 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Multi-Agent Reinforcement Learning for Decentralized Agent Teams
Nov 15, 2025Connected and autonomous vehicles across land, water, and air must often operate in dynamic, unpredictable environments with limited communication, no centralized control, and partial observability. These real-world constraints pose significant challenges for coordination, particularly when vehicles pursue individual objectives. To address this, we propose a decentralized Multi-Agent Reinforcement Learning (MARL) framework that enables vehicles, acting as agents, to communicate selectively based on local goals and observations. This goal-aware communication strategy allows agents to share only relevant information, enhancing collaboration while respecting visibility limitations. We validate our approach in complex multi-agent navigation tasks featuring obstacles and dynamic agent populations. Results show that our method significantly improves task success rates and reduces time-to-goal compared to non-cooperative baselines. Moreover, task performance remains stable as the number of agents increases, demonstrating scalability. These findings highlight the potential of decentralized, goal-driven MARL to support effective coordination in realistic multi-vehicle systems operating across diverse domains.
The M-factor: A Novel Metric for Evaluating Neural Architecture Search in Resource-Constrained Environments
Jan 29, 2025



Neural Architecture Search (NAS) aims to automate the design of deep neural networks. However, existing NAS techniques often focus on maximising accuracy, neglecting model efficiency. This limitation restricts their use in resource-constrained environments like mobile devices and edge computing systems. Moreover, current evaluation metrics prioritise performance over efficiency, lacking a balanced approach for assessing architectures suitable for constrained scenarios. To address these challenges, this paper introduces the M-factor, a novel metric combining model accuracy and size. Four diverse NAS techniques are compared: Policy-Based Reinforcement Learning, Regularised Evolution, Tree-structured Parzen Estimator (TPE), and Multi-trial Random Search. These techniques represent different NAS paradigms, providing a comprehensive evaluation of the M-factor. The study analyses ResNet configurations on the CIFAR-10 dataset, with a search space of 19,683 configurations. Experiments reveal that Policy-Based Reinforcement Learning and Regularised Evolution achieved M-factor values of 0.84 and 0.82, respectively, while Multi-trial Random Search attained 0.75, and TPE reached 0.67. Policy-Based Reinforcement Learning exhibited performance changes after 39 trials, while Regularised Evolution optimised within 20 trials. The research investigates the optimisation dynamics and trade-offs between accuracy and model size for each strategy. Findings indicate that, in some cases, random search performed comparably to more complex algorithms when assessed using the M-factor. These results highlight how the M-factor addresses the limitations of existing metrics by guiding NAS towards balanced architectures, offering valuable insights for selecting strategies in scenarios requiring both performance and efficiency.
Overcoming Semantic Dilution in Transformer-Based Next Frame Prediction
Jan 28, 2025Next-frame prediction in videos is crucial for applications such as autonomous driving, object tracking, and motion prediction. The primary challenge in next-frame prediction lies in effectively capturing and processing both spatial and temporal information from previous video sequences. The transformer architecture, known for its prowess in handling sequence data, has made remarkable progress in this domain. However, transformer-based next-frame prediction models face notable issues: (a) The multi-head self-attention (MHSA) mechanism requires the input embedding to be split into $N$ chunks, where $N$ is the number of heads. Each segment captures only a fraction of the original embeddings information, which distorts the representation of the embedding in the latent space, resulting in a semantic dilution problem; (b) These models predict the embeddings of the next frames rather than the frames themselves, but the loss function based on the errors of the reconstructed frames, not the predicted embeddings -- this creates a discrepancy between the training objective and the model output. We propose a Semantic Concentration Multi-Head Self-Attention (SCMHSA) architecture, which effectively mitigates semantic dilution in transformer-based next-frame prediction. Additionally, we introduce a loss function that optimizes SCMHSA in the latent space, aligning the training objective more closely with the model output. Our method demonstrates superior performance compared to the original transformer-based predictors.
Contextual Knowledge Sharing in Multi-Agent Reinforcement Learning with Decentralized Communication and Coordination
Jan 26, 2025Decentralized Multi-Agent Reinforcement Learning (Dec-MARL) has emerged as a pivotal approach for addressing complex tasks in dynamic environments. Existing Multi-Agent Reinforcement Learning (MARL) methodologies typically assume a shared objective among agents and rely on centralized control. However, many real-world scenarios feature agents with individual goals and limited observability of other agents, complicating coordination and hindering adaptability. Existing Dec-MARL strategies prioritize either communication or coordination, lacking an integrated approach that leverages both. This paper presents a novel Dec-MARL framework that integrates peer-to-peer communication and coordination, incorporating goal-awareness and time-awareness into the agents' knowledge-sharing processes. Our framework equips agents with the ability to (i) share contextually relevant knowledge to assist other agents, and (ii) reason based on information acquired from multiple agents, while considering their own goals and the temporal context of prior knowledge. We evaluate our approach through several complex multi-agent tasks in environments with dynamically appearing obstacles. Our work demonstrates that incorporating goal-aware and time-aware knowledge sharing significantly enhances overall performance.
