 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Deep Learning Based Approach for House Price Prediction
Sep 09, 2024

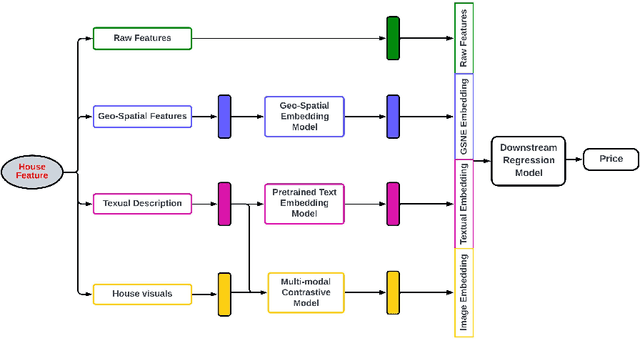

Accurate prediction of house price, a vital aspect of the residential real estate sector, is of substantial interest for a wide range of stakeholders. However, predicting house prices is a complex task due to the significant variability influenced by factors such as house features, location, neighborhood, and many others. Despite numerous attempts utilizing a wide array of algorithms, including recent deep learning techniques, to predict house prices accurately, existing approaches have fallen short of considering a wide range of factors such as textual and visual features. This paper addresses this gap by comprehensively incorporating attributes, such as features, textual descriptions, geo-spatial neighborhood, and house images, typically showcased in real estate listings in a house price prediction system. Specifically, we propose a multi-modal deep learning approach that leverages different types of data to learn more accurate representation of the house. In particular, we learn a joint embedding of raw house attributes, geo-spatial neighborhood, and most importantly from textual description and images representing the house; and finally use a downstream regression model to predict the house price from this jointly learned embedding vector. Our experimental results with a real-world dataset show that the text embedding of the house advertisement description and image embedding of the house pictures in addition to raw attributes and geo-spatial embedding, can significantly improve the house price prediction accuracy. The relevant source code and dataset are publicly accessible at the following URL: https://github.com/4P0N/mhpp
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021
