 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Aware Development of Neuromorphic Implantables: From Metrics to Action
Jun 11, 2025Spiking Neural Networks (SNNs) and neuromorphic computing present a promising alternative to traditional Artificial Neural Networks (ANNs) by significantly improving energy efficiency, particularly in edge and implantable devices. However, assessing the energy performance of SNN models remains a challenge due to the lack of standardized and actionable metrics and the difficulty of measuring energy consumption in experimental neuromorphic hardware. In this paper, we conduct a preliminary exploratory study of energy efficiency metrics proposed in the SNN benchmarking literature. We classify 13 commonly used metrics based on four key properties: Accessibility, Fidelity, Actionability, and Trend-Based analysis. Our findings indicate that while many existing metrics provide useful comparisons between architectures, they often lack practical insights for SNN developers. Notably, we identify a gap between accessible and high-fidelity metrics, limiting early-stage energy assessment. Additionally, we emphasize the lack of metrics that provide practitioners with actionable insights, making it difficult to guide energy-efficient SNN development. To address these challenges, we outline research directions for bridging accessibility and fidelity and finding new Actionable metrics for implantable neuromorphic devices, introducing more Trend-Based metrics, metrics that reflect changes in power requirements, battery-aware metrics, and improving energy-performance tradeoff assessments. The results from this paper pave the way for future research on enhancing energy metrics and their Actionability for SNNs.
McUDI: Model-Centric Unsupervised Degradation Indicator for Failure Prediction AIOps Solutions
Jan 25, 2024Due to the continuous change in operational data, AIOps solutions suffer from performance degradation over time. Although periodic retraining is the state-of-the-art technique to preserve the failure prediction AIOps models' performance over time, this technique requires a considerable amount of labeled data to retrain. In AIOps obtaining label data is expensive since it requires the availability of domain experts to intensively annotate it. In this paper, we present McUDI, a model-centric unsupervised degradation indicator that is capable of detecting the exact moment the AIOps model requires retraining as a result of changes in data. We further show how employing McUDI in the maintenance pipeline of AIOps solutions can reduce the number of samples that require annotations with 30k for job failure prediction and 260k for disk failure prediction while achieving similar performance with periodic retraining.
Data vs. Model Machine Learning Fairness Testing: An Empirical Study
Jan 15, 2024Although several fairness definitions and bias mitigation techniques exist in the literature, all existing solutions evaluate fairness of Machine Learning (ML) systems after the training stage. In this paper, we take the first steps towards evaluating a more holistic approach by testing for fairness both before and after model training. We evaluate the effectiveness of the proposed approach and position it within the ML development lifecycle, using an empirical analysis of the relationship between model dependent and independent fairness metrics. The study uses 2 fairness metrics, 4 ML algorithms, 5 real-world datasets and 1600 fairness evaluation cycles. We find a linear relationship between data and model fairness metrics when the distribution and the size of the training data changes. Our results indicate that testing for fairness prior to training can be a ``cheap'' and effective means of catching a biased data collection process early; detecting data drifts in production systems and minimising execution of full training cycles thus reducing development time and costs.
Maintenance Techniques for Anomaly Detection AIOps Solutions
Nov 17, 2023Anomaly detection techniques are essential in automating the monitoring of IT systems and operations. These techniques imply that machine learning algorithms are trained on operational data corresponding to a specific period of time and that they are continuously evaluated on newly emerging data. Operational data is constantly changing over time, which affects the performance of deployed anomaly detection models. Therefore, continuous model maintenance is required to preserve the performance of anomaly detectors over time. In this work, we analyze two different anomaly detection model maintenance techniques in terms of the model update frequency, namely blind model retraining and informed model retraining. We further investigate the effects of updating the model by retraining it on all the available data (full-history approach) and on only the newest data (sliding window approach). Moreover, we investigate whether a data change monitoring tool is capable of determining when the anomaly detection model needs to be updated through retraining.
Green Runner: A tool for efficient model selection from model repositories
May 26, 2023Deep learning models have become essential in software engineering, enabling intelligent features like image captioning and document generation. However, their popularity raises concerns about environmental impact and inefficient model selection. This paper introduces GreenRunnerGPT, a novel tool for efficiently selecting deep learning models based on specific use cases. It employs a large language model to suggest weights for quality indicators, optimizing resource utilization. The tool utilizes a multi-armed bandit framework to evaluate models against target datasets, considering tradeoffs. We demonstrate that GreenRunnerGPT is able to identify a model suited to a target use case without wasteful computations that would occur under a brute-force approach to model selection.
