Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting out-of-distribution text using topological features of transformer-based language models
Paper and Code
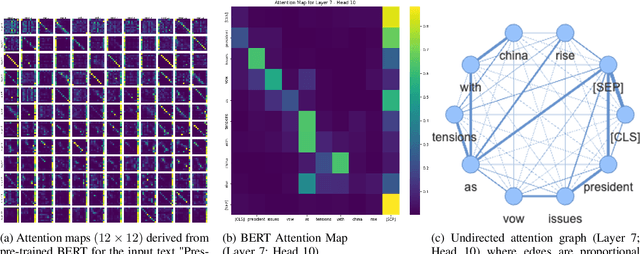
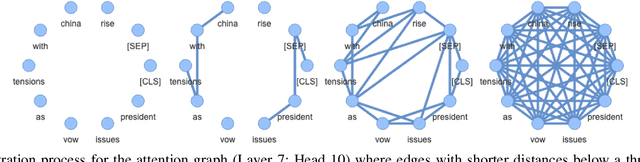

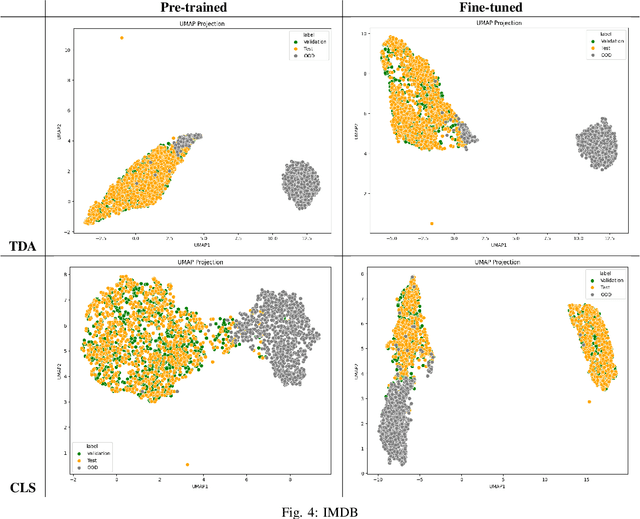
We attempt to detect out-of-distribution (OOD) text samples though applying Topological Data Analysis (TDA) to attention maps in transformer-based language models. We evaluate our proposed TDA-based approach for out-of-distribution detection on BERT, a transformer-based language model, and compare the to a more traditional OOD approach based on BERT CLS embeddings. We found that our TDA approach outperforms the CLS embedding approach at distinguishing in-distribution data (politics and entertainment news articles from HuffPost) from far out-of-domain samples (IMDB reviews), but its effectiveness deteriorates with near out-of-domain (CNN/Dailymail) or same-domain (business news articles from HuffPost) datasets.
* 12 pages, 6 figures, 3 tables
View paper on