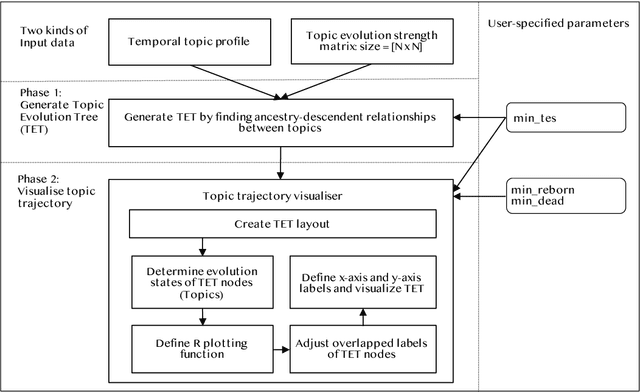
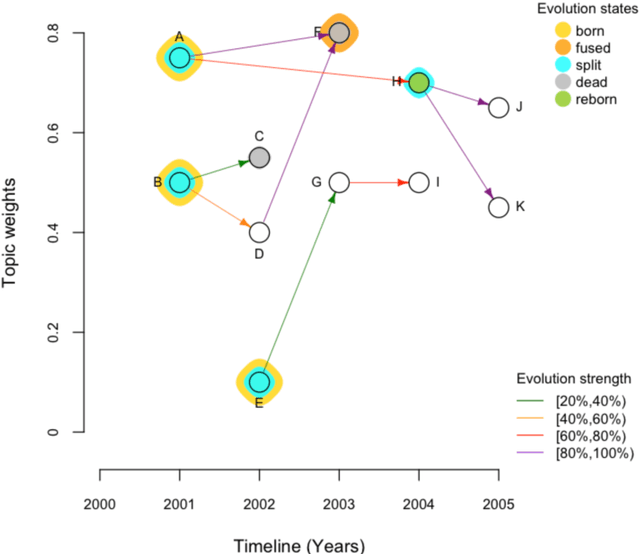
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
ExpFinder: An Ensemble Expert Finding Model Integrating $N$-gram Vector Space Model and $μ$CO-HITS
Jan 18, 2021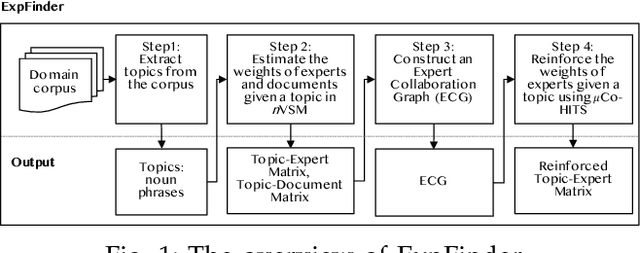
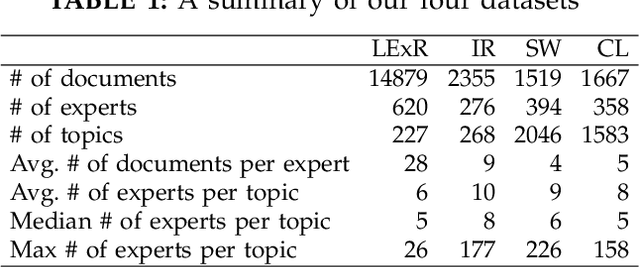
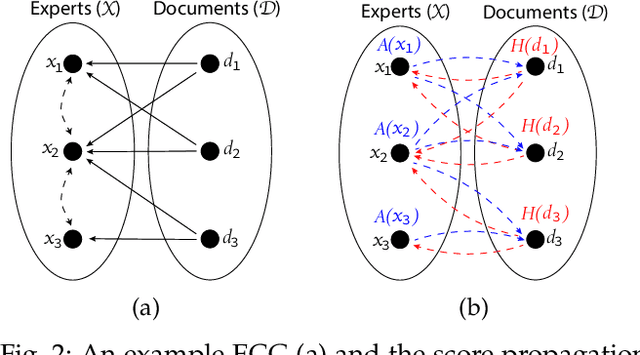

Finding an expert plays a crucial role in driving successful collaborations and speeding up high-quality research development and innovations. However, the rapid growth of scientific publications and digital expertise data makes identifying the right experts a challenging problem. Existing approaches for finding experts given a topic can be categorised into information retrieval techniques based on vector space models, document language models, and graph-based models. In this paper, we propose $\textit{ExpFinder}$, a new ensemble model for expert finding, that integrates a novel $N$-gram vector space model, denoted as $n$VSM, and a graph-based model, denoted as $\textit{$\mu$CO-HITS}$, that is a proposed variation of the CO-HITS algorithm. The key of $n$VSM is to exploit recent inverse document frequency weighting method for $N$-gram words and $\textit{ExpFinder}$ incorporates $n$VSM into $\textit{$\mu$CO-HITS}$ to achieve expert finding. We comprehensively evaluate $\textit{ExpFinder}$ on four different datasets from the academic domains in comparison with six different expert finding models. The evaluation results show that $\textit{ExpFinder}$ is a highly effective model for expert finding, substantially outperforming all the compared models in 19% to 160.2%.
Boosting House Price Predictions using Geo-Spatial Network Embedding
Sep 01, 2020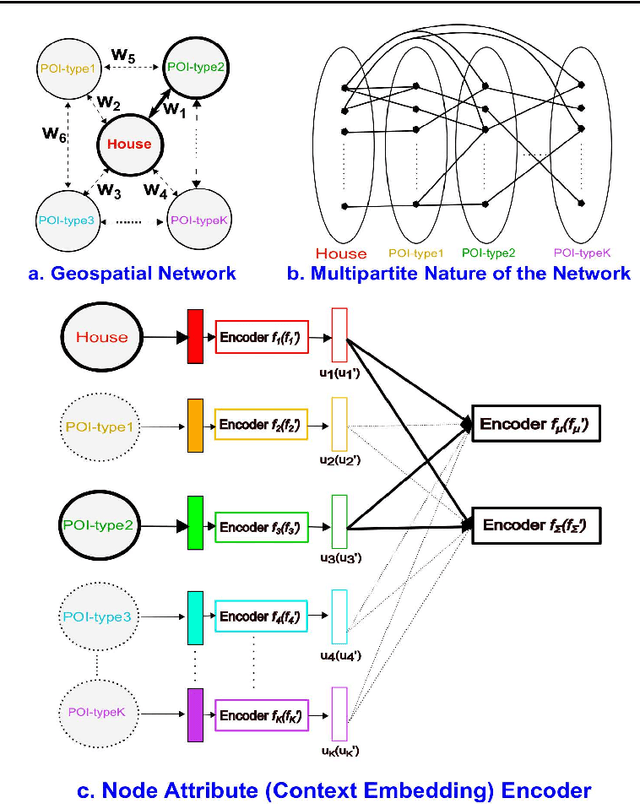

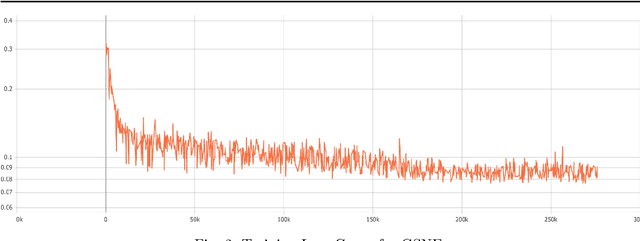
