 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Multi-Agent Reinforcement Learning for Decentralized Agent Teams
Nov 15, 2025Connected and autonomous vehicles across land, water, and air must often operate in dynamic, unpredictable environments with limited communication, no centralized control, and partial observability. These real-world constraints pose significant challenges for coordination, particularly when vehicles pursue individual objectives. To address this, we propose a decentralized Multi-Agent Reinforcement Learning (MARL) framework that enables vehicles, acting as agents, to communicate selectively based on local goals and observations. This goal-aware communication strategy allows agents to share only relevant information, enhancing collaboration while respecting visibility limitations. We validate our approach in complex multi-agent navigation tasks featuring obstacles and dynamic agent populations. Results show that our method significantly improves task success rates and reduces time-to-goal compared to non-cooperative baselines. Moreover, task performance remains stable as the number of agents increases, demonstrating scalability. These findings highlight the potential of decentralized, goal-driven MARL to support effective coordination in realistic multi-vehicle systems operating across diverse domains.
Supervised Quantum Machine Learning: A Future Outlook from Qubits to Enterprise Applications
May 30, 2025Supervised Quantum Machine Learning (QML) represents an intersection of quantum computing and classical machine learning, aiming to use quantum resources to support model training and inference. This paper reviews recent developments in supervised QML, focusing on methods such as variational quantum circuits, quantum neural networks, and quantum kernel methods, along with hybrid quantum-classical workflows. We examine recent experimental studies that show partial indications of quantum advantage and describe current limitations including noise, barren plateaus, scalability issues, and the lack of formal proofs of performance improvement over classical methods. The main contribution is a ten-year outlook (2025-2035) that outlines possible developments in supervised QML, including a roadmap describing conditions under which QML may be used in applied research and enterprise systems over the next decade.
The M-factor: A Novel Metric for Evaluating Neural Architecture Search in Resource-Constrained Environments
Jan 29, 2025



Neural Architecture Search (NAS) aims to automate the design of deep neural networks. However, existing NAS techniques often focus on maximising accuracy, neglecting model efficiency. This limitation restricts their use in resource-constrained environments like mobile devices and edge computing systems. Moreover, current evaluation metrics prioritise performance over efficiency, lacking a balanced approach for assessing architectures suitable for constrained scenarios. To address these challenges, this paper introduces the M-factor, a novel metric combining model accuracy and size. Four diverse NAS techniques are compared: Policy-Based Reinforcement Learning, Regularised Evolution, Tree-structured Parzen Estimator (TPE), and Multi-trial Random Search. These techniques represent different NAS paradigms, providing a comprehensive evaluation of the M-factor. The study analyses ResNet configurations on the CIFAR-10 dataset, with a search space of 19,683 configurations. Experiments reveal that Policy-Based Reinforcement Learning and Regularised Evolution achieved M-factor values of 0.84 and 0.82, respectively, while Multi-trial Random Search attained 0.75, and TPE reached 0.67. Policy-Based Reinforcement Learning exhibited performance changes after 39 trials, while Regularised Evolution optimised within 20 trials. The research investigates the optimisation dynamics and trade-offs between accuracy and model size for each strategy. Findings indicate that, in some cases, random search performed comparably to more complex algorithms when assessed using the M-factor. These results highlight how the M-factor addresses the limitations of existing metrics by guiding NAS towards balanced architectures, offering valuable insights for selecting strategies in scenarios requiring both performance and efficiency.
Overcoming Semantic Dilution in Transformer-Based Next Frame Prediction
Jan 28, 2025Next-frame prediction in videos is crucial for applications such as autonomous driving, object tracking, and motion prediction. The primary challenge in next-frame prediction lies in effectively capturing and processing both spatial and temporal information from previous video sequences. The transformer architecture, known for its prowess in handling sequence data, has made remarkable progress in this domain. However, transformer-based next-frame prediction models face notable issues: (a) The multi-head self-attention (MHSA) mechanism requires the input embedding to be split into $N$ chunks, where $N$ is the number of heads. Each segment captures only a fraction of the original embeddings information, which distorts the representation of the embedding in the latent space, resulting in a semantic dilution problem; (b) These models predict the embeddings of the next frames rather than the frames themselves, but the loss function based on the errors of the reconstructed frames, not the predicted embeddings -- this creates a discrepancy between the training objective and the model output. We propose a Semantic Concentration Multi-Head Self-Attention (SCMHSA) architecture, which effectively mitigates semantic dilution in transformer-based next-frame prediction. Additionally, we introduce a loss function that optimizes SCMHSA in the latent space, aligning the training objective more closely with the model output. Our method demonstrates superior performance compared to the original transformer-based predictors.
