 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Middleware for Large Language Models
Nov 21, 2024



Large language models have gained widespread popularity for their ability to process natural language inputs and generate insights derived from their training data, nearing the qualities of true artificial intelligence. This advancement has prompted enterprises worldwide to integrate LLMs into their services. So far, this effort is dominated by commercial cloud-based solutions like OpenAI's ChatGPT and Microsoft Azure. As the technology matures, however, there is a strong incentive for independence from major cloud providers through self-hosting "LLM as a Service", driven by privacy, cost, and customization needs. In practice, hosting LLMs independently presents significant challenges due to their complexity and integration issues with existing systems. In this paper, we discuss our vision for a forward-looking middleware system architecture that facilitates the deployment and adoption of LLMs in enterprises, even for advanced use cases in which we foresee LLMs to serve as gateways to a complete application ecosystem and, to some degree, absorb functionality traditionally attributed to the middleware.
Multi-Unit Floor Plan Recognition and Reconstruction Using Improved Semantic Segmentation of Raster-Wise Floor Plans
Aug 02, 2024



Digital twins have a major potential to form a significant part of urban management in emergency planning, as they allow more efficient designing of the escape routes, better orientation in exceptional situations, and faster rescue intervention. Nevertheless, creating the twins still remains a largely manual effort, due to a lack of 3D-representations, which are available only in limited amounts for some new buildings. Thus, in this paper we aim to synthesize 3D information from commonly available 2D architectural floor plans. We propose two novel pixel-wise segmentation methods based on the MDA-Unet and MACU-Net architectures with improved skip connections, an attention mechanism, and a training objective together with a reconstruction part of the pipeline, which vectorizes the segmented plans to create a 3D model. The proposed methods are compared with two other state-of-the-art techniques and several benchmark datasets. On the commonly used CubiCasa benchmark dataset, our methods have achieved the mean F1 score of 0.86 over five examined classes, outperforming the other pixel-wise approaches tested. We have also made our code publicly available to support research in the field.
Are Concept Drift Detectors Reliable Alarming Systems? -- A Comparative Study
Nov 23, 2022As machine learning models increasingly replace traditional business logic in the production system, their lifecycle management is becoming a significant concern. Once deployed into production, the machine learning models are constantly evaluated on new streaming data. Given the continuous data flow, shifting data, also known as concept drift, is ubiquitous in such settings. Concept drift usually impacts the performance of machine learning models, thus, identifying the moment when concept drift occurs is required. Concept drift is identified through concept drift detectors. In this work, we assess the reliability of concept drift detectors to identify drift in time by exploring how late are they reporting drifts and how many false alarms are they signaling. We compare the performance of the most popular drift detectors belonging to two different concept drift detector groups, error rate-based detectors and data distribution-based detectors. We assess their performance on both synthetic and real-world data. In the case of synthetic data, we investigate the performance of detectors to identify two types of concept drift, abrupt and gradual. Our findings aim to help practitioners understand which drift detector should be employed in different situations and, to achieve this, we share a list of the most important observations made throughout this study, which can serve as guidelines for practical usage. Furthermore, based on our empirical results, we analyze the suitability of each concept drift detection group to be used as alarming system.
Roadmap for Edge AI: A Dagstuhl Perspective
Nov 27, 2021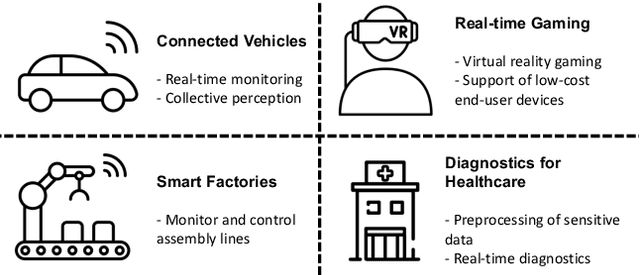
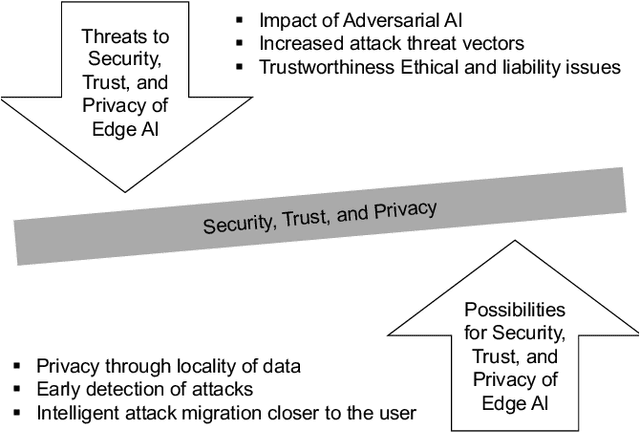
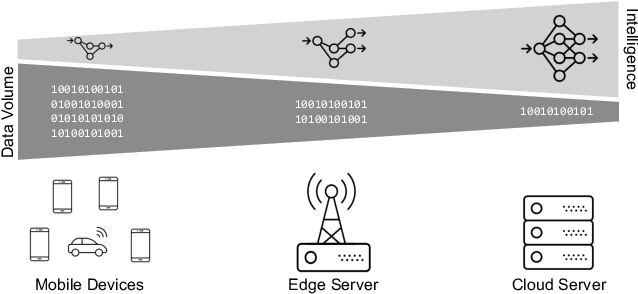