Real estate contributes significantly to all major economies around the world. In particular, house prices have a direct impact on stakeholders, ranging from house buyers to financing companies. Thus, a plethora of techniques have been developed for real estate price prediction. Most of the existing techniques rely on different house features to build a variety of prediction models to predict house prices. Perceiving the effect of spatial dependence on house prices, some later works focused on introducing spatial regression models for improving prediction performance. However, they fail to take into account the geo-spatial context of the neighborhood amenities such as how close a house is to a train station, or a highly-ranked school, or a shopping center. Such contextual information may play a vital role in users' interests in a house and thereby has a direct influence on its price. In this paper, we propose to leverage the concept of graph neural networks to capture the geo-spatial context of the neighborhood of a house. In particular, we present a novel method, the Geo-Spatial Network Embedding (GSNE), that learns the embeddings of houses and various types of Points of Interest (POIs) in the form of multipartite networks, where the houses and the POIs are represented as attributed nodes and the relationships between them as edges. Extensive experiments with a large number of regression techniques show that the embeddings produced by our proposed GSNE technique consistently and significantly improve the performance of the house price prediction task regardless of the downstream regression model.
A Novel DNN Training Framework via Data Sampling and Multi-Task Optimization
Jul 02, 2020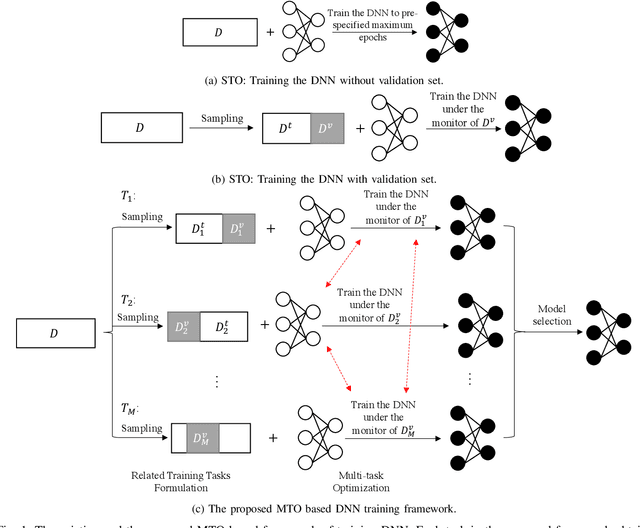
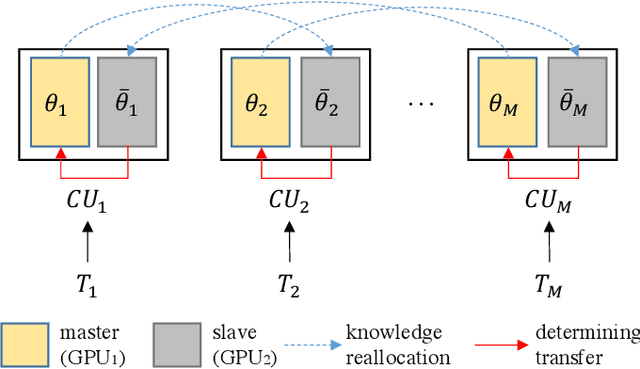
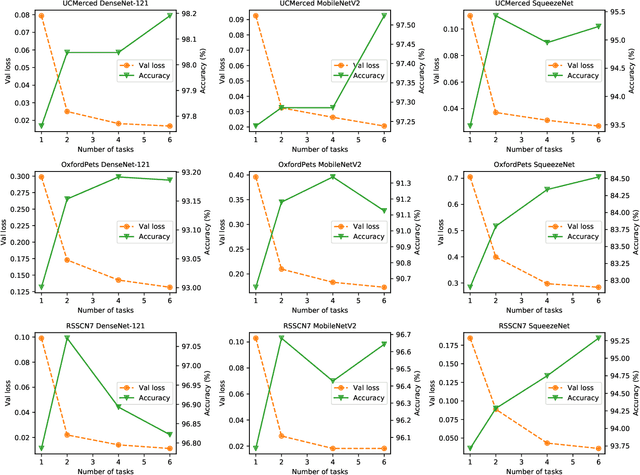
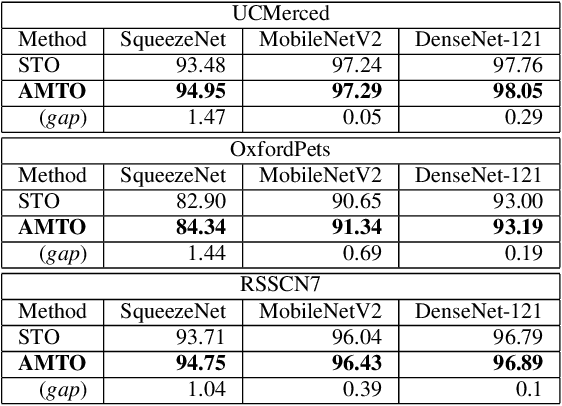
