 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing the human touch? A computational stylometry analysis of GPT-4 translations of online Chinese literature
Jun 16, 2025Existing research indicates that machine translations (MTs) of literary texts are often unsatisfactory. MTs are typically evaluated using automated metrics and subjective human ratings, with limited focus on stylistic features. Evidence is also limited on whether state-of-the-art large language models (LLMs) will reshape literary translation. This study examines the stylistic features of LLM translations, comparing GPT-4's performance to human translations in a Chinese online literature task. Computational stylometry analysis shows that GPT-4 translations closely align with human translations in lexical, syntactic, and content features, suggesting that LLMs might replicate the 'human touch' in literary translation style. These findings offer insights into AI's impact on literary translation from a posthuman perspective, where distinctions between machine and human translations become increasingly blurry.
CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs
Dec 16, 2021We present CrossSum, a large-scale dataset comprising 1.65 million cross-lingual article-summary samples in 1500+ language-pairs constituting 45 languages. We use the multilingual XL-Sum dataset and align identical articles written in different languages via cross-lingual retrieval using a language-agnostic representation model. We propose a multi-stage data sampling algorithm and fine-tune mT5, a multilingual pretrained model, with explicit cross-lingual supervision with CrossSum and introduce a new metric for evaluating cross-lingual summarization. Results on established and our proposed metrics indicate that models fine-tuned on CrossSum outperforms summarization+translation baselines, even when the source and target language pairs are linguistically distant. To the best of our knowledge, CrossSum is the largest cross-lingual summarization dataset and also the first-ever that does not rely on English as the pivot language. We are releasing the dataset, alignment and training scripts, and the models to spur future research on cross-lingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/CrossSum}.
An AI-based Solution for Enhancing Delivery of Digital Learning for Future Teachers
Nov 09, 2021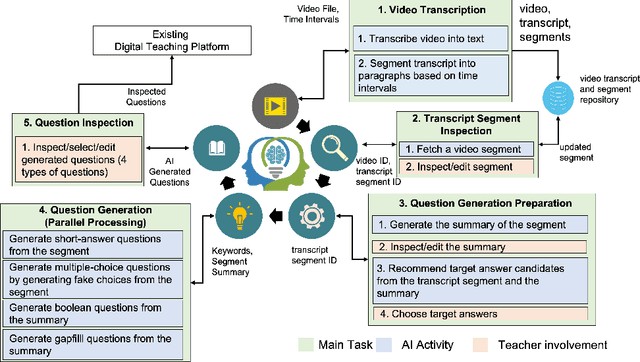

There has been a recent and rapid shift to digital learning hastened by the pandemic but also influenced by ubiquitous availability of digital tools and platforms now, making digital learning ever more accessible. An integral and one of the most difficult part of scaling digital learning and teaching is to be able to assess learner's knowledge and competency. An educator can record a lecture or create digital content that can be delivered to thousands of learners but assessing learners is extremely time consuming. In the paper, we propose an Artificial Intelligence (AI)-based solution namely VidVersityQG for generating questions automatically from pre-recorded video lectures. The solution can automatically generate different types of assessment questions (including short answer, multiple choice, true/false and fill in the blank questions) based on contextual and semantic information inferred from the videos. The proposed solution takes a human-centred approach, wherein teachers are provided the ability to modify/edit any AI generated questions. This approach encourages trust and engagement of teachers in the use and implementation of AI in education. The AI-based solution was evaluated for its accuracy in generating questions by 7 experienced teaching professionals and 117 education videos from multiple domains provided to us by our industry partner VidVersity. VidVersityQG solution showed promising results in generating high-quality questions automatically from video thereby significantly reducing the time and effort for educators in manual question generation.
XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
Jun 25, 2021
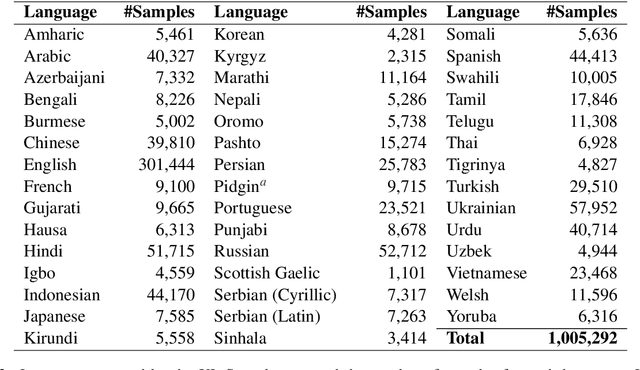
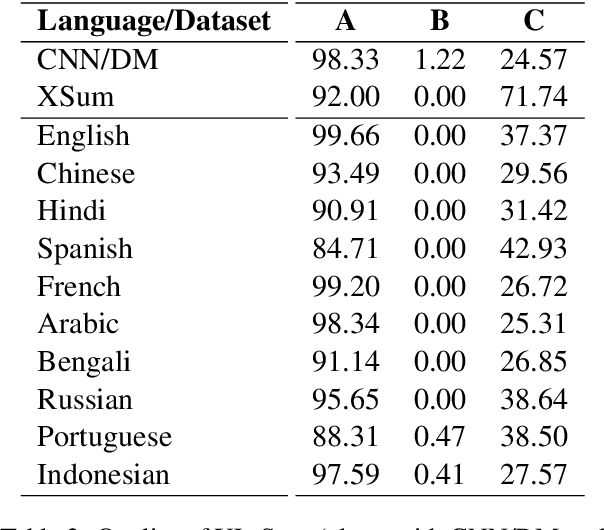
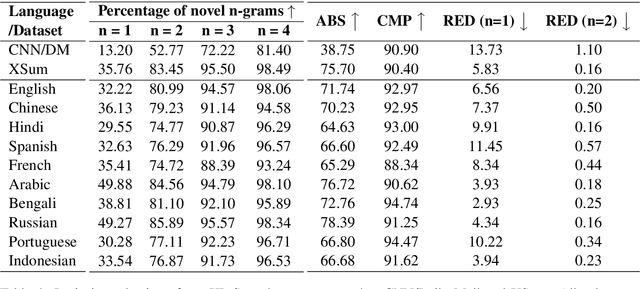
Contemporary works on abstractive text summarization have focused primarily on high-resource languages like English, mostly due to the limited availability of datasets for low/mid-resource ones. In this work, we present XL-Sum, a comprehensive and diverse dataset comprising 1 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 44 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation. We fine-tune mT5, a state-of-the-art pretrained multilingual model, with XL-Sum and experiment on multilingual and low-resource summarization tasks. XL-Sum induces competitive results compared to the ones obtained using similar monolingual datasets: we show higher than 11 ROUGE-2 scores on 10 languages we benchmark on, with some of them exceeding 15, as obtained by multilingual training. Additionally, training on low-resource languages individually also provides competitive performance. To the best of our knowledge, XL-Sum is the largest abstractive summarization dataset in terms of the number of samples collected from a single source and the number of languages covered. We are releasing our dataset and models to encourage future research on multilingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/xl-sum}.
