 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimising changes to audit when updating decision trees
Aug 29, 2024Interpretable models are important, but what happens when the model is updated on new training data? We propose an algorithm for updating a decision tree while minimising the number of changes to the tree that a human would need to audit. We achieve this via a greedy approach that incorporates the number of changes to the tree as part of the objective function. We compare our algorithm to existing methods and show that it sits in a sweet spot between final accuracy and number of changes to audit.
Quantifying Manifolds: Do the manifolds learned by Generative Adversarial Networks converge to the real data manifold
Mar 08, 2024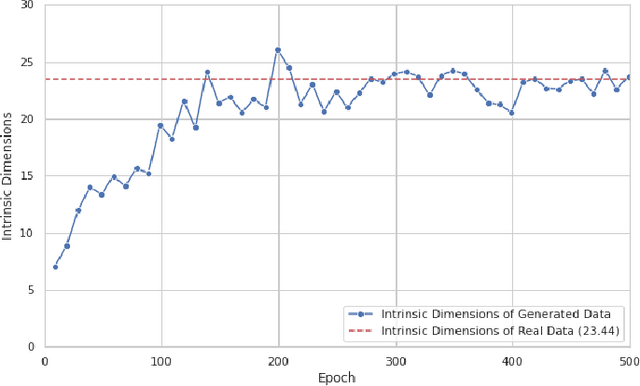
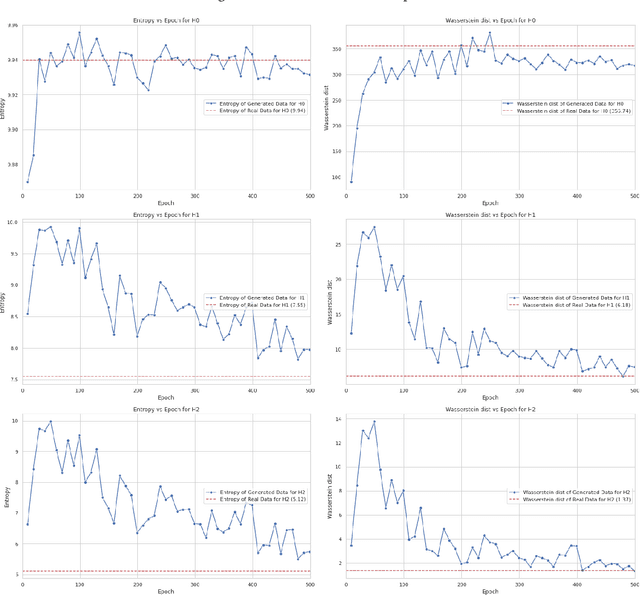
This paper presents our experiments to quantify the manifolds learned by ML models (in our experiment, we use a GAN model) as they train. We compare the manifolds learned at each epoch to the real manifolds representing the real data. To quantify a manifold, we study the intrinsic dimensions and topological features of the manifold learned by the ML model, how these metrics change as we continue to train the model, and whether these metrics convergence over the course of training to the metrics of the real data manifold.
Detecting out-of-distribution text using topological features of transformer-based language models
Nov 22, 2023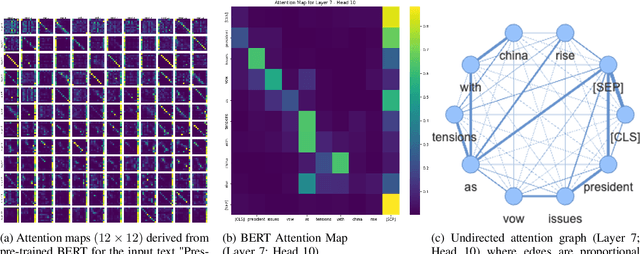
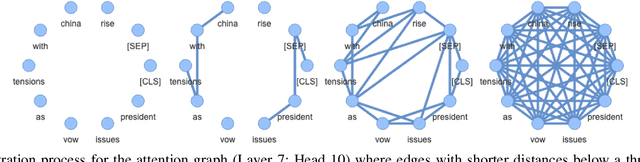

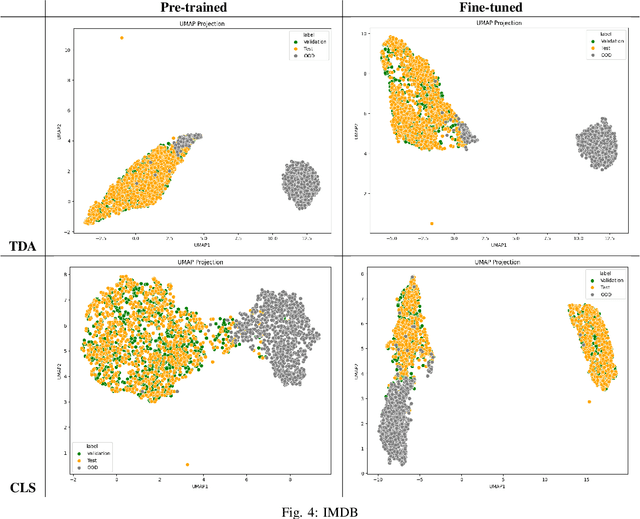
We attempt to detect out-of-distribution (OOD) text samples though applying Topological Data Analysis (TDA) to attention maps in transformer-based language models. We evaluate our proposed TDA-based approach for out-of-distribution detection on BERT, a transformer-based language model, and compare the to a more traditional OOD approach based on BERT CLS embeddings. We found that our TDA approach outperforms the CLS embedding approach at distinguishing in-distribution data (politics and entertainment news articles from HuffPost) from far out-of-domain samples (IMDB reviews), but its effectiveness deteriorates with near out-of-domain (CNN/Dailymail) or same-domain (business news articles from HuffPost) datasets.
