 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Approaches to Malware Detection: A Study of Machine Learning and Deep Learning Techniques
Apr 24, 2025Digital systems find it challenging to keep up with cybersecurity threats. The daily emergence of more than 560,000 new malware strains poses significant hazards to the digital ecosystem. The traditional malware detection methods fail to operate properly and yield high false positive rates with low accuracy of the protection system. This study explores the ways in which malware can be detected using these machine learning (ML) and deep learning (DL) approaches to address those shortcomings. This study also includes a systematic comparison of the performance of some of the widely used ML models, such as random forest, multi-layer perceptron (MLP), and deep neural network (DNN), for determining the effectiveness of the domain of modern malware threat systems. We use a considerable-sized database from Kaggle, which has undergone optimized feature selection and preprocessing to improve model performance. Our finding suggests that the DNN model outperformed the other traditional models with the highest training accuracy of 99.92% and an almost perfect AUC score. Furthermore, the feature selection and preprocessing can help improve the capabilities of detection. This research makes an important contribution by analyzing the performance of the model on the performance metrics and providing insight into the effectiveness of the advanced detection techniques to build more robust and more reliable cybersecurity solutions against the growing malware threats.
* 9 pages
Exploring Curriculum Learning for Vision-Language Tasks: A Study on Small-Scale Multimodal Training
Oct 20, 2024For specialized domains, there is often not a wealth of data with which to train large machine learning models. In such limited data / compute settings, various methods exist aiming to $\textit{do more with less}$, such as finetuning from a pretrained model, modulating difficulty levels as data are presented to a model (curriculum learning), and considering the role of model type / size. Approaches to efficient $\textit{machine}$ learning also take inspiration from $\textit{human}$ learning by considering use cases where machine learning systems have access to approximately the same number of words experienced by a 13 year old child (100M words). We investigate the role of 3 primary variables in a limited data regime as part of the multimodal track of the BabyLM challenge. We contrast: (i) curriculum learning, (ii), pretraining (with text-only data), (iii) model type. We modulate these variables and assess them on two types of tasks: (a) multimodal (text+image), and (b) unimodal (text-only) tasks. We find that curriculum learning benefits multimodal evaluations over non-curriclum learning models, particularly when combining text-only pretraining. On text-only tasks, curriculum learning appears to help models with smaller trainable parameter counts. We suggest possible reasons based on architectural differences and training designs as to why one might observe such results.
It's Not a Modality Gap: Characterizing and Addressing the Contrastive Gap
Jun 06, 2024



Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
Its Not a Modality Gap: Characterizing and Addressing the Contrastive Gap
May 28, 2024Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
Unsupervised Space Partitioning for Nearest Neighbor Search
Jun 16, 2022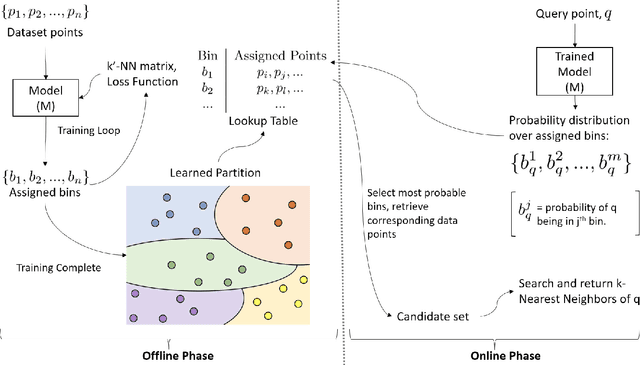


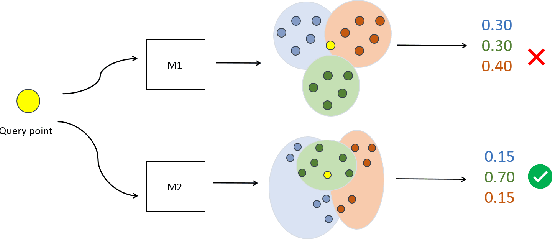
Approximate Nearest Neighbor Search (ANNS) in high dimensional spaces is crucial for many real-life applications (e.g., e-commerce, web, multimedia, etc.) dealing with an abundance of data. In this paper, we propose an end-to-end learning framework that couples the partitioning (one key step of ANNS) and learning-to-search steps using a custom loss function. A key advantage of our proposed solution is that it does not require any expensive pre-processing of the dataset, which is one of the key limitations of the state-of-the-art approach. We achieve the above edge by formulating a multi-objective custom loss function that does not need ground truth labels to quantify the quality of a given partition of the data space, making it entirely unsupervised. We also propose an ensembling technique by adding varying input weights to the loss function to train an ensemble of models to enhance the search quality. On several standard benchmarks for ANNS, we show that our method beats the state-of-the-art space partitioning method and the ubiquitous K-means clustering method while using fewer parameters and shorter offline training times. Without loss of generality, our unsupervised partitioning approach is shown as a promising alternative to many widely used clustering methods like K-means clustering and DBSCAN.