An open-source framework for ExpFinder integrating $N$-gram Vector Space Model and $μ$CO-HITS
Mar 11, 2021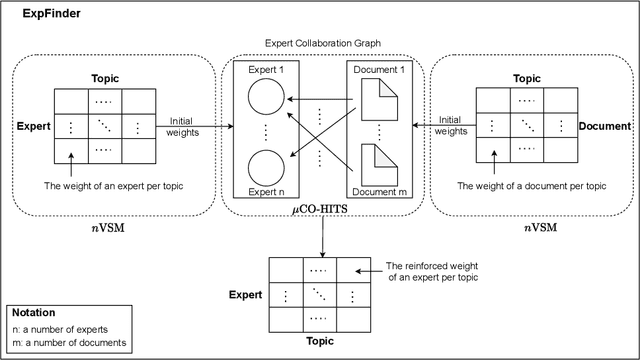

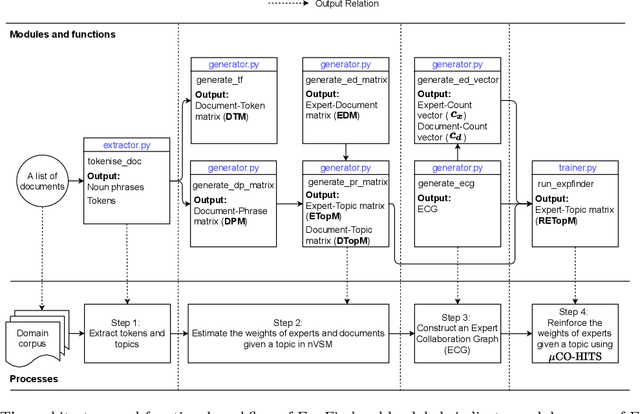
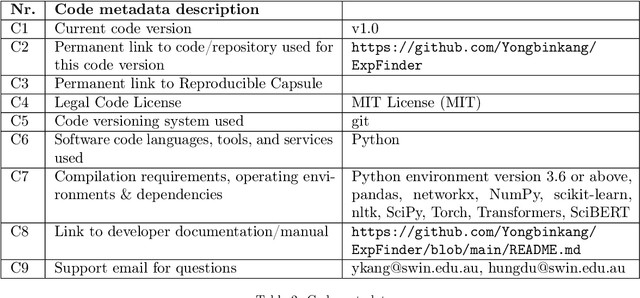
Finding experts drives successful collaborations and high-quality product development in academic and research domains. To contribute to the expert finding research community, we have developed ExpFinder which is a novel ensemble model for expert finding by integrating an $N$-gram vector space model ($n$VSM) and a graph-based model ($\mu$CO-HITS). This paper provides descriptions of ExpFinder's architecture, key components, functionalities, and illustrative examples. ExpFinder is an effective and competitive model for expert finding, significantly outperforming a number of expert finding models.
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021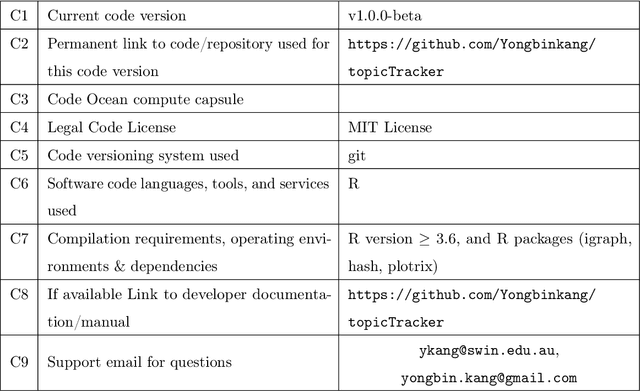
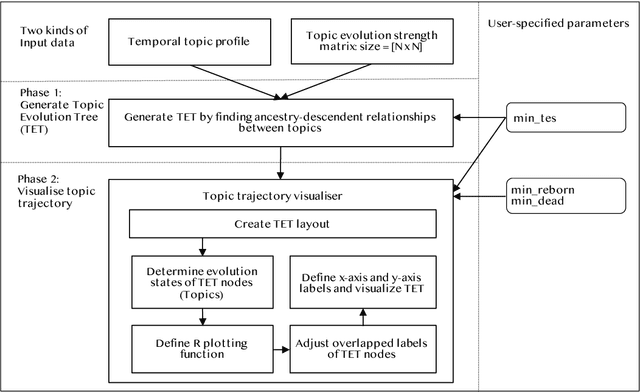
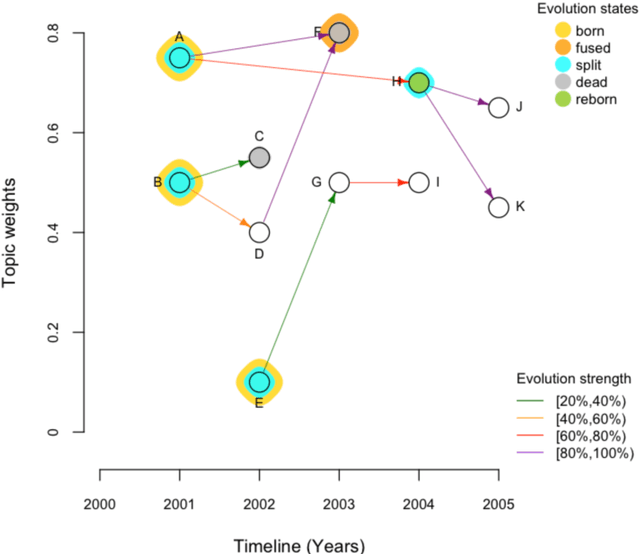
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
CorrDetector: A Framework for Structural Corrosion Detection from Drone Images using Ensemble Deep Learning
Feb 09, 2021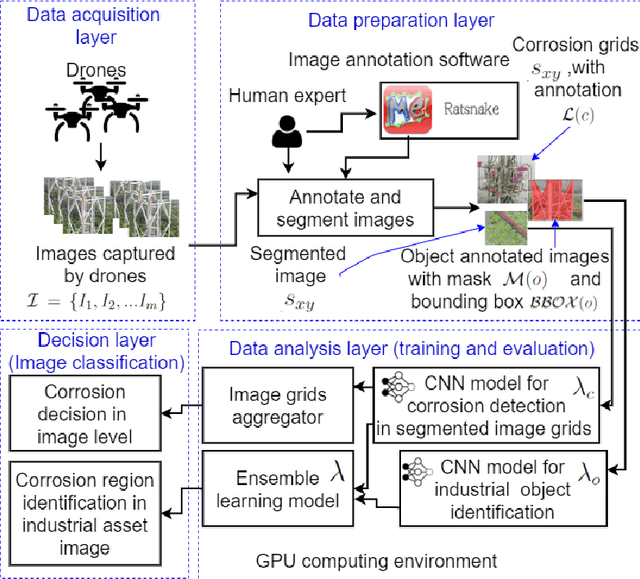

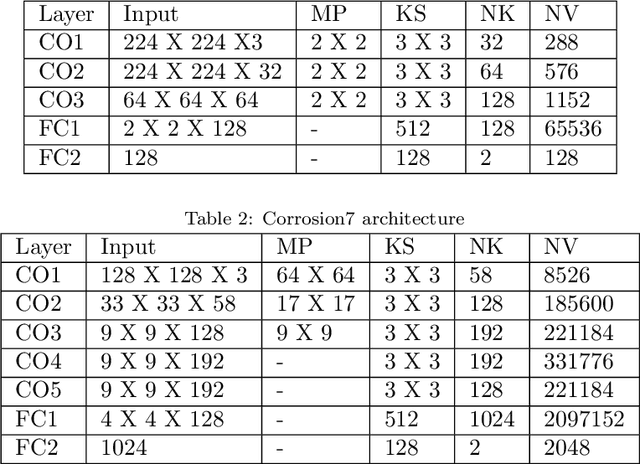
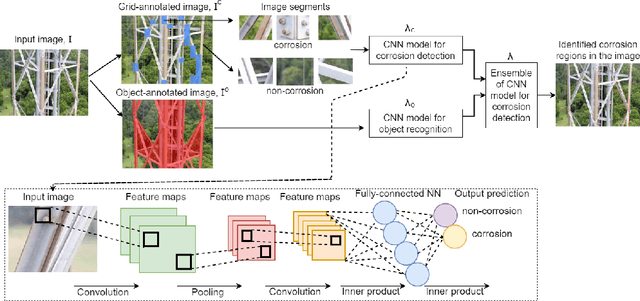
In this paper, we propose a new technique that applies automated image analysis in the area of structural corrosion monitoring and demonstrate improved efficacy compared to existing approaches. Structural corrosion monitoring is the initial step of the risk-based maintenance philosophy and depends on an engineer's assessment regarding the risk of building failure balanced against the fiscal cost of maintenance. This introduces the opportunity for human error which is further complicated when restricted to assessment using drone captured images for those areas not reachable by humans due to many background noises. The importance of this problem has promoted an active research community aiming to support the engineer through the use of artificial intelligence (AI) image analysis for corrosion detection. In this paper, we advance this area of research with the development of a framework, CorrDetector. CorrDetector uses a novel ensemble deep learning approach underpinned by convolutional neural networks (CNNs) for structural identification and corrosion feature extraction. We provide an empirical evaluation using real-world images of a complicated structure (e.g. telecommunication tower) captured by drones, a typical scenario for engineers. Our study demonstrates that the ensemble approach of \model significantly outperforms the state-of-the-art in terms of classification accuracy.
