 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiaLab: Can Vision-Language Models Perform Spatial Reasoning in the Wild?
Feb 03, 2026Spatial reasoning is a fundamental aspect of human cognition, yet it remains a major challenge for contemporary vision-language models (VLMs). Prior work largely relied on synthetic or LLM-generated environments with limited task designs and puzzle-like setups, failing to capture the real-world complexity, visual noise, and diverse spatial relationships that VLMs encounter. To address this, we introduce SpatiaLab, a comprehensive benchmark for evaluating VLMs' spatial reasoning in realistic, unconstrained contexts. SpatiaLab comprises 1,400 visual question-answer pairs across six major categories: Relative Positioning, Depth & Occlusion, Orientation, Size & Scale, Spatial Navigation, and 3D Geometry, each with five subcategories, yielding 30 distinct task types. Each subcategory contains at least 25 questions, and each main category includes at least 200 questions, supporting both multiple-choice and open-ended evaluation. Experiments across diverse state-of-the-art VLMs, including open- and closed-source models, reasoning-focused, and specialized spatial reasoning models, reveal a substantial gap in spatial reasoning capabilities compared with humans. In the multiple-choice setup, InternVL3.5-72B achieves 54.93% accuracy versus 87.57% for humans. In the open-ended setting, all models show a performance drop of around 10-25%, with GPT-5-mini scoring highest at 40.93% versus 64.93% for humans. These results highlight key limitations in handling complex spatial relationships, depth perception, navigation, and 3D geometry. By providing a diverse, real-world evaluation framework, SpatiaLab exposes critical challenges and opportunities for advancing VLMs' spatial reasoning, offering a benchmark to guide future research toward robust, human-aligned spatial understanding. SpatiaLab is available at: https://spatialab-reasoning.github.io/.
WebOperator: Action-Aware Tree Search for Autonomous Agents in Web Environment
Dec 14, 2025LLM-based agents often operate in a greedy, step-by-step manner, selecting actions solely based on the current observation without considering long-term consequences or alternative paths. This lack of foresight is particularly problematic in web environments, which are only partially observable-limited to browser-visible content (e.g., DOM and UI elements)-where a single misstep often requires complex and brittle navigation to undo. Without an explicit backtracking mechanism, agents struggle to correct errors or systematically explore alternative paths. Tree-search methods provide a principled framework for such structured exploration, but existing approaches lack mechanisms for safe backtracking, making them prone to unintended side effects. They also assume that all actions are reversible, ignoring the presence of irreversible actions-limitations that reduce their effectiveness in realistic web tasks. To address these challenges, we introduce WebOperator, a tree-search framework that enables reliable backtracking and strategic exploration. Our method incorporates a best-first search strategy that ranks actions by both reward estimates and safety considerations, along with a robust backtracking mechanism that verifies the feasibility of previously visited paths before replaying them, preventing unintended side effects. To further guide exploration, WebOperator generates action candidates from multiple, varied reasoning contexts to ensure diverse and robust exploration, and subsequently curates a high-quality action set by filtering out invalid actions pre-execution and merging semantically equivalent ones. Experimental results on WebArena and WebVoyager demonstrate the effectiveness of WebOperator. On WebArena, WebOperator achieves a state-of-the-art 54.6% success rate with gpt-4o, underscoring the critical advantage of integrating strategic foresight with safe execution.
CODESIM: Multi-Agent Code Generation and Problem Solving through Simulation-Driven Planning and Debugging
Feb 08, 2025Large Language Models (LLMs) have made significant strides in code generation and problem solving. Current approaches employ external tool-based iterative debuggers that use compiler or other tool-based runtime feedback to refine coarse programs generated by various methods. However, the effectiveness of these approaches heavily relies on the quality of the initial code generation, which remains an open challenge. In this paper, we introduce CodeSim, a novel multi-agent code generation framework that comprehensively addresses the stages of program synthesis-planning, coding, and debugging-through a human-like perception approach. As human verifies their understanding of any algorithms through visual simulation, CodeSim uniquely features a method of plan verification and internal debugging through the step-by-step simulation of input/output. Extensive experiments across seven challenging competitive problem-solving and program synthesis benchmarks demonstrate CodeSim's remarkable code generation capabilities. Our framework achieves new state-of-the-art (pass@1) results-(HumanEval 95.1%, MBPP 90.7%, APPS 22%, and CodeContests 29.1%). Furthermore, our method shows potential for even greater enhancement when cascaded with external debuggers. To facilitate further research and development in this area, we have open-sourced our framework in this link (https://kagnlp.github.io/codesim.github.io/).
MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models
Dec 31, 2024