Conventional DNN training paradigms typically rely on one training set and one validation set, obtained by partitioning an annotated dataset used for training, namely gross training set, in a certain way. The training set is used for training the model while the validation set is used to estimate the generalization performance of the trained model as the training proceeds to avoid over-fitting. There exist two major issues in this paradigm. Firstly, the validation set may hardly guarantee an unbiased estimate of generalization performance due to potential mismatching with test data. Secondly, training a DNN corresponds to solve a complex optimization problem, which is prone to getting trapped into inferior local optima and thus leads to undesired training results. To address these issues, we propose a novel DNN training framework. It generates multiple pairs of training and validation sets from the gross training set via random splitting, trains a DNN model of a pre-specified structure on each pair while making the useful knowledge (e.g., promising network parameters) obtained from one model training process to be transferred to other model training processes via multi-task optimization, and outputs the best, among all trained models, which has the overall best performance across the validation sets from all pairs. The knowledge transfer mechanism featured in this new framework can not only enhance training effectiveness by helping the model training process to escape from local optima but also improve on generalization performance via implicit regularization imposed on one model training process from other model training processes. We implement the proposed framework, parallelize the implementation on a GPU cluster, and apply it to train several widely used DNN models. Experimental results demonstrate the superiority of the proposed framework over the conventional training paradigm.