Contextual Knowledge Sharing in Multi-Agent Reinforcement Learning with Decentralized Communication and Coordination
Jan 26, 2025Decentralized Multi-Agent Reinforcement Learning (Dec-MARL) has emerged as a pivotal approach for addressing complex tasks in dynamic environments. Existing Multi-Agent Reinforcement Learning (MARL) methodologies typically assume a shared objective among agents and rely on centralized control. However, many real-world scenarios feature agents with individual goals and limited observability of other agents, complicating coordination and hindering adaptability. Existing Dec-MARL strategies prioritize either communication or coordination, lacking an integrated approach that leverages both. This paper presents a novel Dec-MARL framework that integrates peer-to-peer communication and coordination, incorporating goal-awareness and time-awareness into the agents' knowledge-sharing processes. Our framework equips agents with the ability to (i) share contextually relevant knowledge to assist other agents, and (ii) reason based on information acquired from multiple agents, while considering their own goals and the temporal context of prior knowledge. We evaluate our approach through several complex multi-agent tasks in environments with dynamically appearing obstacles. Our work demonstrates that incorporating goal-aware and time-aware knowledge sharing significantly enhances overall performance.
A Survey on Context-Aware Multi-Agent Systems: Techniques, Challenges and Future Directions
Feb 03, 2024
Research interest in autonomous agents is on the rise as an emerging topic. The notable achievements of Large Language Models (LLMs) have demonstrated the considerable potential to attain human-like intelligence in autonomous agents. However, the challenge lies in enabling these agents to learn, reason, and navigate uncertainties in dynamic environments. Context awareness emerges as a pivotal element in fortifying multi-agent systems when dealing with dynamic situations. Despite existing research focusing on both context-aware systems and multi-agent systems, there is a lack of comprehensive surveys outlining techniques for integrating context-aware systems with multi-agent systems. To address this gap, this survey provides a comprehensive overview of state-of-the-art context-aware multi-agent systems. First, we outline the properties of both context-aware systems and multi-agent systems that facilitate integration between these systems. Subsequently, we propose a general process for context-aware systems, with each phase of the process encompassing diverse approaches drawn from various application domains such as collision avoidance in autonomous driving, disaster relief management, utility management, supply chain management, human-AI interaction, and others. Finally, we discuss the existing challenges of context-aware multi-agent systems and provide future research directions in this field.
An AI-based Solution for Enhancing Delivery of Digital Learning for Future Teachers
Nov 09, 2021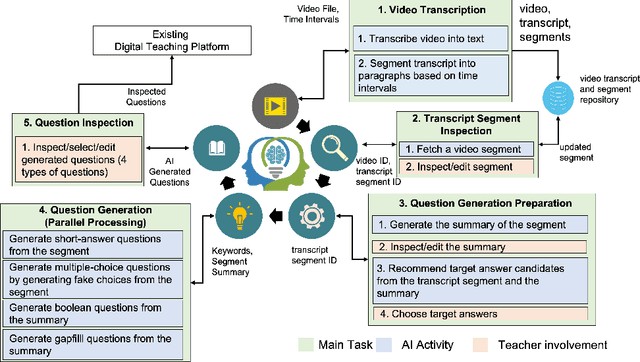

There has been a recent and rapid shift to digital learning hastened by the pandemic but also influenced by ubiquitous availability of digital tools and platforms now, making digital learning ever more accessible. An integral and one of the most difficult part of scaling digital learning and teaching is to be able to assess learner's knowledge and competency. An educator can record a lecture or create digital content that can be delivered to thousands of learners but assessing learners is extremely time consuming. In the paper, we propose an Artificial Intelligence (AI)-based solution namely VidVersityQG for generating questions automatically from pre-recorded video lectures. The solution can automatically generate different types of assessment questions (including short answer, multiple choice, true/false and fill in the blank questions) based on contextual and semantic information inferred from the videos. The proposed solution takes a human-centred approach, wherein teachers are provided the ability to modify/edit any AI generated questions. This approach encourages trust and engagement of teachers in the use and implementation of AI in education. The AI-based solution was evaluated for its accuracy in generating questions by 7 experienced teaching professionals and 117 education videos from multiple domains provided to us by our industry partner VidVersity. VidVersityQG solution showed promising results in generating high-quality questions automatically from video thereby significantly reducing the time and effort for educators in manual question generation.