Garbage in, garbage out: Zero-shot detection of crime using Large Language Models
Jul 04, 2023This paper proposes exploiting the common sense knowledge learned by large language models to perform zero-shot reasoning about crimes given textual descriptions of surveillance videos. We show that when video is (manually) converted to high quality textual descriptions, large language models are capable of detecting and classifying crimes with state-of-the-art performance using only zero-shot reasoning. However, existing automated video-to-text approaches are unable to generate video descriptions of sufficient quality to support reasoning (garbage video descriptions into the large language model, garbage out).
Green Runner: A tool for efficient model selection from model repositories
May 26, 2023Deep learning models have become essential in software engineering, enabling intelligent features like image captioning and document generation. However, their popularity raises concerns about environmental impact and inefficient model selection. This paper introduces GreenRunnerGPT, a novel tool for efficiently selecting deep learning models based on specific use cases. It employs a large language model to suggest weights for quality indicators, optimizing resource utilization. The tool utilizes a multi-armed bandit framework to evaluate models against target datasets, considering tradeoffs. We demonstrate that GreenRunnerGPT is able to identify a model suited to a target use case without wasteful computations that would occur under a brute-force approach to model selection.
Comparative analysis of real bugs in open-source Machine Learning projects -- A Registered Report
Sep 20, 2022

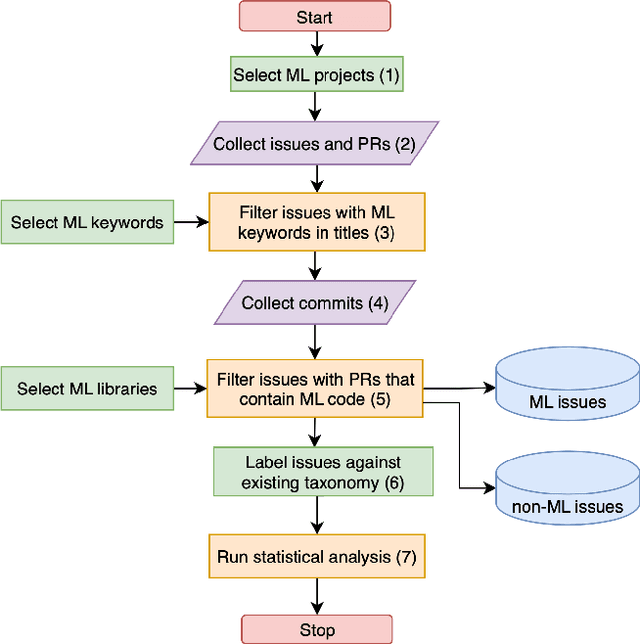
Background: Machine Learning (ML) systems rely on data to make predictions, the systems have many added components compared to traditional software systems such as the data processing pipeline, serving pipeline, and model training. Existing research on software maintenance has studied the issue-reporting needs and resolution process for different types of issues, such as performance and security issues. However, ML systems have specific classes of faults, and reporting ML issues requires domain-specific information. Because of the different characteristics between ML and traditional Software Engineering systems, we do not know to what extent the reporting needs are different, and to what extent these differences impact the issue resolution process. Objective: Our objective is to investigate whether there is a discrepancy in the distribution of resolution time between ML and non-ML issues and whether certain categories of ML issues require a longer time to resolve based on real issue reports in open-source applied ML projects. We further investigate the size of fix of ML issues and non-ML issues. Method: We extract issues reports, pull requests and code files in recent active applied ML projects from Github, and use an automatic approach to filter ML and non-ML issues. We manually label the issues using a known taxonomy of deep learning bugs. We measure the resolution time and size of fix of ML and non-ML issues on a controlled sample and compare the distributions for each category of issue.