Keyword Aware Influential Community Search in Large Attributed Graphs
Dec 04, 2019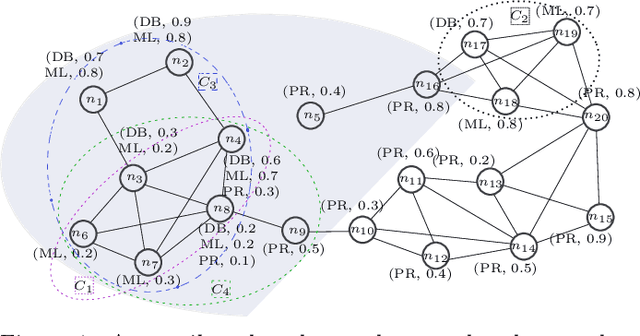

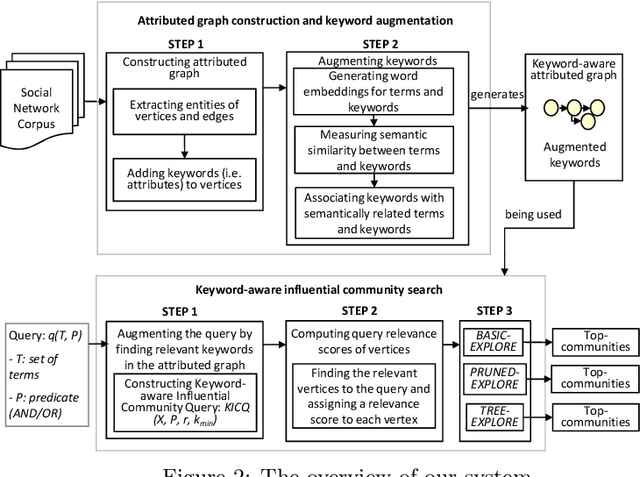

We introduce a novel keyword-aware influential community query KICQ that finds the most influential communities from an attributed graph, where an influential community is defined as a closely connected group of vertices having some dominance over other groups of vertices with the expertise (a set of keywords) matching with the query terms (words or phrases). We first design the KICQ that facilitates users to issue an influential CS query intuitively by using a set of query terms, and predicates (AND or OR). In this context, we propose a novel word-embedding based similarity model that enables semantic community search, which substantially alleviates the limitations of exact keyword based community search. Next, we propose a new influence measure for a community that considers both the cohesiveness and influence of the community and eliminates the need for specifying values of internal parameters of a network. Finally, we propose two efficient algorithms for searching influential communities in large attributed graphs. We present detailed experiments and a case study to demonstrate the effectiveness and efficiency of the proposed approaches.
Location-Centered House Price Prediction: A Multi-Task Learning Approach
Jan 07, 2019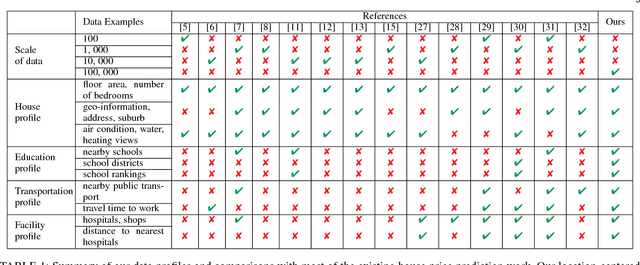
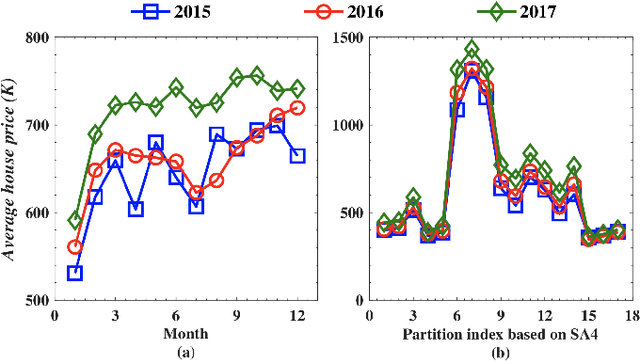

Accurate house prediction is of great significance to various real estate stakeholders such as house owners, buyers, investors, and agents. We propose a location-centered prediction framework that differs from existing work in terms of data profiling and prediction model. Regarding data profiling, we define and capture a fine-grained location profile powered by a diverse range of location data sources, such as transportation profile (e.g., distance to nearest train station), education profile (e.g., school zones and ranking), suburb profile based on census data, facility profile (e.g., nearby hospitals, supermarkets). Regarding the choice of prediction model, we observe that a variety of approaches either consider the entire house data for modeling, or split the entire data and model each partition independently. However, such modeling ignores the relatedness between partitions, and for all prediction scenarios, there may not be sufficient training samples per partition for the latter approach. We address this problem by conducting a careful study of exploiting the Multi-Task Learning (MTL) model. Specifically, we map the strategies for splitting the entire house data to the ways the tasks are defined in MTL, and each partition obtained is aligned with a task. Furthermore, we select specific MTL-based methods with different regularization terms to capture and exploit the relatedness between tasks. Based on real-world house transaction data collected in Melbourne, Australia. We design extensive experimental evaluations, and the results indicate a significant superiority of MTL-based methods over state-of-the-art approaches. Meanwhile, we conduct an in-depth analysis on the impact of task definitions and method selections in MTL on the prediction performance, and demonstrate that the impact of task definitions on prediction performance far exceeds that of method selections.
