 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe M-factor: A Novel Metric for Evaluating Neural Architecture Search in Resource-Constrained Environments
Jan 29, 2025



Neural Architecture Search (NAS) aims to automate the design of deep neural networks. However, existing NAS techniques often focus on maximising accuracy, neglecting model efficiency. This limitation restricts their use in resource-constrained environments like mobile devices and edge computing systems. Moreover, current evaluation metrics prioritise performance over efficiency, lacking a balanced approach for assessing architectures suitable for constrained scenarios. To address these challenges, this paper introduces the M-factor, a novel metric combining model accuracy and size. Four diverse NAS techniques are compared: Policy-Based Reinforcement Learning, Regularised Evolution, Tree-structured Parzen Estimator (TPE), and Multi-trial Random Search. These techniques represent different NAS paradigms, providing a comprehensive evaluation of the M-factor. The study analyses ResNet configurations on the CIFAR-10 dataset, with a search space of 19,683 configurations. Experiments reveal that Policy-Based Reinforcement Learning and Regularised Evolution achieved M-factor values of 0.84 and 0.82, respectively, while Multi-trial Random Search attained 0.75, and TPE reached 0.67. Policy-Based Reinforcement Learning exhibited performance changes after 39 trials, while Regularised Evolution optimised within 20 trials. The research investigates the optimisation dynamics and trade-offs between accuracy and model size for each strategy. Findings indicate that, in some cases, random search performed comparably to more complex algorithms when assessed using the M-factor. These results highlight how the M-factor addresses the limitations of existing metrics by guiding NAS towards balanced architectures, offering valuable insights for selecting strategies in scenarios requiring both performance and efficiency.
Minimising changes to audit when updating decision trees
Aug 29, 2024Interpretable models are important, but what happens when the model is updated on new training data? We propose an algorithm for updating a decision tree while minimising the number of changes to the tree that a human would need to audit. We achieve this via a greedy approach that incorporates the number of changes to the tree as part of the objective function. We compare our algorithm to existing methods and show that it sits in a sweet spot between final accuracy and number of changes to audit.
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Jun 17, 2024



Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: "To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case." This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
LLMs for Test Input Generation for Semantic Caches
Jan 16, 2024Large language models (LLMs) enable state-of-the-art semantic capabilities to be added to software systems such as semantic search of unstructured documents and text generation. However, these models are computationally expensive. At scale, the cost of serving thousands of users increases massively affecting also user experience. To address this problem, semantic caches are used to check for answers to similar queries (that may have been phrased differently) without hitting the LLM service. Due to the nature of these semantic cache techniques that rely on query embeddings, there is a high chance of errors impacting user confidence in the system. Adopting semantic cache techniques usually requires testing the effectiveness of a semantic cache (accurate cache hits and misses) which requires a labelled test set of similar queries and responses which is often unavailable. In this paper, we present VaryGen, an approach for using LLMs for test input generation that produces similar questions from unstructured text documents. Our novel approach uses the reasoning capabilities of LLMs to 1) adapt queries to the domain, 2) synthesise subtle variations to queries, and 3) evaluate the synthesised test dataset. We evaluated our approach in the domain of a student question and answer system by qualitatively analysing 100 generated queries and result pairs, and conducting an empirical case study with an open source semantic cache. Our results show that query pairs satisfy human expectations of similarity and our generated data demonstrates failure cases of a semantic cache. Additionally, we also evaluate our approach on Qasper dataset. This work is an important first step into test input generation for semantic applications and presents considerations for practitioners when calibrating a semantic cache.
ML-On-Rails: Safeguarding Machine Learning Models in Software Systems A Case Study
Jan 12, 2024



