 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Runner: A tool for efficient deep learning component selection
Jan 29, 2024
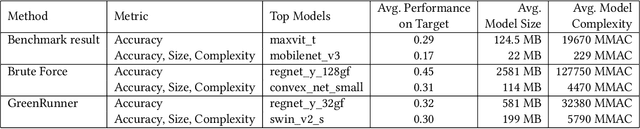

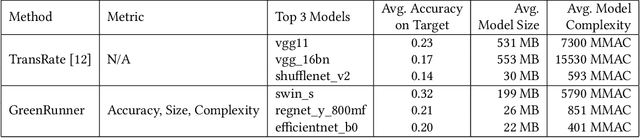
For software that relies on machine-learned functionality, model selection is key to finding the right model for the task with desired performance characteristics. Evaluating a model requires developers to i) select from many models (e.g. the Hugging face model repository), ii) select evaluation metrics and training strategy, and iii) tailor trade-offs based on the problem domain. However, current evaluation approaches are either ad-hoc resulting in sub-optimal model selection or brute force leading to wasted compute. In this work, we present \toolname, a novel tool to automatically select and evaluate models based on the application scenario provided in natural language. We leverage the reasoning capabilities of large language models to propose a training strategy and extract desired trade-offs from a problem description. \toolname~features a resource-efficient experimentation engine that integrates constraints and trade-offs based on the problem into the model selection process. Our preliminary evaluation demonstrates that \toolname{} is both efficient and accurate compared to ad-hoc evaluations and brute force. This work presents an important step toward energy-efficient tools to help reduce the environmental impact caused by the growing demand for software with machine-learned functionality.
Can LLMs Configure Software Tools
Dec 11, 2023



In software engineering, the meticulous configuration of software tools is crucial in ensuring optimal performance within intricate systems. However, the complexity inherent in selecting optimal configurations is exacerbated by the high-dimensional search spaces presented in modern applications. Conventional trial-and-error or intuition-driven methods are both inefficient and error-prone, impeding scalability and reproducibility. In this study, we embark on an exploration of leveraging Large-Language Models (LLMs) to streamline the software configuration process. We identify that the task of hyperparameter configuration for machine learning components within intelligent applications is particularly challenging due to the extensive search space and performance-critical nature. Existing methods, including Bayesian optimization, have limitations regarding initial setup, computational cost, and convergence efficiency. Our work presents a novel approach that employs LLMs, such as Chat-GPT, to identify starting conditions and narrow down the search space, improving configuration efficiency. We conducted a series of experiments to investigate the variability of LLM-generated responses, uncovering intriguing findings such as potential response caching and consistent behavior based on domain-specific keywords. Furthermore, our results from hyperparameter optimization experiments reveal the potential of LLMs in expediting initialization processes and optimizing configurations. While our initial insights are promising, they also indicate the need for further in-depth investigations and experiments in this domain.
Green Runner: A tool for efficient model selection from model repositories
May 26, 2023Deep learning models have become essential in software engineering, enabling intelligent features like image captioning and document generation. However, their popularity raises concerns about environmental impact and inefficient model selection. This paper introduces GreenRunnerGPT, a novel tool for efficiently selecting deep learning models based on specific use cases. It employs a large language model to suggest weights for quality indicators, optimizing resource utilization. The tool utilizes a multi-armed bandit framework to evaluate models against target datasets, considering tradeoffs. We demonstrate that GreenRunnerGPT is able to identify a model suited to a target use case without wasteful computations that would occur under a brute-force approach to model selection.
MLSmellHound: A Context-Aware Code Analysis Tool
May 08, 2022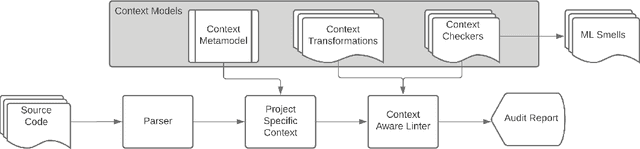
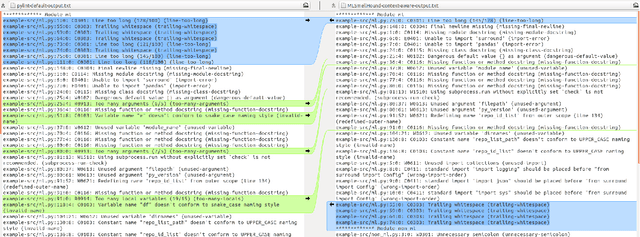
Meeting the rise of industry demand to incorporate machine learning (ML) components into software systems requires interdisciplinary teams contributing to a shared code base. To maintain consistency, reduce defects and ensure maintainability, developers use code analysis tools to aid them in identifying defects and maintaining standards. With the inclusion of machine learning, tools must account for the cultural differences within the teams which manifests as multiple programming languages, and conflicting definitions and objectives. Existing tools fail to identify these cultural differences and are geared towards software engineering which reduces their adoption in ML projects. In our approach we attempt to resolve this problem by exploring the use of context which includes i) purpose of the source code, ii) technical domain, iii) problem domain, iv) team norms, v) operational environment, and vi) development lifecycle stage to provide contextualised error reporting for code analysis. To demonstrate our approach, we adapt Pylint as an example and apply a set of contextual transformations to the linting results based on the domain of individual project files under analysis. This allows for contextualised and meaningful error reporting for the end-user.