 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Preference Optimization via Maximum Marginal Likelihood Estimation
Oct 27, 2025Aligning Large Language Models (LLMs) with human preferences is crucial, but standard methods like Reinforcement Learning from Human Feedback (RLHF) are often complex and unstable. In this work, we propose a new, simpler approach that recasts alignment through the lens of Maximum Marginal Likelihood (MML) estimation. Our new MML based Preference Optimization (MMPO) maximizes the marginal log-likelihood of a preferred text output, using the preference pair as samples for approximation, and forgoes the need for both an explicit reward model and entropy maximization. We theoretically demonstrate that MMPO implicitly performs preference optimization, producing a weighted gradient that naturally up-weights chosen responses over rejected ones. Across models ranging from 135M to 8B parameters, we empirically show that MMPO: 1) is more stable with respect to the hyperparameter $\beta$ compared to alternative baselines, and 2) achieves competitive or superior preference alignment while better preserving the base model's general language capabilities. Through a series of ablation experiments, we show that this improved performance is indeed attributable to MMPO's implicit preference optimization within the gradient updates.
Exploring Curriculum Learning for Vision-Language Tasks: A Study on Small-Scale Multimodal Training
Oct 20, 2024For specialized domains, there is often not a wealth of data with which to train large machine learning models. In such limited data / compute settings, various methods exist aiming to $\textit{do more with less}$, such as finetuning from a pretrained model, modulating difficulty levels as data are presented to a model (curriculum learning), and considering the role of model type / size. Approaches to efficient $\textit{machine}$ learning also take inspiration from $\textit{human}$ learning by considering use cases where machine learning systems have access to approximately the same number of words experienced by a 13 year old child (100M words). We investigate the role of 3 primary variables in a limited data regime as part of the multimodal track of the BabyLM challenge. We contrast: (i) curriculum learning, (ii), pretraining (with text-only data), (iii) model type. We modulate these variables and assess them on two types of tasks: (a) multimodal (text+image), and (b) unimodal (text-only) tasks. We find that curriculum learning benefits multimodal evaluations over non-curriclum learning models, particularly when combining text-only pretraining. On text-only tasks, curriculum learning appears to help models with smaller trainable parameter counts. We suggest possible reasons based on architectural differences and training designs as to why one might observe such results.
It's Not a Modality Gap: Characterizing and Addressing the Contrastive Gap
Jun 06, 2024



Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
Its Not a Modality Gap: Characterizing and Addressing the Contrastive Gap
May 28, 2024Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
What's the Opposite of a Face? Finding Shared Decodable Concepts and their Negations in the Brain
May 27, 2024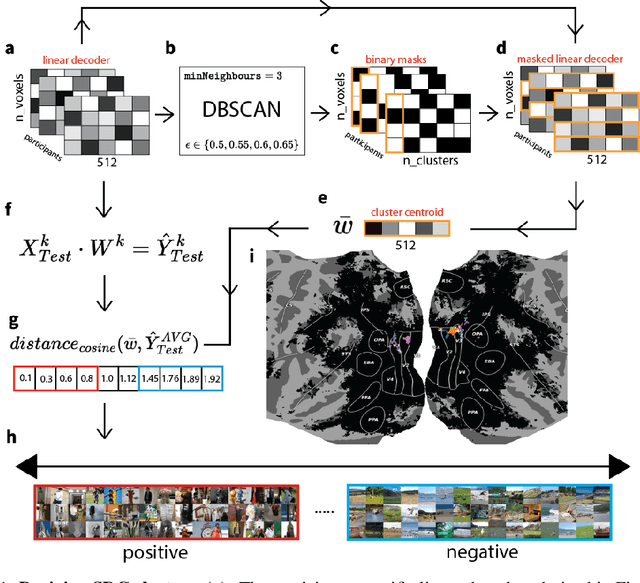
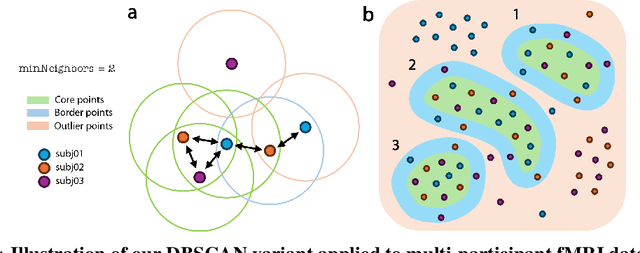
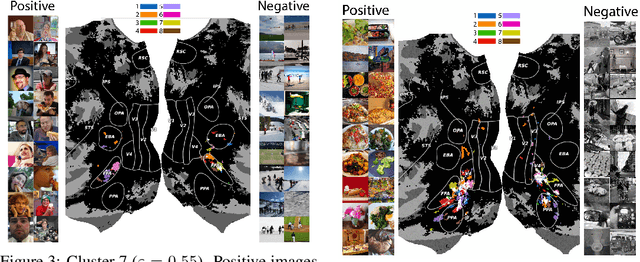

