 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimising changes to audit when updating decision trees
Aug 29, 2024Interpretable models are important, but what happens when the model is updated on new training data? We propose an algorithm for updating a decision tree while minimising the number of changes to the tree that a human would need to audit. We achieve this via a greedy approach that incorporates the number of changes to the tree as part of the objective function. We compare our algorithm to existing methods and show that it sits in a sweet spot between final accuracy and number of changes to audit.
Quantifying Manifolds: Do the manifolds learned by Generative Adversarial Networks converge to the real data manifold
Mar 08, 2024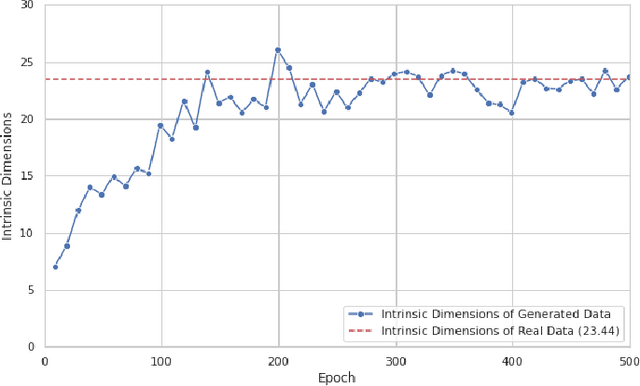
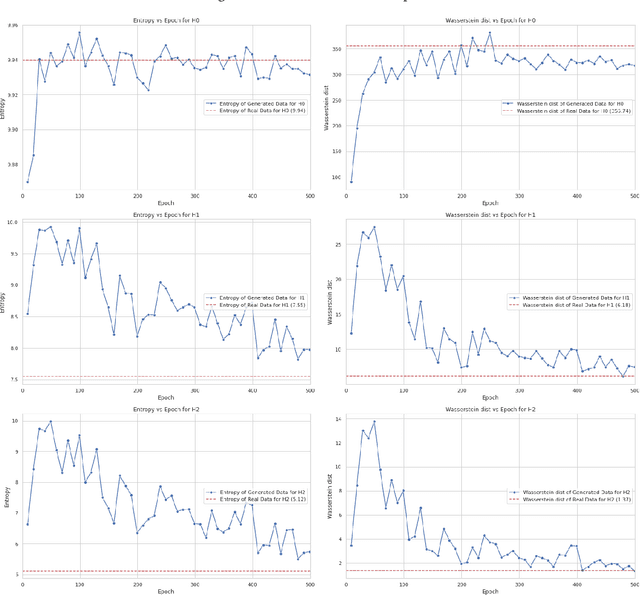
This paper presents our experiments to quantify the manifolds learned by ML models (in our experiment, we use a GAN model) as they train. We compare the manifolds learned at each epoch to the real manifolds representing the real data. To quantify a manifold, we study the intrinsic dimensions and topological features of the manifold learned by the ML model, how these metrics change as we continue to train the model, and whether these metrics convergence over the course of training to the metrics of the real data manifold.
Detecting out-of-distribution text using topological features of transformer-based language models
Nov 22, 2023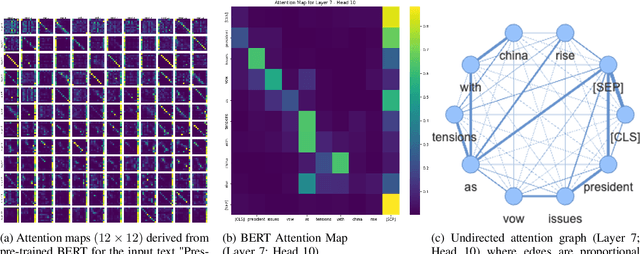
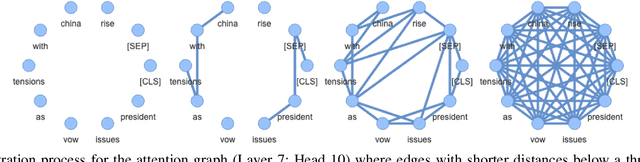

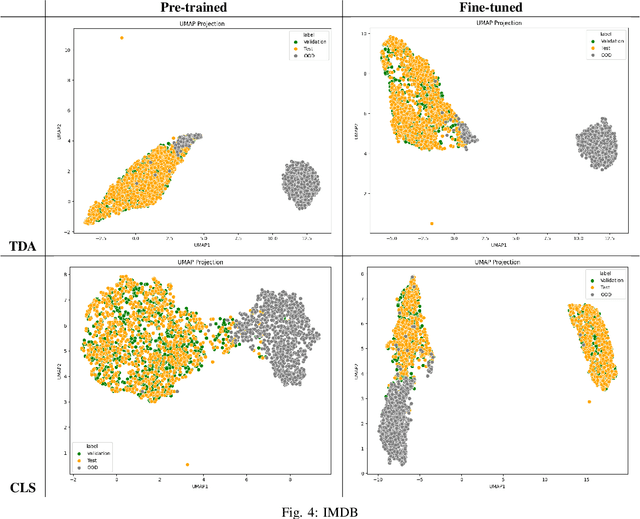
We attempt to detect out-of-distribution (OOD) text samples though applying Topological Data Analysis (TDA) to attention maps in transformer-based language models. We evaluate our proposed TDA-based approach for out-of-distribution detection on BERT, a transformer-based language model, and compare the to a more traditional OOD approach based on BERT CLS embeddings. We found that our TDA approach outperforms the CLS embedding approach at distinguishing in-distribution data (politics and entertainment news articles from HuffPost) from far out-of-domain samples (IMDB reviews), but its effectiveness deteriorates with near out-of-domain (CNN/Dailymail) or same-domain (business news articles from HuffPost) datasets.