 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Detecting, Recognizing, and Parsing the Address Information from Bangla Signboard: A Deep Learning-based Approach
Nov 22, 2023



Retrieving textual information from natural scene images is an active research area in the field of computer vision with numerous practical applications. Detecting text regions and extracting text from signboards is a challenging problem due to special characteristics like reflecting lights, uneven illumination, or shadows found in real-life natural scene images. With the advent of deep learning-based methods, different sophisticated techniques have been proposed for text detection and text recognition from the natural scene. Though a significant amount of effort has been devoted to extracting natural scene text for resourceful languages like English, little has been done for low-resource languages like Bangla. In this research work, we have proposed an end-to-end system with deep learning-based models for efficiently detecting, recognizing, correcting, and parsing address information from Bangla signboards. We have created manually annotated datasets and synthetic datasets to train signboard detection, address text detection, address text recognition, address text correction, and address text parser models. We have conducted a comparative study among different CTC-based and Encoder-Decoder model architectures for Bangla address text recognition. Moreover, we have designed a novel address text correction model using a sequence-to-sequence transformer-based network to improve the performance of Bangla address text recognition model by post-correction. Finally, we have developed a Bangla address text parser using the state-of-the-art transformer-based pre-trained language model.
BDSL 49: A Comprehensive Dataset of Bangla Sign Language
Aug 14, 2022
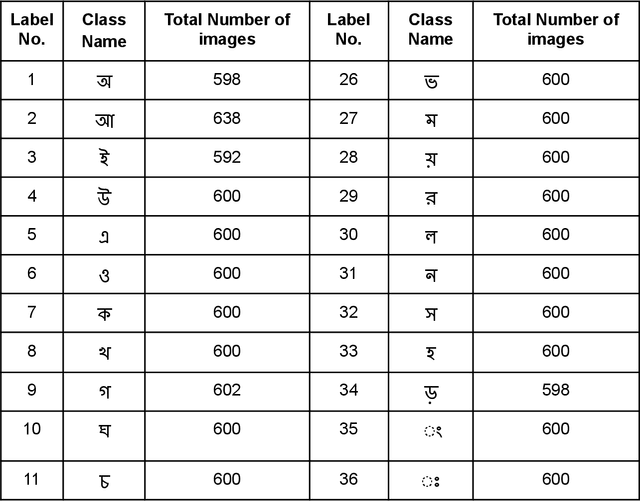


Language is a method by which individuals express their thoughts. Each language has its own set of alphabetic and numeric characters. People can communicate with one another through either oral or written communication. However, each language has a sign language counterpart. Individuals who are deaf and/or mute communicate through sign language. The Bangla language also has a sign language, which is called BDSL. The dataset is about Bangla hand sign images. The collection contains 49 individual Bangla alphabet images in sign language. BDSL49 is a dataset that consists of 29,490 images with 49 labels. Images of 14 different adult individuals, each with a distinct background and appearance, have been recorded during data collection. Several strategies have been used to eliminate noise from datasets during preparation. This dataset is available to researchers for free. They can develop automated systems using machine learning, computer vision, and deep learning techniques. In addition, two models were used in this dataset. The first is for detection, while the second is for recognition.