb 16, 2020


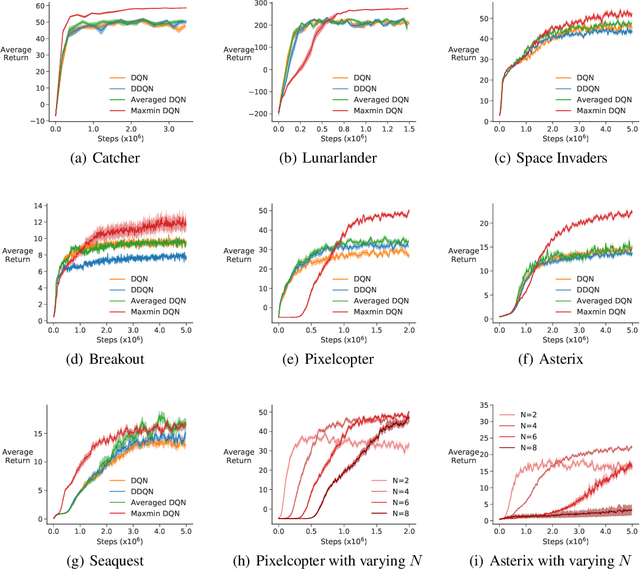
Q-learning suffers from overestimation bias, because it approximates the maximum action value using the maximum estimated action value. Algorithms have been proposed to reduce overestimation bias, but we lack an understanding of how bias interacts with performance, and the extent to which existing algorithms mitigate bias. In this paper, we 1) highlight that the effect of overestimation bias on learning efficiency is environment-dependent; 2) propose a generalization of Q-learning, called \emph{Maxmin Q-learning}, which provides a parameter to flexibly control bias; 3) show theoretically that there exists a parameter choice for Maxmin Q-learning that leads to unbiased estimation with a lower approximation variance than Q-learning; and 4) prove the convergence of our algorithm in the tabular case, as well as convergence of several previous Q-learning variants, using a novel Generalized Q-learning framework. We empirically verify that our algorithm better controls estimation bias in toy environments, and that it achieves superior performance on several benchmark problems.