 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report on classification of literature related to children speech disorder
May 20, 2025This technical report presents a natural language processing (NLP)-based approach for systematically classifying scientific literature on childhood speech disorders. We retrieved and filtered 4,804 relevant articles published after 2015 from the PubMed database using domain-specific keywords. After cleaning and pre-processing the abstracts, we applied two topic modeling techniques - Latent Dirichlet Allocation (LDA) and BERTopic - to identify latent thematic structures in the corpus. Our models uncovered 14 clinically meaningful clusters, such as infantile hyperactivity and abnormal epileptic behavior. To improve relevance and precision, we incorporated a custom stop word list tailored to speech pathology. Evaluation results showed that the LDA model achieved a coherence score of 0.42 and a perplexity of -7.5, indicating strong topic coherence and predictive performance. The BERTopic model exhibited a low proportion of outlier topics (less than 20%), demonstrating its capacity to classify heterogeneous literature effectively. These results provide a foundation for automating literature reviews in speech-language pathology.
Combining Knowledge Graphs and Large Language Models
Jul 09, 2024



In recent years, Natural Language Processing (NLP) has played a significant role in various Artificial Intelligence (AI) applications such as chatbots, text generation, and language translation. The emergence of large language models (LLMs) has greatly improved the performance of these applications, showing astonishing results in language understanding and generation. However, they still show some disadvantages, such as hallucinations and lack of domain-specific knowledge, that affect their performance in real-world tasks. These issues can be effectively mitigated by incorporating knowledge graphs (KGs), which organise information in structured formats that capture relationships between entities in a versatile and interpretable fashion. Likewise, the construction and validation of KGs present challenges that LLMs can help resolve. The complementary relationship between LLMs and KGs has led to a trend that combines these technologies to achieve trustworthy results. This work collected 28 papers outlining methods for KG-powered LLMs, LLM-based KGs, and LLM-KG hybrid approaches. We systematically analysed and compared these approaches to provide a comprehensive overview highlighting key trends, innovative techniques, and common challenges. This synthesis will benefit researchers new to the field and those seeking to deepen their understanding of how KGs and LLMs can be effectively combined to enhance AI applications capabilities.
A Rapid Review of Clustering Algorithms
Jan 14, 2024Clustering algorithms aim to organize data into groups or clusters based on the inherent patterns and similarities within the data. They play an important role in today's life, such as in marketing and e-commerce, healthcare, data organization and analysis, and social media. Numerous clustering algorithms exist, with ongoing developments introducing new ones. Each algorithm possesses its own set of strengths and weaknesses, and as of now, there is no universally applicable algorithm for all tasks. In this work, we analyzed existing clustering algorithms and classify mainstream algorithms across five different dimensions: underlying principles and characteristics, data point assignment to clusters, dataset capacity, predefined cluster numbers and application area. This classification facilitates researchers in understanding clustering algorithms from various perspectives and helps them identify algorithms suitable for solving specific tasks. Finally, we discussed the current trends and potential future directions in clustering algorithms. We also identified and discussed open challenges and unresolved issues in the field.
Leveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023

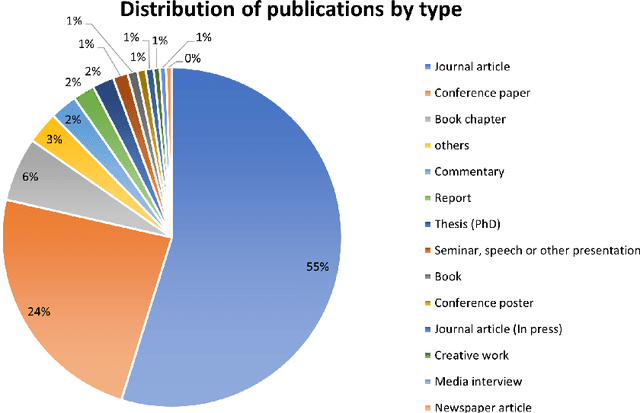

The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
ExpFinder: An Ensemble Expert Finding Model Integrating $N$-gram Vector Space Model and $μ$CO-HITS
Jan 18, 2021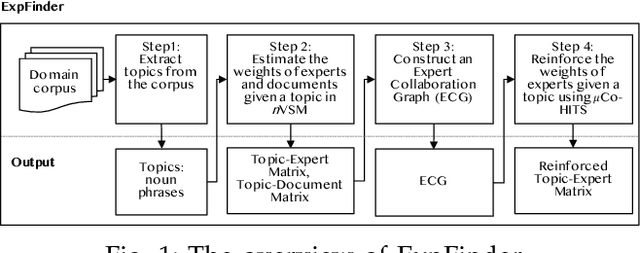
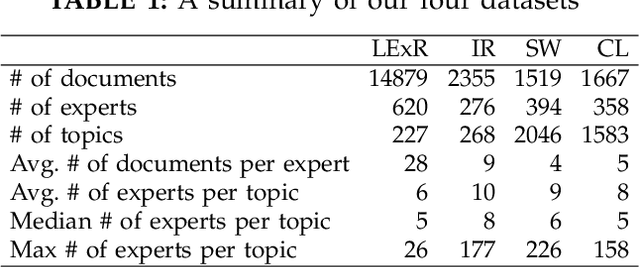
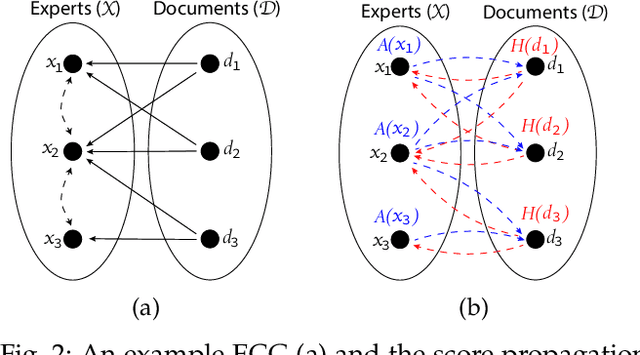

Finding an expert plays a crucial role in driving successful collaborations and speeding up high-quality research development and innovations. However, the rapid growth of scientific publications and digital expertise data makes identifying the right experts a challenging problem. Existing approaches for finding experts given a topic can be categorised into information retrieval techniques based on vector space models, document language models, and graph-based models. In this paper, we propose $\textit{ExpFinder}$, a new ensemble model for expert finding, that integrates a novel $N$-gram vector space model, denoted as $n$VSM, and a graph-based model, denoted as $\textit{$\mu$CO-HITS}$, that is a proposed variation of the CO-HITS algorithm. The key of $n$VSM is to exploit recent inverse document frequency weighting method for $N$-gram words and $\textit{ExpFinder}$ incorporates $n$VSM into $\textit{$\mu$CO-HITS}$ to achieve expert finding. We comprehensively evaluate $\textit{ExpFinder}$ on four different datasets from the academic domains in comparison with six different expert finding models. The evaluation results show that $\textit{ExpFinder}$ is a highly effective model for expert finding, substantially outperforming all the compared models in 19% to 160.2%.