A Survey on Context-Aware Multi-Agent Systems: Techniques, Challenges and Future Directions
Feb 03, 2024
Research interest in autonomous agents is on the rise as an emerging topic. The notable achievements of Large Language Models (LLMs) have demonstrated the considerable potential to attain human-like intelligence in autonomous agents. However, the challenge lies in enabling these agents to learn, reason, and navigate uncertainties in dynamic environments. Context awareness emerges as a pivotal element in fortifying multi-agent systems when dealing with dynamic situations. Despite existing research focusing on both context-aware systems and multi-agent systems, there is a lack of comprehensive surveys outlining techniques for integrating context-aware systems with multi-agent systems. To address this gap, this survey provides a comprehensive overview of state-of-the-art context-aware multi-agent systems. First, we outline the properties of both context-aware systems and multi-agent systems that facilitate integration between these systems. Subsequently, we propose a general process for context-aware systems, with each phase of the process encompassing diverse approaches drawn from various application domains such as collision avoidance in autonomous driving, disaster relief management, utility management, supply chain management, human-AI interaction, and others. Finally, we discuss the existing challenges of context-aware multi-agent systems and provide future research directions in this field.
ML-On-Rails: Safeguarding Machine Learning Models in Software Systems A Case Study
Jan 12, 2024



Machine learning (ML), especially with the emergence of large language models (LLMs), has significantly transformed various industries. However, the transition from ML model prototyping to production use within software systems presents several challenges. These challenges primarily revolve around ensuring safety, security, and transparency, subsequently influencing the overall robustness and trustworthiness of ML models. In this paper, we introduce ML-On-Rails, a protocol designed to safeguard ML models, establish a well-defined endpoint interface for different ML tasks, and clear communication between ML providers and ML consumers (software engineers). ML-On-Rails enhances the robustness of ML models via incorporating detection capabilities to identify unique challenges specific to production ML. We evaluated the ML-On-Rails protocol through a real-world case study of the MoveReminder application. Through this evaluation, we emphasize the importance of safeguarding ML models in production.
Evaluating LLMs on Document-Based QA: Exact Answer Selection and Numerical Extraction using Cogtale dataset
Nov 18, 2023Document-based Question-Answering (QA) tasks are crucial for precise information retrieval. While some existing work focus on evaluating large language model's performance on retrieving and answering questions from documents, assessing the LLMs' performance on QA types that require exact answer selection from predefined options and numerical extraction is yet to be fully assessed. In this paper, we specifically focus on this underexplored context and conduct empirical analysis of LLMs (GPT-4 and GPT 3.5) on question types, including single-choice, yes-no, multiple-choice, and number extraction questions from documents. We use the Cogtale dataset for evaluation, which provide human expert-tagged responses, offering a robust benchmark for precision and factual grounding. We found that LLMs, particularly GPT-4, can precisely answer many single-choice and yes-no questions given relevant context, demonstrating their efficacy in information retrieval tasks. However, their performance diminishes when confronted with multiple-choice and number extraction formats, lowering the overall performance of the model on this task, indicating that these models may not be reliable for the task. This limits the applications of LLMs on applications demanding precise information extraction from documents, such as meta-analysis tasks. However, these findings hinge on the assumption that the retrievers furnish pertinent context necessary for accurate responses, emphasizing the need for further research on the efficacy of retriever mechanisms in enhancing question-answering performance. Our work offers a framework for ongoing dataset evaluation, ensuring that LLM applications for information retrieval and document analysis continue to meet evolving standards.