Recent advancements in foundation models have enhanced AI systems' capabilities in autonomous tool usage and reasoning. However, their ability in location or map-based reasoning - which improves daily life by optimizing navigation, facilitating resource discovery, and streamlining logistics - has not been systematically studied. To bridge this gap, we introduce MapEval, a benchmark designed to assess diverse and complex map-based user queries with geo-spatial reasoning. MapEval features three task types (textual, API-based, and visual) that require collecting world information via map tools, processing heterogeneous geo-spatial contexts (e.g., named entities, travel distances, user reviews or ratings, images), and compositional reasoning, which all state-of-the-art foundation models find challenging. Comprising 700 unique multiple-choice questions about locations across 180 cities and 54 countries, MapEval evaluates foundation models' ability to handle spatial relationships, map infographics, travel planning, and navigation challenges. Using MapEval, we conducted a comprehensive evaluation of 28 prominent foundation models. While no single model excelled across all tasks, Claude-3.5-Sonnet, GPT-4o, and Gemini-1.5-Pro achieved competitive performance overall. However, substantial performance gaps emerged, particularly in MapEval, where agents with Claude-3.5-Sonnet outperformed GPT-4o and Gemini-1.5-Pro by 16% and 21%, respectively, and the gaps became even more amplified when compared to open-source LLMs. Our detailed analyses provide insights into the strengths and weaknesses of current models, though all models still fall short of human performance by more than 20% on average, struggling with complex map images and rigorous geo-spatial reasoning. This gap highlights MapEval's critical role in advancing general-purpose foundation models with stronger geo-spatial understanding.
MapQaTor: A System for Efficient Annotation of Map Query Datasets
Dec 30, 2024Mapping and navigation services like Google Maps, Apple Maps, Openstreet Maps, are essential for accessing various location-based data, yet they often struggle to handle natural language geospatial queries. Recent advancements in Large Language Models (LLMs) show promise in question answering (QA), but creating reliable geospatial QA datasets from map services remains challenging. We introduce MapQaTor, a web application that streamlines the creation of reproducible, traceable map-based QA datasets. With its plug-and-play architecture, MapQaTor enables seamless integration with any maps API, allowing users to gather and visualize data from diverse sources with minimal setup. By caching API responses, the platform ensures consistent ground truth, enhancing the reliability of the data even as real-world information evolves. MapQaTor centralizes data retrieval, annotation, and visualization within a single platform, offering a unique opportunity to evaluate the current state of LLM-based geospatial reasoning while advancing their capabilities for improved geospatial understanding. Evaluation metrics show that, MapQaTor speeds up the annotation process by at least 30 times compared to manual methods, underscoring its potential for developing geospatial resources, such as complex map reasoning datasets. The website is live at: https://mapqator.github.io/ and a demo video is available at: https://youtu.be/7_aV9Wmhs6Q.
A Multi-Modal Deep Learning Based Approach for House Price Prediction
Sep 09, 2024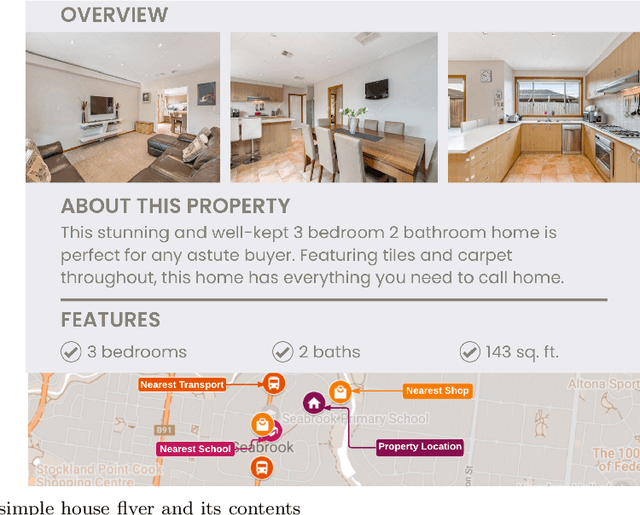