Prior work has offered evidence for functional localization in the brain; different anatomical regions preferentially activate for certain types of visual input. For example, the fusiform face area preferentially activates for visual stimuli that include a face. However, the spectrum of visual semantics is extensive, and only a few semantically-tuned patches of cortex have so far been identified in the human brain. Using a multimodal (natural language and image) neural network architecture (CLIP) we train a highly accurate contrastive model that maps brain responses during naturalistic image viewing to CLIP embeddings. We then use a novel adaptation of the DBSCAN clustering algorithm to cluster the parameters of these participant-specific contrastive models. This reveals what we call Shared Decodable Concepts (SDCs): clusters in CLIP space that are decodable from common sets of voxels across multiple participants. Examining the images most and least associated with each SDC cluster gives us additional insight into the semantic properties of each SDC. We note SDCs for previously reported visual features (e.g. orientation tuning in early visual cortex) as well as visual semantic concepts such as faces, places and bodies. In cases where our method finds multiple clusters for a visuo-semantic concept, the least associated images allow us to dissociate between confounding factors. For example, we discovered two clusters of food images, one driven by color, the other by shape. We also uncover previously unreported areas such as regions of extrastriate body area (EBA) tuned for legs/hands and sensitivity to numerosity in right intraparietal sulcus, and more. Thus, our contrastive-learning methodology better characterizes new and existing visuo-semantic representations in the brain by leveraging multimodal neural network representations and a novel adaptation of clustering algorithms.
Correcting Biased Centered Kernel Alignment Measures in Biological and Artificial Neural Networks
May 02, 2024



Centred Kernel Alignment (CKA) has recently emerged as a popular metric to compare activations from biological and artificial neural networks (ANNs) in order to quantify the alignment between internal representations derived from stimuli sets (e.g. images, text, video) that are presented to both systems. In this paper we highlight issues that the community should take into account if using CKA as an alignment metric with neural data. Neural data are in the low-data high-dimensionality domain, which is one of the cases where (biased) CKA results in high similarity scores even for pairs of random matrices. Using fMRI and MEG data from the THINGS project, we show that if biased CKA is applied to representations of different sizes in the low-data high-dimensionality domain, they are not directly comparable due to biased CKA's sensitivity to differing feature-sample ratios and not stimuli-driven responses. This situation can arise both when comparing a pre-selected area of interest (e.g. ROI) to multiple ANN layers, as well as when determining to which ANN layer multiple regions of interest (ROIs) / sensor groups of different dimensionality are most similar. We show that biased CKA can be artificially driven to its maximum value when using independent random data of different sample-feature ratios. We further show that shuffling sample-feature pairs of real neural data does not drastically alter biased CKA similarity in comparison to unshuffled data, indicating an undesirable lack of sensitivity to stimuli-driven neural responses. Positive alignment of true stimuli-driven responses is only achieved by using debiased CKA. Lastly, we report findings that suggest biased CKA is sensitive to the inherent structure of neural data, only differing from shuffled data when debiased CKA detects stimuli-driven alignment.
RIFF: Learning to Rephrase Inputs for Few-shot Fine-tuning of Language Models
Mar 04, 2024
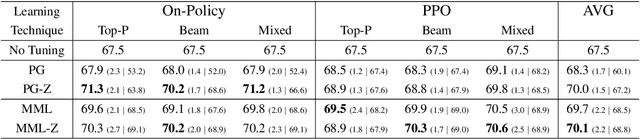