An open-source framework for ExpFinder integrating $N$-gram Vector Space Model and $μ$CO-HITS
Mar 11, 2021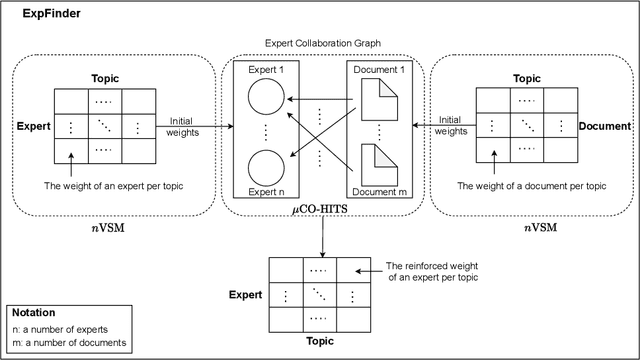

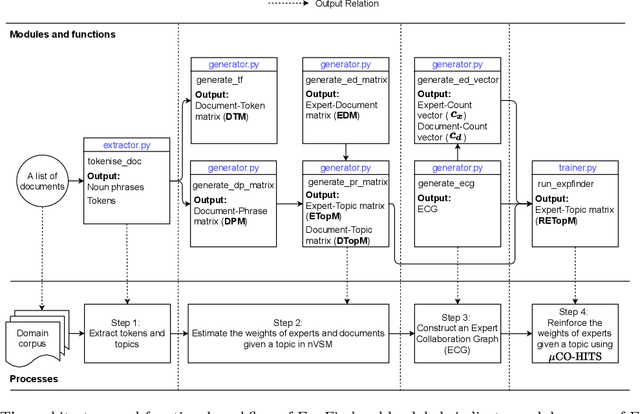
Finding experts drives successful collaborations and high-quality product development in academic and research domains. To contribute to the expert finding research community, we have developed ExpFinder which is a novel ensemble model for expert finding by integrating an $N$-gram vector space model ($n$VSM) and a graph-based model ($\mu$CO-HITS). This paper provides descriptions of ExpFinder's architecture, key components, functionalities, and illustrative examples. ExpFinder is an effective and competitive model for expert finding, significantly outperforming a number of expert finding models.
ExpFinder: An Ensemble Expert Finding Model Integrating $N$-gram Vector Space Model and $μ$CO-HITS
Jan 18, 2021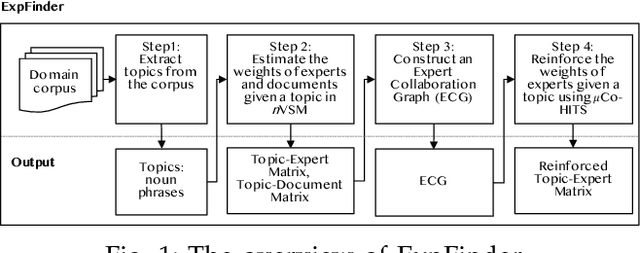
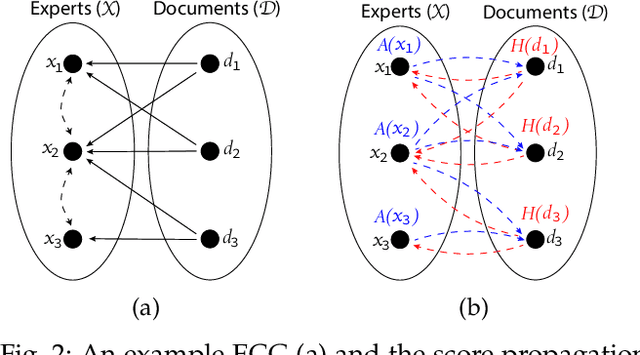

Finding an expert plays a crucial role in driving successful collaborations and speeding up high-quality research development and innovations. However, the rapid growth of scientific publications and digital expertise data makes identifying the right experts a challenging problem. Existing approaches for finding experts given a topic can be categorised into information retrieval techniques based on vector space models, document language models, and graph-based models. In this paper, we propose $\textit{ExpFinder}$, a new ensemble model for expert finding, that integrates a novel $N$-gram vector space model, denoted as $n$VSM, and a graph-based model, denoted as $\textit{$\mu$CO-HITS}$, that is a proposed variation of the CO-HITS algorithm. The key of $n$VSM is to exploit recent inverse document frequency weighting method for $N$-gram words and $\textit{ExpFinder}$ incorporates $n$VSM into $\textit{$\mu$CO-HITS}$ to achieve expert finding. We comprehensively evaluate $\textit{ExpFinder}$ on four different datasets from the academic domains in comparison with six different expert finding models. The evaluation results show that $\textit{ExpFinder}$ is a highly effective model for expert finding, substantially outperforming all the compared models in 19% to 160.2%.