ExpFinder: An Ensemble Expert Finding Model Integrating $N$-gram Vector Space Model and $μ$CO-HITS
Jan 18, 2021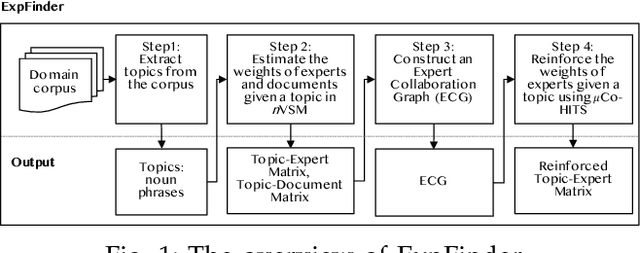
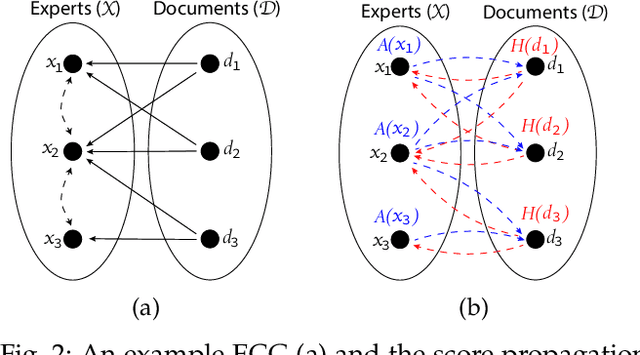

Finding an expert plays a crucial role in driving successful collaborations and speeding up high-quality research development and innovations. However, the rapid growth of scientific publications and digital expertise data makes identifying the right experts a challenging problem. Existing approaches for finding experts given a topic can be categorised into information retrieval techniques based on vector space models, document language models, and graph-based models. In this paper, we propose $\textit{ExpFinder}$, a new ensemble model for expert finding, that integrates a novel $N$-gram vector space model, denoted as $n$VSM, and a graph-based model, denoted as $\textit{$\mu$CO-HITS}$, that is a proposed variation of the CO-HITS algorithm. The key of $n$VSM is to exploit recent inverse document frequency weighting method for $N$-gram words and $\textit{ExpFinder}$ incorporates $n$VSM into $\textit{$\mu$CO-HITS}$ to achieve expert finding. We comprehensively evaluate $\textit{ExpFinder}$ on four different datasets from the academic domains in comparison with six different expert finding models. The evaluation results show that $\textit{ExpFinder}$ is a highly effective model for expert finding, substantially outperforming all the compared models in 19% to 160.2%.
Boosting House Price Predictions using Geo-Spatial Network Embedding
Sep 01, 2020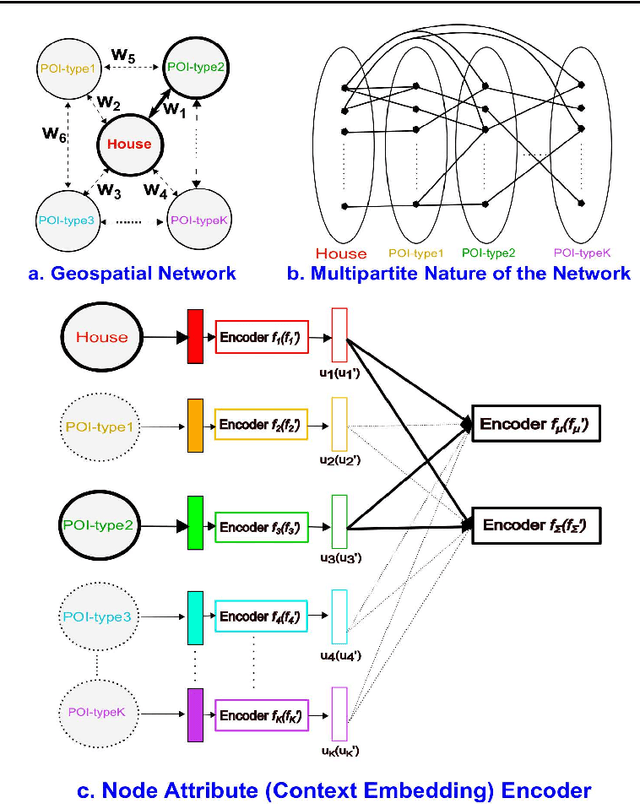

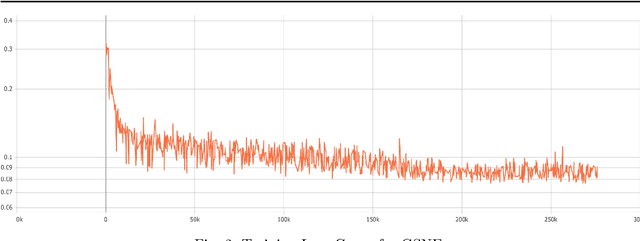
Real estate contributes significantly to all major economies around the world. In particular, house prices have a direct impact on stakeholders, ranging from house buyers to financing companies. Thus, a plethora of techniques have been developed for real estate price prediction. Most of the existing techniques rely on different house features to build a variety of prediction models to predict house prices. Perceiving the effect of spatial dependence on house prices, some later works focused on introducing spatial regression models for improving prediction performance. However, they fail to take into account the geo-spatial context of the neighborhood