Smart Home Goal Feature Model -- A guide to support Smart Homes for Ageing in Place
Nov 14, 2023



Smart technologies are significant in supporting ageing in place for elderly. Leveraging Artificial Intelligence (AI) and Machine Learning (ML), it provides peace of mind, enabling the elderly to continue living independently. Elderly use smart technologies for entertainment and social interactions, this can be extended to provide safety and monitor health and environmental conditions, detect emergencies and notify informal and formal caregivers when care is needed. This paper provides an overview of the smart home technologies commercially available to support ageing in place, the advantages and challenges of smart home technologies, and their usability from elderlys perspective. Synthesizing prior knowledge, we created a structured Smart Home Goal Feature Model (SHGFM) to resolve heuristic approaches used by the Subject Matter Experts (SMEs) at aged care facilities and healthcare researchers in adapting smart homes. The SHGFM provides SMEs the ability to (i) establish goals and (ii) identify features to set up strategies to design, develop and deploy smart homes for the elderly based on personalised needs. Our model provides guidance to healthcare researchers and aged care industries to set up smart homes based on the needs of elderly, by defining a set of goals at different levels mapped to a different set of features.
Garbage in, garbage out: Zero-shot detection of crime using Large Language Models
Jul 04, 2023This paper proposes exploiting the common sense knowledge learned by large language models to perform zero-shot reasoning about crimes given textual descriptions of surveillance videos. We show that when video is (manually) converted to high quality textual descriptions, large language models are capable of detecting and classifying crimes with state-of-the-art performance using only zero-shot reasoning. However, existing automated video-to-text approaches are unable to generate video descriptions of sufficient quality to support reasoning (garbage video descriptions into the large language model, garbage out).
Comparative analysis of real bugs in open-source Machine Learning projects -- A Registered Report
Sep 20, 2022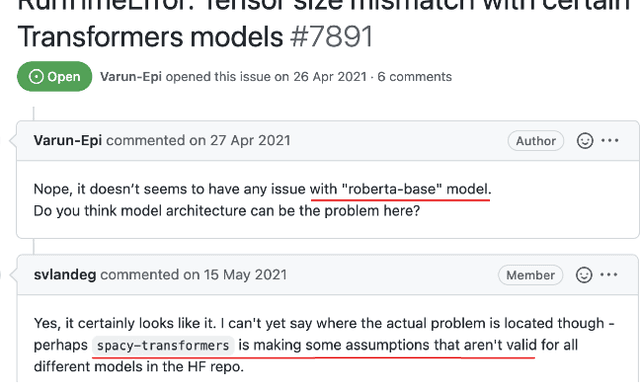

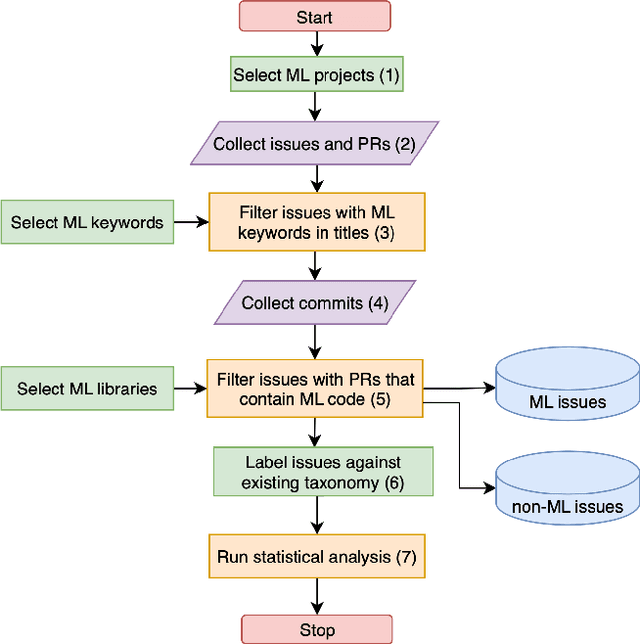
Background: Machine Learning (ML) systems rely on data to make predictions, the systems have many added components compared to traditional software systems such as the data processing pipeline, serving pipeline, and model training. Existing research on software maintenance has studied the issue-reporting needs and resolution process for different types of issues, such as performance and security issues. However, ML systems have specific classes of faults, and reporting ML issues requires domain-specific information. Because of the different characteristics between ML and traditional Software Engineering systems, we do not know to what extent the reporting needs are different, and to what extent these differences impact the issue resolution process. Objective: Our objective is to investigate whether there is a discrepancy in the distribution of resolution time between ML and non-ML issues and whether certain categories of ML issues require a longer time to resolve based on real issue reports in open-source applied ML projects. We further investigate the size of fix of ML issues and non-ML issues. Method: We extract issues reports, pull requests and code files in recent active applied ML projects from Github, and use an automatic approach to filter ML and non-ML issues. We manually label the issues using a known taxonomy of deep learning bugs. We measure the resolution time and size of fix of ML and non-ML issues on a controlled sample and compare the distributions for each category of issue.