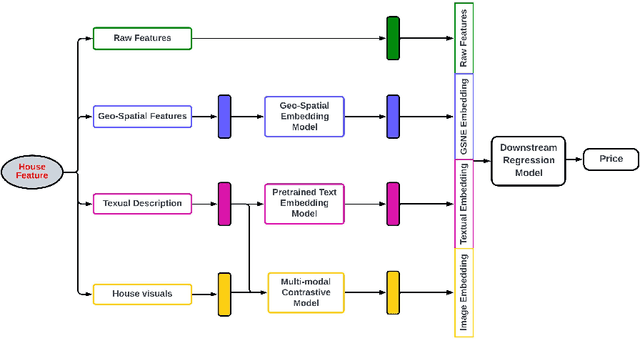

Accurate prediction of house price, a vital aspect of the residential real estate sector, is of substantial interest for a wide range of stakeholders. However, predicting house prices is a complex task due to the significant variability influenced by factors such as house features, location, neighborhood, and many others. Despite numerous attempts utilizing a wide array of algorithms, including recent deep learning techniques, to predict house prices accurately, existing approaches have fallen short of considering a wide range of factors such as textual and visual features. This paper addresses this gap by comprehensively incorporating attributes, such as features, textual descriptions, geo-spatial neighborhood, and house images, typically showcased in real estate listings in a house price prediction system. Specifically, we propose a multi-modal deep learning approach that leverages different types of data to learn more accurate representation of the house. In particular, we learn a joint embedding of raw house attributes, geo-spatial neighborhood, and most importantly from textual description and images representing the house; and finally use a downstream regression model to predict the house price from this jointly learned embedding vector. Our experimental results with a real-world dataset show that the text embedding of the house advertisement description and image embedding of the house pictures in addition to raw attributes and geo-spatial embedding, can significantly improve the house price prediction accuracy. The relevant source code and dataset are publicly accessible at the following URL: https://github.com/4P0N/mhpp
Generating Faithful and Salient Text from Multimodal Data
Sep 06, 2024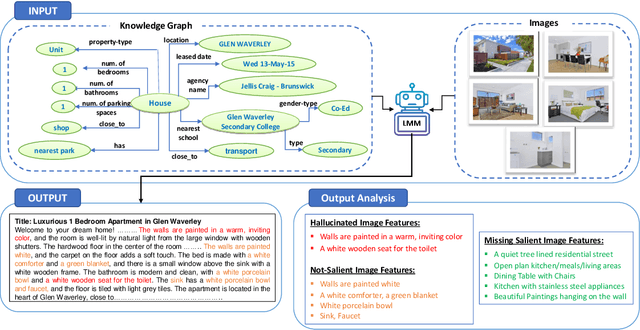

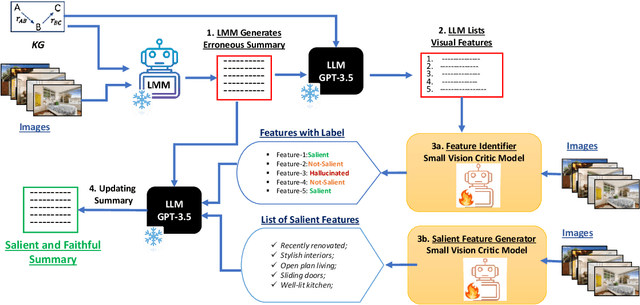
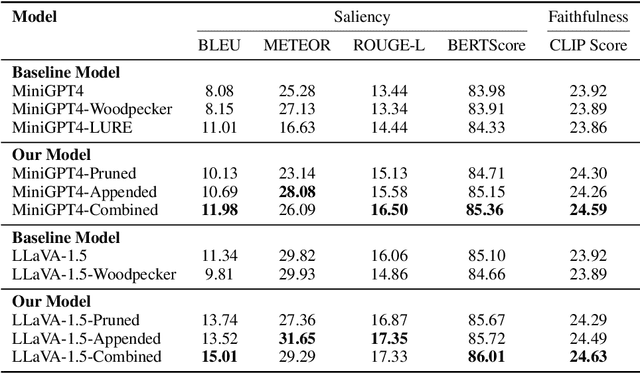
While large multimodal models (LMMs) have obtained strong performance on many multimodal tasks, they may still hallucinate while generating text. Their performance on detecting salient features from visual data is also unclear. In this paper, we develop a framework to generate faithful and salient text from mixed-modal data, which includes images and structured data ( represented in knowledge graphs or tables). Specifically, we train a small vision critic model to identify hallucinated and non-salient features from the image modality. The critic model also generates a list of salient image features. This information is used in the post editing step to improve the generation quality. Experiments on two datasets show that our framework improves LMMs' generation quality on both faithfulness and saliency, outperforming recent techniques aimed at reducing hallucination.
MapCoder: Multi-Agent Code Generation for Competitive Problem Solving
May 18, 2024