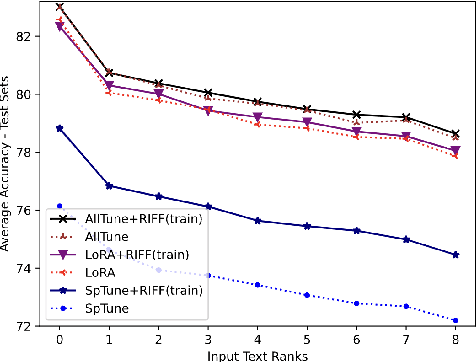
Pre-trained Language Models (PLMs) can be accurately fine-tuned for downstream text processing tasks. Recently, researchers have introduced several parameter-efficient fine-tuning methods that optimize input prompts or adjust a small number of model parameters (e.g LoRA). In this study, we explore the impact of altering the input text of the original task in conjunction with parameter-efficient fine-tuning methods. To most effectively rewrite the input text, we train a few-shot paraphrase model with a Maximum-Marginal Likelihood objective. Using six few-shot text classification datasets, we show that enriching data with paraphrases at train and test time enhances the performance beyond what can be achieved with parameter-efficient fine-tuning alone.
Language and Mental Health: Measures of Emotion Dynamics from Text as Linguistic Biosocial Markers
Nov 04, 2023



Research in psychopathology has shown that, at an aggregate level, the patterns of emotional change over time -- emotion dynamics -- are indicators of one's mental health. One's patterns of emotion change have traditionally been determined through self-reports of emotions; however, there are known issues with accuracy, bias, and ease of data collection. Recent approaches to determining emotion dynamics from one's everyday utterances addresses many of these concerns, but it is not yet known whether these measures of utterance emotion dynamics (UED) correlate with mental health diagnoses. Here, for the first time, we study the relationship between tweet emotion dynamics and mental health disorders. We find that each of the UED metrics studied varied by the user's self-disclosed diagnosis. For example: average valence was significantly higher (i.e., more positive text) in the control group compared to users with ADHD, MDD, and PTSD. Valence variability was significantly lower in the control group compared to ADHD, depression, bipolar disorder, MDD, PTSD, and OCD but not PPD. Rise and recovery rates of valence also exhibited significant differences from the control. This work provides important early evidence for how linguistic cues pertaining to emotion dynamics can play a crucial role as biosocial markers for mental illnesses and aid in the understanding, diagnosis, and management of mental health disorders.
Better Handling Coreference Resolution in Aspect Level Sentiment Classification by Fine-Tuning Language Models
Jul 11, 2023Customer feedback is invaluable to companies as they refine their products. Monitoring customer feedback can be automated with Aspect Level Sentiment Classification (ALSC) which allows us to analyse specific aspects of the products in reviews. Large Language Models (LLMs) are the heart of many state-of-the-art ALSC solutions, but they perform poorly in some scenarios requiring Coreference Resolution (CR). In this work, we propose a framework to improve an LLM's performance on CR-containing reviews by fine tuning on highly inferential tasks. We show that the performance improvement is likely attributed to the improved model CR ability. We also release a new dataset that focuses on CR in ALSC.
Utterance Emotion Dynamics in Children's Poems: Emotional Changes Across Age
Jun 08, 2023



Emerging psychopathology studies are showing that patterns of changes in emotional state -- emotion dynamics -- are associated with overall well-being and mental health. More recently, there has been some work in tracking emotion dynamics through one's utterances, allowing for data to be collected on a larger scale across time and people. However, several questions about how emotion dynamics change with age, especially in children, and when determined through children's writing, remain unanswered. In this work, we use both a lexicon and a machine learning based approach to quantify characteristics of emotion dynamics determined from poems written by children of various ages. We show that both approaches point to similar trends: consistent increasing intensities for some emotions (e.g., anger, fear, joy, sadness, arousal, and dominance) with age and a consistent decreasing valence with age. We also find increasing emotional variability, rise rates (i.e., emotional reactivity), and recovery rates (i.e., emotional regulation) with age. These results act as a useful baselines for further research in how patterns of emotions expressed by children change with age, and their association with mental health.