A Trajectory Calculus for Qualitative Spatial Reasoning Using Answer Set Programming
Apr 19, 2018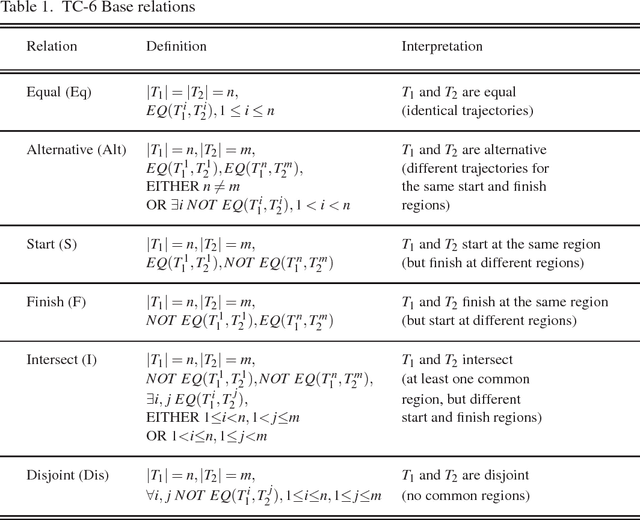
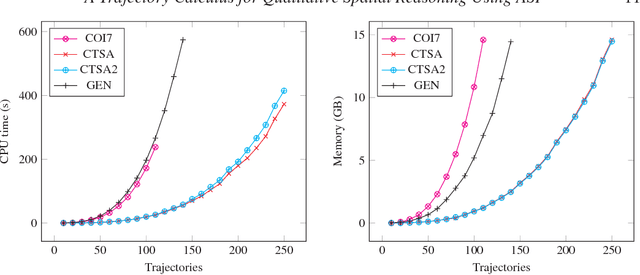
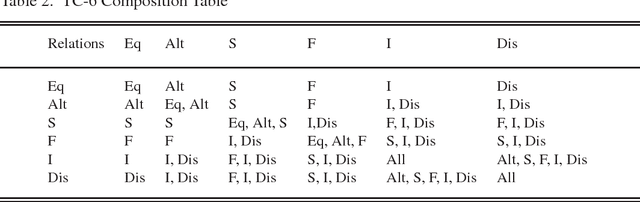
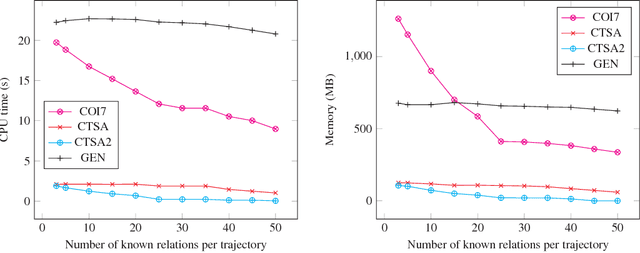
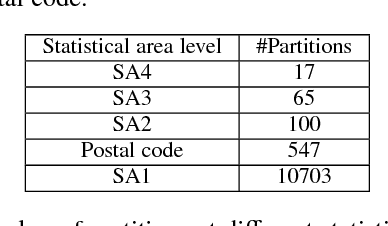
Spatial information is often expressed using qualitative terms such as natural language expressions instead of coordinates; reasoning over such terms has several practical applications, such as bus routes planning. Representing and reasoning on trajectories is a specific case of qualitative spatial reasoning that focuses on moving objects and their paths. In this work, we propose two versions of a trajectory calculus based on the allowed properties over trajectories, where trajectories are defined as a sequence of non-overlapping regions of a partitioned map. More specifically, if a given trajectory is allowed to start and finish at the same region, 6 base relations are defined (TC-6). If a given trajectory should have different start and finish regions but cycles are allowed within, 10 base relations are defined (TC-10). Both versions of the calculus are implemented as ASP programs; we propose several different encodings, including a generalised program capable of encoding any qualitative calculus in ASP. All proposed encodings are experimentally evaluated using a real-world dataset. Experiment results show that the best performing implementation can scale up to an input of 250 trajectories for TC-6 and 150 trajectories for TC-10 for the problem of discovering a consistent configuration, a significant improvement compared to previous ASP implementations for similar qualitative spatial and temporal calculi. This manuscript is under consideration for acceptance in TPLP.