Machine learning (ML), especially with the emergence of large language models (LLMs), has significantly transformed various industries. However, the transition from ML model prototyping to production use within software systems presents several challenges. These challenges primarily revolve around ensuring safety, security, and transparency, subsequently influencing the overall robustness and trustworthiness of ML models. In this paper, we introduce ML-On-Rails, a protocol designed to safeguard ML models, establish a well-defined endpoint interface for different ML tasks, and clear communication between ML providers and ML consumers (software engineers). ML-On-Rails enhances the robustness of ML models via incorporating detection capabilities to identify unique challenges specific to production ML. We evaluated the ML-On-Rails protocol through a real-world case study of the MoveReminder application. Through this evaluation, we emphasize the importance of safeguarding ML models in production.
Evaluating LLMs on Document-Based QA: Exact Answer Selection and Numerical Extraction using Cogtale dataset
Nov 18, 2023Document-based Question-Answering (QA) tasks are crucial for precise information retrieval. While some existing work focus on evaluating large language model's performance on retrieving and answering questions from documents, assessing the LLMs' performance on QA types that require exact answer selection from predefined options and numerical extraction is yet to be fully assessed. In this paper, we specifically focus on this underexplored context and conduct empirical analysis of LLMs (GPT-4 and GPT 3.5) on question types, including single-choice, yes-no, multiple-choice, and number extraction questions from documents. We use the Cogtale dataset for evaluation, which provide human expert-tagged responses, offering a robust benchmark for precision and factual grounding. We found that LLMs, particularly GPT-4, can precisely answer many single-choice and yes-no questions given relevant context, demonstrating their efficacy in information retrieval tasks. However, their performance diminishes when confronted with multiple-choice and number extraction formats, lowering the overall performance of the model on this task, indicating that these models may not be reliable for the task. This limits the applications of LLMs on applications demanding precise information extraction from documents, such as meta-analysis tasks. However, these findings hinge on the assumption that the retrievers furnish pertinent context necessary for accurate responses, emphasizing the need for further research on the efficacy of retriever mechanisms in enhancing question-answering performance. Our work offers a framework for ongoing dataset evaluation, ensuring that LLM applications for information retrieval and document analysis continue to meet evolving standards.
Green Runner: A tool for efficient model selection from model repositories
May 26, 2023Deep learning models have become essential in software engineering, enabling intelligent features like image captioning and document generation. However, their popularity raises concerns about environmental impact and inefficient model selection. This paper introduces GreenRunnerGPT, a novel tool for efficiently selecting deep learning models based on specific use cases. It employs a large language model to suggest weights for quality indicators, optimizing resource utilization. The tool utilizes a multi-armed bandit framework to evaluate models against target datasets, considering tradeoffs. We demonstrate that GreenRunnerGPT is able to identify a model suited to a target use case without wasteful computations that would occur under a brute-force approach to model selection.
Comparative analysis of real bugs in open-source Machine Learning projects -- A Registered Report
Sep 20, 2022