Based on the collective input of Dagstuhl Seminar (21342), this paper presents a comprehensive discussion on AI methods and capabilities in the context of edge computing, referred as Edge AI. In a nutshell, we envision Edge AI to provide adaptation for data-driven applications, enhance network and radio access, and allow the creation, optimization, and deployment of distributed AI/ML pipelines with given quality of experience, trust, security and privacy targets. The Edge AI community investigates novel ML methods for the edge computing environment, spanning multiple sub-fields of computer science, engineering and ICT. The goal is to share an envisioned roadmap that can bring together key actors and enablers to further advance the domain of Edge AI.
RCURRENCY: Live Digital Asset Trading Using a Recurrent Neural Network-based Forecasting System
Jun 13, 2021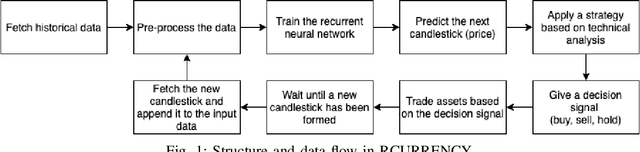
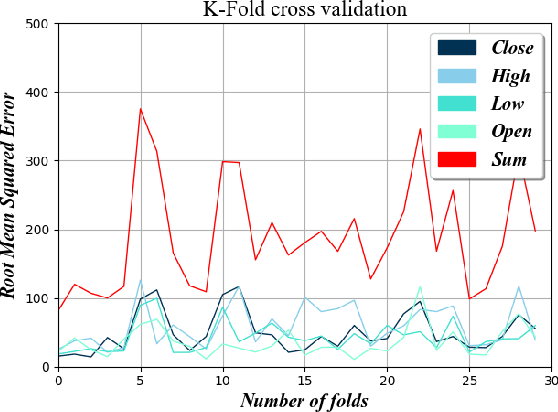