SignalKG: Towards Reasoning about the Underlying Causes of Sensor Observations
Sep 01, 2022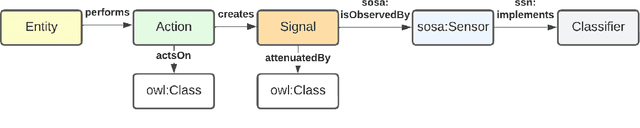
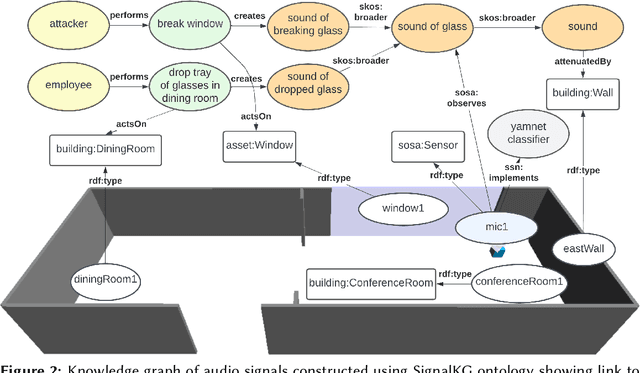
This paper demonstrates our vision for knowledge graphs that assist machines to reason about the cause of signals observed by sensors. We show how the approach allows for constructing smarter surveillance systems that reason about the most likely cause (e.g., an attacker breaking a window) of a signal rather than acting directly on the received signal without consideration for how it was produced.
Signal Knowledge Graph
Jun 24, 2022
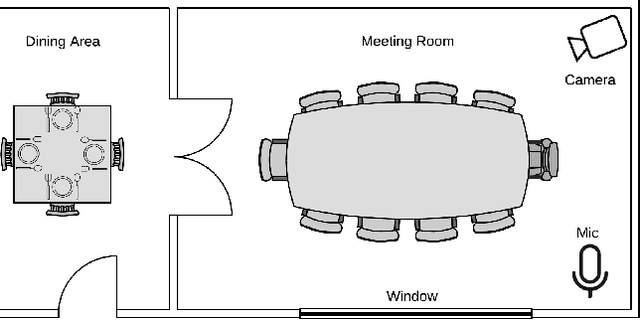
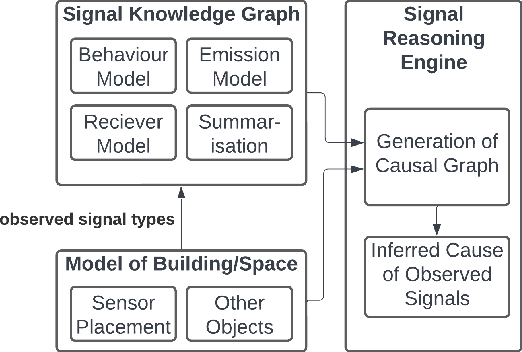
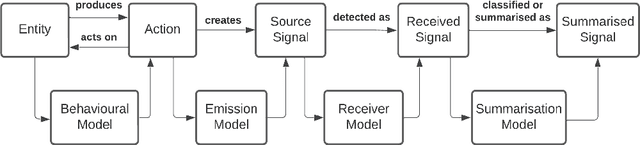
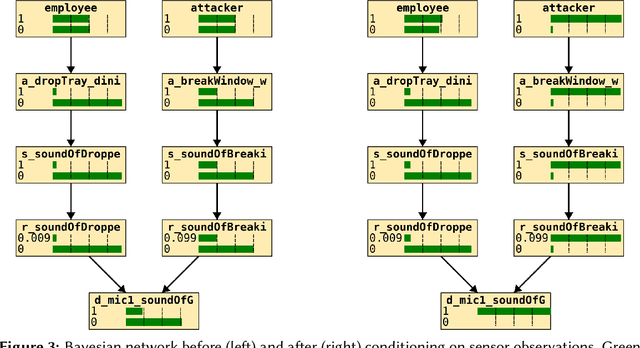
This paper presents an knowledge graph to assist in reasoning over signals for intelligence purposes. We highlight limitations of existing knowledge graphs and reasoning systems for this purpose, using inference of an attack using combined data from microphones, cameras and social media as an example. Rather than acting directly on the received signal, our approach considers attacker behaviour, signal emission, receiver characteristics, and how signals are summarised to support inferring the underlying cause of the signal.
MLSmellHound: A Context-Aware Code Analysis Tool
May 08, 2022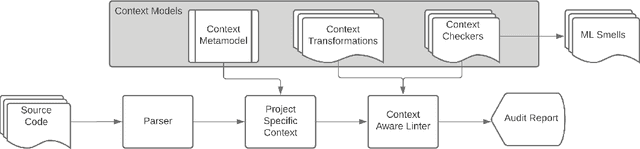
Meeting the rise of industry demand to incorporate machine learning (ML) components into software systems requires interdisciplinary teams contributing to a shared code base. To maintain consistency, reduce defects and ensure maintainability, developers use code analysis tools to aid them in identifying defects and maintaining standards. With the inclusion of machine learning, tools must account for the cultural differences within the teams which manifests as multiple programming languages, and conflicting definitions and objectives. Existing tools fail to identify these cultural differences and are geared towards software engineering which reduces their adoption in ML projects. In our approach we attempt to resolve this problem by exploring the use of context which includes i) purpose of the source code, ii) technical domain, iii) problem domain, iv) team norms, v) operational environment, and vi) development lifecycle stage to provide contextualised error reporting for code analysis. To demonstrate our approach, we adapt Pylint as an example and apply a set of contextual transformations to the linting results based on the domain of individual project files under analysis. This allows for contextualised and meaningful error reporting for the end-user.