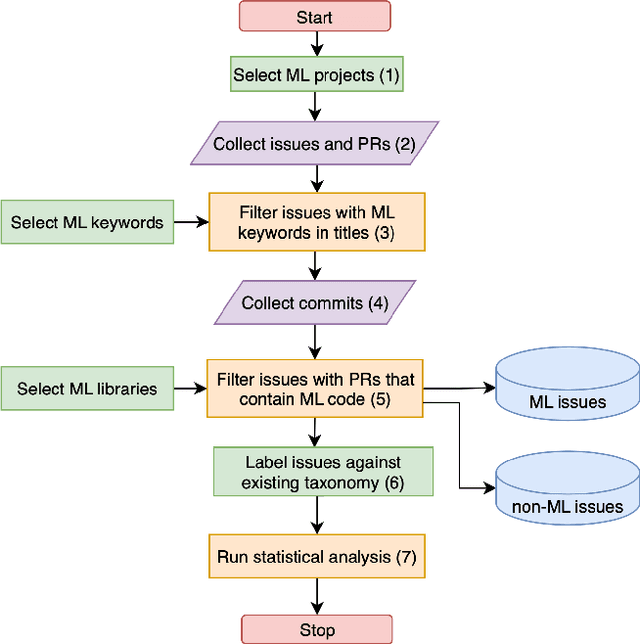
Background: Machine Learning (ML) systems rely on data to make predictions, the systems have many added components compared to traditional software systems such as the data processing pipeline, serving pipeline, and model training. Existing research on software maintenance has studied the issue-reporting needs and resolution process for different types of issues, such as performance and security issues. However, ML systems have specific classes of faults, and reporting ML issues requires domain-specific information. Because of the different characteristics between ML and traditional Software Engineering systems, we do not know to what extent the reporting needs are different, and to what extent these differences impact the issue resolution process. Objective: Our objective is to investigate whether there is a discrepancy in the distribution of resolution time between ML and non-ML issues and whether certain categories of ML issues require a longer time to resolve based on real issue reports in open-source applied ML projects. We further investigate the size of fix of ML issues and non-ML issues. Method: We extract issues reports, pull requests and code files in recent active applied ML projects from Github, and use an automatic approach to filter ML and non-ML issues. We manually label the issues using a known taxonomy of deep learning bugs. We measure the resolution time and size of fix of ML and non-ML issues on a controlled sample and compare the distributions for each category of issue.
MLSmellHound: A Context-Aware Code Analysis Tool
May 08, 2022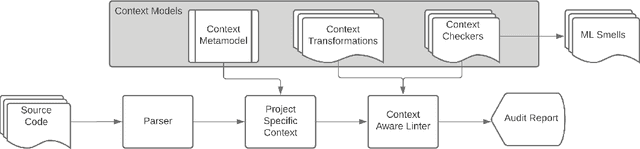
Meeting the rise of industry demand to incorporate machine learning (ML) components into software systems requires interdisciplinary teams contributing to a shared code base. To maintain consistency, reduce defects and ensure maintainability, developers use code analysis tools to aid them in identifying defects and maintaining standards. With the inclusion of machine learning, tools must account for the cultural differences within the teams which manifests as multiple programming languages, and conflicting definitions and objectives. Existing tools fail to identify these cultural differences and are geared towards software engineering which reduces their adoption in ML projects. In our approach we attempt to resolve this problem by exploring the use of context which includes i) purpose of the source code, ii) technical domain, iii) problem domain, iv) team norms, v) operational environment, and vi) development lifecycle stage to provide contextualised error reporting for code analysis. To demonstrate our approach, we adapt Pylint as an example and apply a set of contextual transformations to the linting results based on the domain of individual project files under analysis. This allows for contextualised and meaningful error reporting for the end-user.
Beware the evolving 'intelligent' web service! An integration architecture tactic to guard AI-first components
May 27, 2020

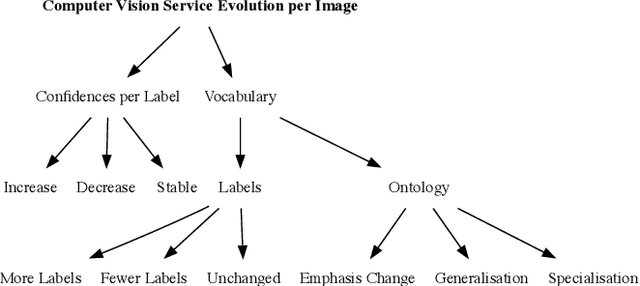
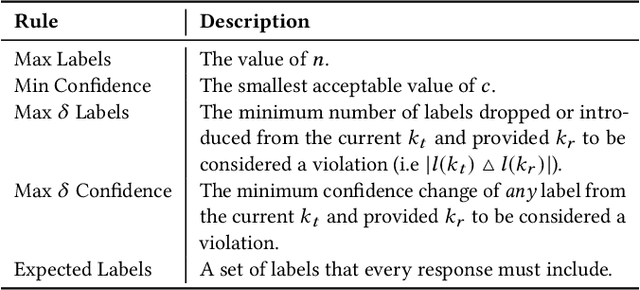
Intelligent services provide the power of AI to developers via simple RESTful API endpoints, abstracting away many complexities of machine learning. However, most of these intelligent services-such as computer vision-continually learn with time. When the internals within the abstracted 'black box' become hidden and evolve, pitfalls emerge in the robustness of applications that depend on these evolving services. Without adapting the way developers plan and construct projects reliant on intelligent services, significant gaps and risks result in both project planning and development. Therefore, how can software engineers best mitigate software evolution risk moving forward, thereby ensuring that their own applications maintain quality? Our proposal is an architectural tactic designed to improve intelligent service-dependent software robustness. The tactic involves creating an application-specific benchmark dataset baselined against an intelligent service, enabling evolutionary behaviour changes to be mitigated. A technical evaluation of our implementation of this architecture demonstrates how the tactic can identify 1,054 cases of substantial confidence evolution and 2,461 cases of substantial changes to response label sets using a dataset consisting of 331 images that evolve when sent to a service.