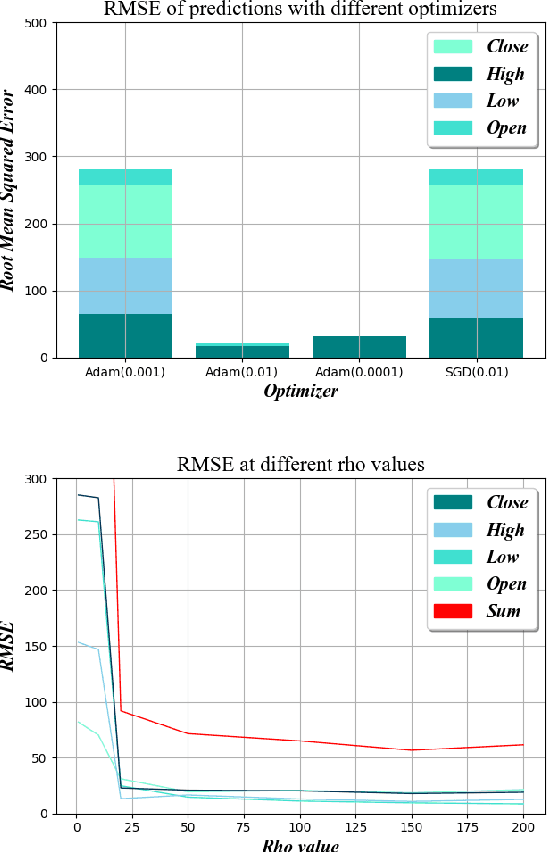
Consistent alpha generation, i.e., maintaining an edge over the market, underpins the ability of asset traders to reliably generate profits. Technical indicators and trading strategies are commonly used tools to determine when to buy/hold/sell assets, yet these are limited by the fact that they operate on known values. Over the past decades, multiple studies have investigated the potential of artificial intelligence in stock trading in conventional markets, with some success. In this paper, we present RCURRENCY, an RNN-based trading engine to predict data in the highly volatile digital asset market which is able to successfully manage an asset portfolio in a live environment. By combining asset value prediction and conventional trading tools, RCURRENCY determines whether to buy, hold or sell digital currencies at a given point in time. Experimental results show that, given the data of an interval $t$, a prediction with an error of less than 0.5\% of the data at the subsequent interval $t+1$ can be obtained. Evaluation of the system through backtesting shows that RCURRENCY can be used to successfully not only maintain a stable portfolio of digital assets in a simulated live environment using real historical trading data but even increase the portfolio value over time.
Systematic Mapping Study on the Machine Learning Lifecycle
Mar 11, 2021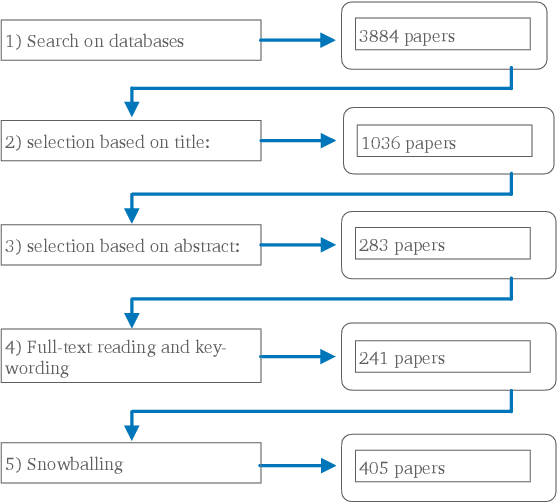
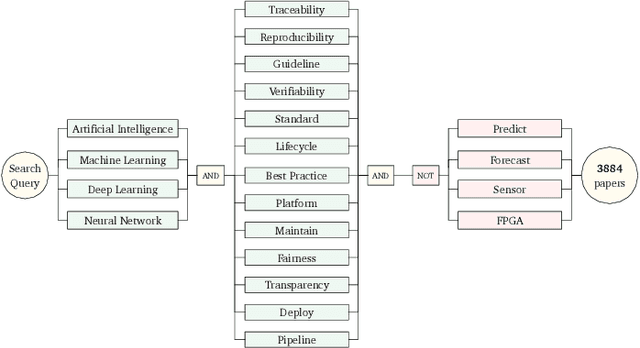

The development of artificial intelligence (AI) has made various industries eager to explore the benefits of AI. There is an increasing amount of research surrounding AI, most of which is centred on the development of new AI algorithms and techniques. However, the advent of AI is bringing an increasing set of practical problems related to AI model lifecycle management that need to be investigated. We address this gap by conducting a systematic mapping study on the lifecycle of AI model. Through quantitative research, we provide an overview of the field, identify research opportunities, and provide suggestions for future research. Our study yields 405 publications published from 2005 to 2020, mapped in 5 different main research topics, and 31 sub-topics. We observe that only a minority of publications focus on data management and model production problems, and that more studies should address the AI lifecycle from a holistic perspective.
A Survey on Distributed Machine Learning
Dec 20, 2019



The demand for artificial intelligence has grown significantly over the last decade and this growth has been fueled by advances in machine learning techniques and the ability to leverage hardware acceleration. However, in order to increase the quality of predictions and render machine learning solutions feasible for more complex applications, a substantial amount of training data is required. Although small machine learning models can be trained with modest amounts of data, the input for training larger models such as neural networks grows exponentially with the number of parameters. Since the demand for processing training data has outpaced the increase in computation power of computing machinery, there is a need for distributing the machine learning workload across multiple machines, and turning the centralized into a distributed system. These distributed systems present new challenges, first and foremost the efficient parallelization of the training process and the creation of a coherent model. This article provides an extensive overview of the current state-of-the-art in the field by outlining the challenges and opportunities of distributed machine learning over conventional (centralized) machine learning, discussing the techniques used for distributed machine learning, and providing an overview of the systems that are available.