 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Middleware for Large Language Models
Nov 21, 2024



Large language models have gained widespread popularity for their ability to process natural language inputs and generate insights derived from their training data, nearing the qualities of true artificial intelligence. This advancement has prompted enterprises worldwide to integrate LLMs into their services. So far, this effort is dominated by commercial cloud-based solutions like OpenAI's ChatGPT and Microsoft Azure. As the technology matures, however, there is a strong incentive for independence from major cloud providers through self-hosting "LLM as a Service", driven by privacy, cost, and customization needs. In practice, hosting LLMs independently presents significant challenges due to their complexity and integration issues with existing systems. In this paper, we discuss our vision for a forward-looking middleware system architecture that facilitates the deployment and adoption of LLMs in enterprises, even for advanced use cases in which we foresee LLMs to serve as gateways to a complete application ecosystem and, to some degree, absorb functionality traditionally attributed to the middleware.
Functional Indirection Neural Estimator for Better Out-of-distribution Generalization
Oct 23, 2022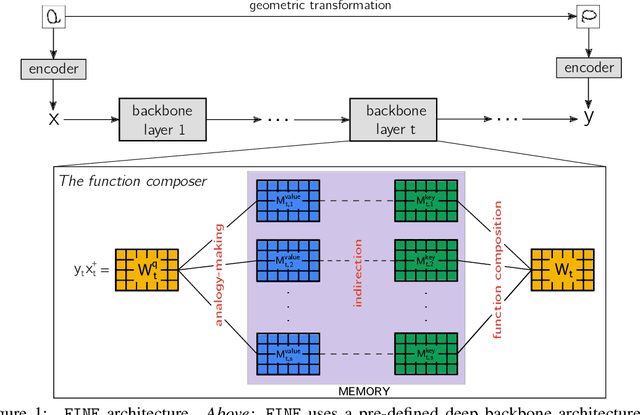
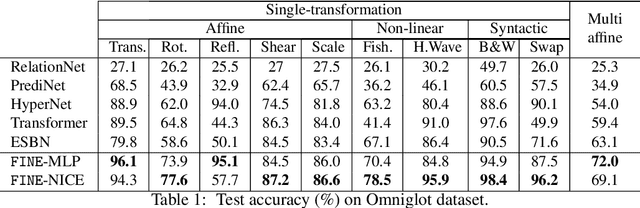
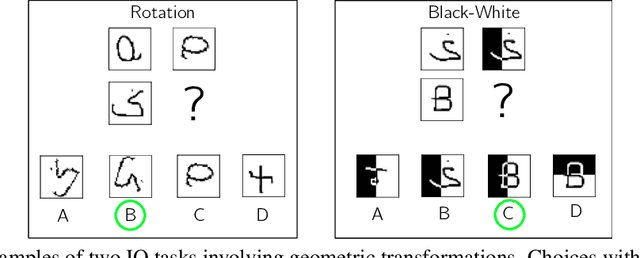
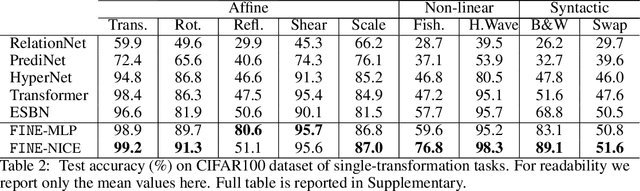
The capacity to achieve out-of-distribution (OOD) generalization is a hallmark of human intelligence and yet remains out of reach for machines. This remarkable capability has been attributed to our abilities to make conceptual abstraction and analogy, and to a mechanism known as indirection, which binds two representations and uses one representation to refer to the other. Inspired by these mechanisms, we hypothesize that OOD generalization may be achieved by performing analogy-making and indirection in the functional space instead of the data space as in current methods. To realize this, we design FINE (Functional Indirection Neural Estimator), a neural framework that learns to compose functions that map data input to output on-the-fly. FINE consists of a backbone network and a trainable semantic memory of basis weight matrices. Upon seeing a new input-output data pair, FINE dynamically constructs the backbone weights by mixing the basis weights. The mixing coefficients are indirectly computed through querying a separate corresponding semantic memory using the data pair. We demonstrate empirically that FINE can strongly improve out-of-distribution generalization on IQ tasks that involve geometric transformations. In particular, we train FINE and competing models on IQ tasks using images from the MNIST, Omniglot and CIFAR100 datasets and test on tasks with unseen image classes from one or different datasets and unseen transformation rules. FINE not only achieves the best performance on all tasks but also is able to adapt to small-scale data scenarios.