Are Concept Drift Detectors Reliable Alarming Systems? -- A Comparative Study
Nov 23, 2022As machine learning models increasingly replace traditional business logic in the production system, their lifecycle management is becoming a significant concern. Once deployed into production, the machine learning models are constantly evaluated on new streaming data. Given the continuous data flow, shifting data, also known as concept drift, is ubiquitous in such settings. Concept drift usually impacts the performance of machine learning models, thus, identifying the moment when concept drift occurs is required. Concept drift is identified through concept drift detectors. In this work, we assess the reliability of concept drift detectors to identify drift in time by exploring how late are they reporting drifts and how many false alarms are they signaling. We compare the performance of the most popular drift detectors belonging to two different concept drift detector groups, error rate-based detectors and data distribution-based detectors. We assess their performance on both synthetic and real-world data. In the case of synthetic data, we investigate the performance of detectors to identify two types of concept drift, abrupt and gradual. Our findings aim to help practitioners understand which drift detector should be employed in different situations and, to achieve this, we share a list of the most important observations made throughout this study, which can serve as guidelines for practical usage. Furthermore, based on our empirical results, we analyze the suitability of each concept drift detection group to be used as alarming system.
Data Smells in Public Datasets
Mar 25, 2022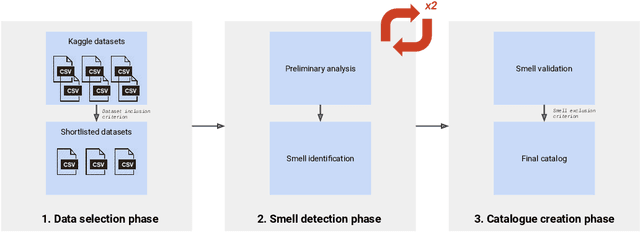
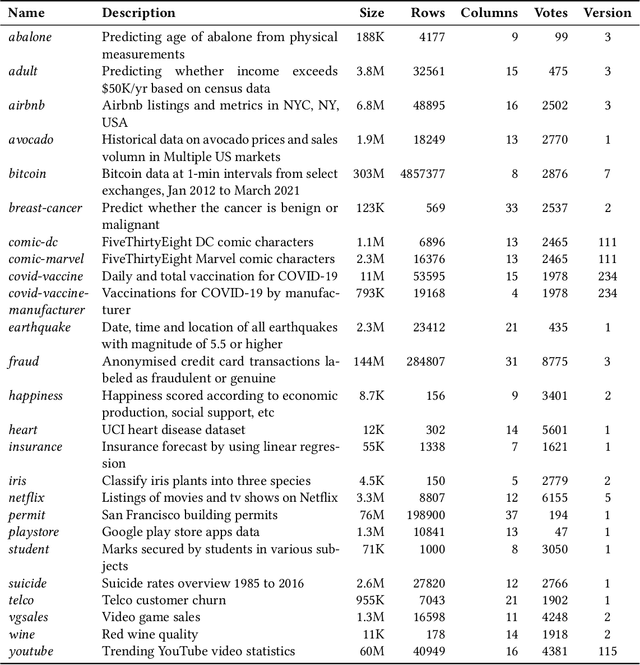

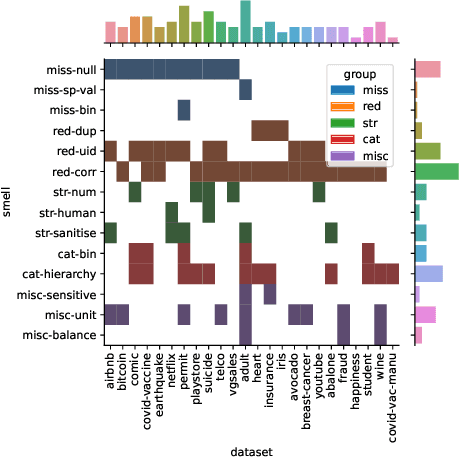
The adoption of Artificial Intelligence (AI) in high-stakes domains such as healthcare, wildlife preservation, autonomous driving and criminal justice system calls for a data-centric approach to AI. Data scientists spend the majority of their time studying and wrangling the data, yet tools to aid them with data analysis are lacking. This study identifies the recurrent data quality issues in public datasets. Analogous to code smells, we introduce a novel catalogue of data smells that can be used to indicate early signs of problems or technical debt in machine learning systems. To understand the prevalence of data quality issues in datasets, we analyse 25 public datasets and identify 14 data smells.