 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Faithful and Salient Text from Multimodal Data
Sep 06, 2024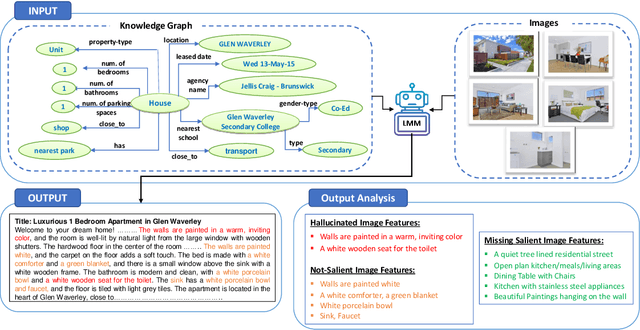

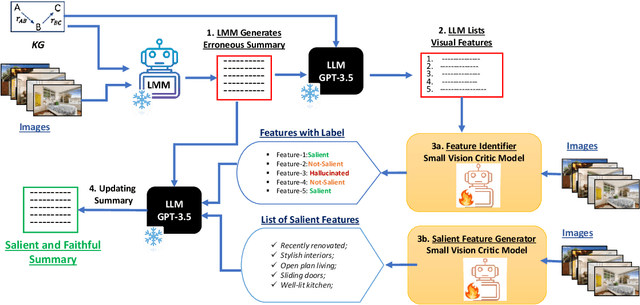
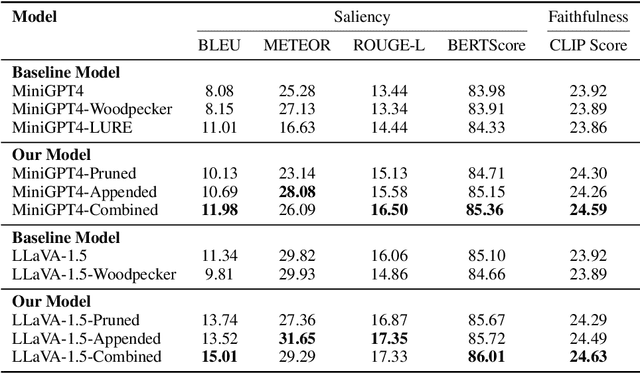
While large multimodal models (LMMs) have obtained strong performance on many multimodal tasks, they may still hallucinate while generating text. Their performance on detecting salient features from visual data is also unclear. In this paper, we develop a framework to generate faithful and salient text from mixed-modal data, which includes images and structured data ( represented in knowledge graphs or tables). Specifically, we train a small vision critic model to identify hallucinated and non-salient features from the image modality. The critic model also generates a list of salient image features. This information is used in the post editing step to improve the generation quality. Experiments on two datasets show that our framework improves LMMs' generation quality on both faithfulness and saliency, outperforming recent techniques aimed at reducing hallucination.
Generating Faithful Text From a Knowledge Graph with Noisy Reference Text
Aug 12, 2023Knowledge Graph (KG)-to-Text generation aims at generating fluent natural-language text that accurately represents the information of a given knowledge graph. While significant progress has been made in this task by exploiting the power of pre-trained language models (PLMs) with appropriate graph structure-aware modules, existing models still fall short of generating faithful text, especially when the ground-truth natural-language text contains additional information that is not present in the graph. In this paper, we develop a KG-to-text generation model that can generate faithful natural-language text from a given graph, in the presence of noisy reference text. Our framework incorporates two core ideas: Firstly, we utilize contrastive learning to enhance the model's ability to differentiate between faithful and hallucinated information in the text, thereby encouraging the decoder to generate text that aligns with the input graph. Secondly, we empower the decoder to control the level of hallucination in the generated text by employing a controllable text generation technique. We evaluate our model's performance through the standard quantitative metrics as well as a ChatGPT-based quantitative and qualitative analysis. Our evaluation demonstrates the superior performance of our model over state-of-the-art KG-to-text models on faithfulness.