 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-On-Rails: Safeguarding Machine Learning Models in Software Systems A Case Study
Jan 12, 2024



Machine learning (ML), especially with the emergence of large language models (LLMs), has significantly transformed various industries. However, the transition from ML model prototyping to production use within software systems presents several challenges. These challenges primarily revolve around ensuring safety, security, and transparency, subsequently influencing the overall robustness and trustworthiness of ML models. In this paper, we introduce ML-On-Rails, a protocol designed to safeguard ML models, establish a well-defined endpoint interface for different ML tasks, and clear communication between ML providers and ML consumers (software engineers). ML-On-Rails enhances the robustness of ML models via incorporating detection capabilities to identify unique challenges specific to production ML. We evaluated the ML-On-Rails protocol through a real-world case study of the MoveReminder application. Through this evaluation, we emphasize the importance of safeguarding ML models in production.
Comparative analysis of real bugs in open-source Machine Learning projects -- A Registered Report
Sep 20, 2022

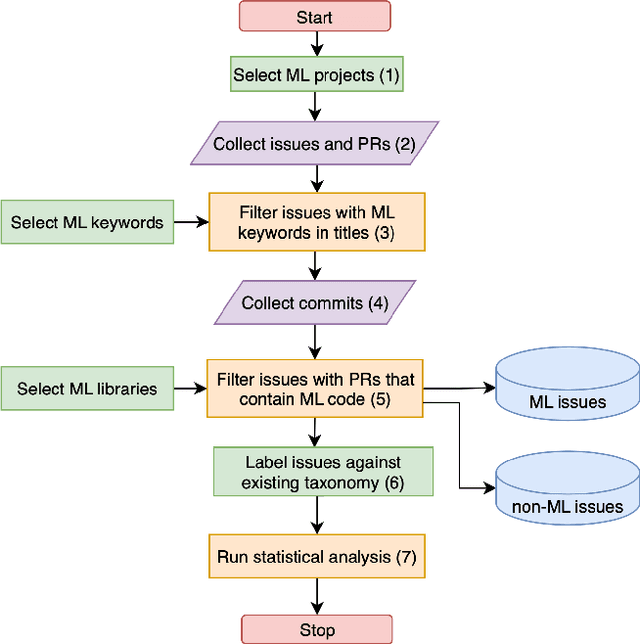
Background: Machine Learning (ML) systems rely on data to make predictions, the systems have many added components compared to traditional software systems such as the data processing pipeline, serving pipeline, and model training. Existing research on software maintenance has studied the issue-reporting needs and resolution process for different types of issues, such as performance and security issues. However, ML systems have specific classes of faults, and reporting ML issues requires domain-specific information. Because of the different characteristics between ML and traditional Software Engineering systems, we do not know to what extent the reporting needs are different, and to what extent these differences impact the issue resolution process. Objective: Our objective is to investigate whether there is a discrepancy in the distribution of resolution time between ML and non-ML issues and whether certain categories of ML issues require a longer time to resolve based on real issue reports in open-source applied ML projects. We further investigate the size of fix of ML issues and non-ML issues. Method: We extract issues reports, pull requests and code files in recent active applied ML projects from Github, and use an automatic approach to filter ML and non-ML issues. We manually label the issues using a known taxonomy of deep learning bugs. We measure the resolution time and size of fix of ML and non-ML issues on a controlled sample and compare the distributions for each category of issue.