 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElephant Neural Networks: Born to Be a Continual Learner
Paper and Code
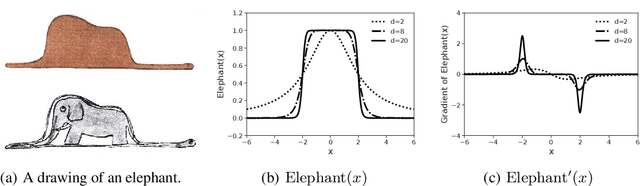
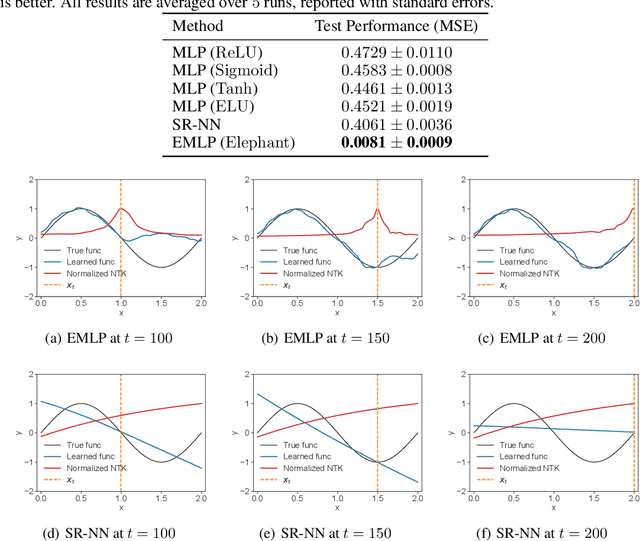
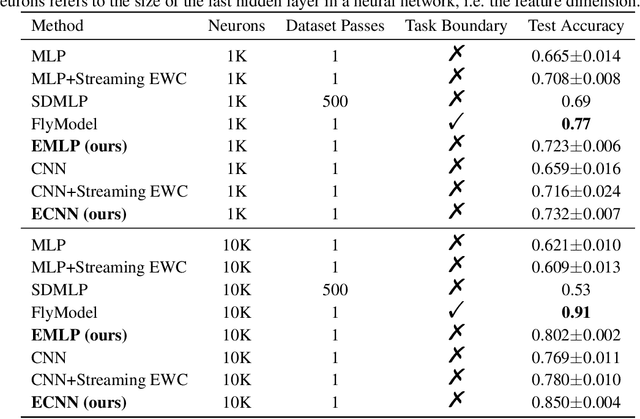
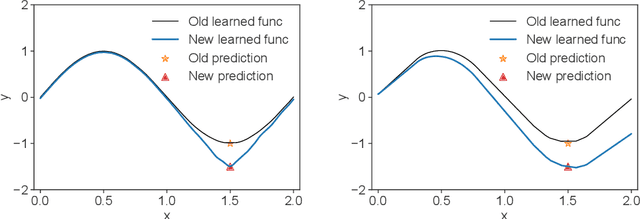
Catastrophic forgetting remains a significant challenge to continual learning for decades. While recent works have proposed effective methods to mitigate this problem, they mainly focus on the algorithmic side. Meanwhile, we do not fully understand what architectural properties of neural networks lead to catastrophic forgetting. This study aims to fill this gap by studying the role of activation functions in the training dynamics of neural networks and their impact on catastrophic forgetting. Our study reveals that, besides sparse representations, the gradient sparsity of activation functions also plays an important role in reducing forgetting. Based on this insight, we propose a new class of activation functions, elephant activation functions, that can generate both sparse representations and sparse gradients. We show that by simply replacing classical activation functions with elephant activation functions, we can significantly improve the resilience of neural networks to catastrophic forgetting. Our method has broad applicability and benefits for continual learning in regression, class incremental learning, and reinforcement learning tasks. Specifically, we achieves excellent performance on Split MNIST dataset in just one single pass, without using replay buffer, task boundary information, or pre-training.