 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Faithful and Salient Text from Multimodal Data
Paper and Code
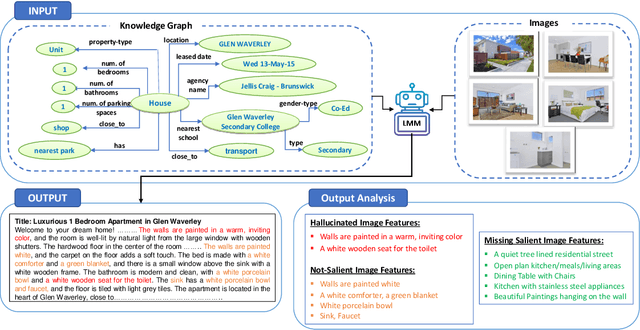

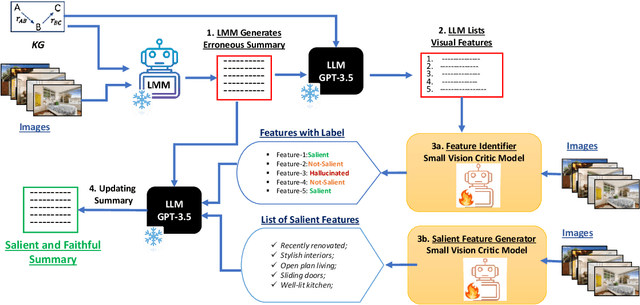
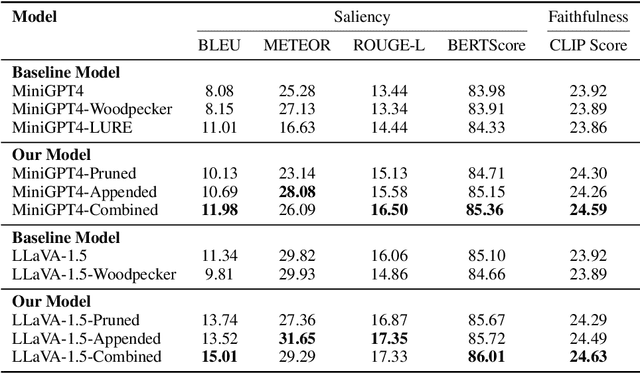
While large multimodal models (LMMs) have obtained strong performance on many multimodal tasks, they may still hallucinate while generating text. Their performance on detecting salient features from visual data is also unclear. In this paper, we develop a framework to generate faithful and salient text from mixed-modal data, which includes images and structured data ( represented in knowledge graphs or tables). Specifically, we train a small vision critic model to identify hallucinated and non-salient features from the image modality. The critic model also generates a list of salient image features. This information is used in the post editing step to improve the generation quality. Experiments on two datasets show that our framework improves LMMs' generation quality on both faithfulness and saliency, outperforming recent techniques aimed at reducing hallucination.