amenities such as how close a house is to a train station, or a highly-ranked school, or a shopping center. Such contextual information may play a vital role in users' interests in a house and thereby has a direct influence on its price. In this paper, we propose to leverage the concept of graph neural networks to capture the geo-spatial context of the neighborhood of a house. In particular, we present a novel method, the Geo-Spatial Network Embedding (GSNE), that learns the embeddings of houses and various types of Points of Interest (POIs) in the form of multipartite networks, where the houses and the POIs are represented as attributed nodes and the relationships between them as edges. Extensive experiments with a large number of regression techniques show that the embeddings produced by our proposed GSNE technique consistently and significantly improve the performance of the house price prediction task regardless of the downstream regression model.
Keyword Aware Influential Community Search in Large Attributed Graphs
Dec 04, 2019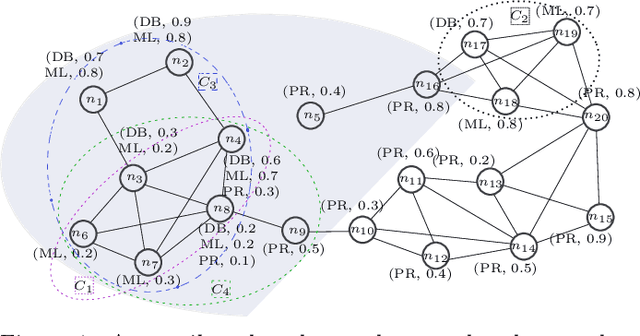

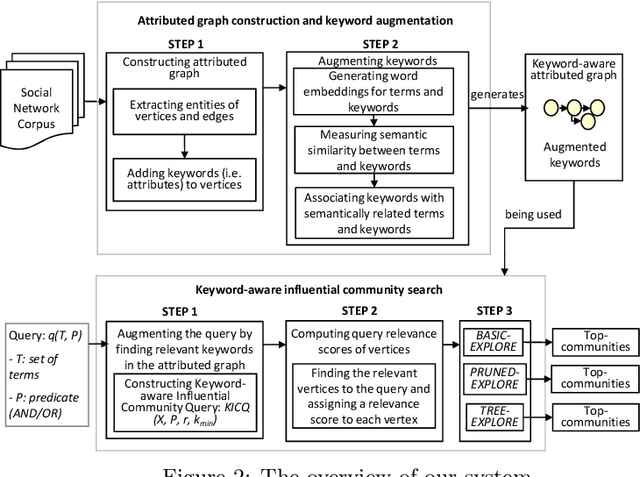

We introduce a novel keyword-aware influential community query KICQ that finds the most influential communities from an attributed graph, where an influential community is defined as a closely connected group of vertices having some dominance over other groups of vertices with the expertise (a set of keywords) matching with the query terms (words or phrases). We first design the KICQ that facilitates users to issue an influential CS query intuitively by using a set of query terms, and predicates (AND or OR). In this context, we propose a novel word-embedding based similarity model that enables semantic community search, which substantially alleviates the limitations of exact keyword based community search. Next, we propose a new influence measure for a community that considers both the cohesiveness and influence of the community and eliminates the need for specifying values of internal parameters of a network. Finally, we propose two efficient algorithms for searching influential communities in large attributed graphs. We present detailed experiments and a case study to demonstrate the effectiveness and efficiency of the proposed approaches.