Code synthesis, which requires a deep understanding of complex natural language problem descriptions, generation of code instructions for complex algorithms and data structures, and the successful execution of comprehensive unit tests, presents a significant challenge. While large language models (LLMs) demonstrate impressive proficiency in natural language processing, their performance in code generation tasks remains limited. In this paper, we introduce a new approach to code generation tasks leveraging multi-agent prompting that uniquely replicates the full cycle of program synthesis as observed in human developers. Our framework, MapCoder, consists of four LLM agents specifically designed to emulate the stages of this cycle: recalling relevant examples, planning, code generation, and debugging. After conducting thorough experiments, with multiple LLM ablations and analyses across eight challenging competitive problem-solving and program synthesis benchmarks, MapCoder showcases remarkable code generation capabilities, achieving new state-of-the-art results (pass@1) on HumanEval (93.9%), MBPP (83.1%), APPS (22.0%), CodeContests (28.5%), and xCodeEval (45.3%). Moreover, our method consistently delivers superior performance across various programming languages and varying problem difficulties. We open-source our framework at https://github.com/Md-Ashraful-Pramanik/MapCoder.
Towards Detecting, Recognizing, and Parsing the Address Information from Bangla Signboard: A Deep Learning-based Approach
Nov 22, 2023



Retrieving textual information from natural scene images is an active research area in the field of computer vision with numerous practical applications. Detecting text regions and extracting text from signboards is a challenging problem due to special characteristics like reflecting lights, uneven illumination, or shadows found in real-life natural scene images. With the advent of deep learning-based methods, different sophisticated techniques have been proposed for text detection and text recognition from the natural scene. Though a significant amount of effort has been devoted to extracting natural scene text for resourceful languages like English, little has been done for low-resource languages like Bangla. In this research work, we have proposed an end-to-end system with deep learning-based models for efficiently detecting, recognizing, correcting, and parsing address information from Bangla signboards. We have created manually annotated datasets and synthetic datasets to train signboard detection, address text detection, address text recognition, address text correction, and address text parser models. We have conducted a comparative study among different CTC-based and Encoder-Decoder model architectures for Bangla address text recognition. Moreover, we have designed a novel address text correction model using a sequence-to-sequence transformer-based network to improve the performance of Bangla address text recognition model by post-correction. Finally, we have developed a Bangla address text parser using the state-of-the-art transformer-based pre-trained language model.
Understanding Social Structures from Contemporary Literary Fiction using Character Interaction Graph -- Half Century Chronology of Influential Bengali Writers
Oct 25, 2023



Social structures and real-world incidents often influence contemporary literary fiction. Existing research in literary fiction analysis explains these real-world phenomena through the manual critical analysis of stories. Conventional Natural Language Processing (NLP) methodologies, including sentiment analysis, narrative summarization, and topic modeling, have demonstrated substantial efficacy in analyzing and identifying similarities within fictional works. However, the intricate dynamics of character interactions within fiction necessitate a more nuanced approach that incorporates visualization techniques. Character interaction graphs (or networks) emerge as a highly suitable means for visualization and information retrieval from the realm of fiction. Therefore, we leverage character interaction graphs with NLP-derived features to explore a diverse spectrum of societal inquiries about contemporary culture's impact on the landscape of literary fiction. Our study involves constructing character interaction graphs from fiction, extracting relevant graph features, and exploiting these features to resolve various real-life queries. Experimental evaluation of influential Bengali fiction over half a century demonstrates that character interaction graphs can be highly effective in specific assessments and information retrieval from literary fiction. Our data and codebase are available at https://cutt.ly/fbMgGEM