 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
Jun 25, 2021
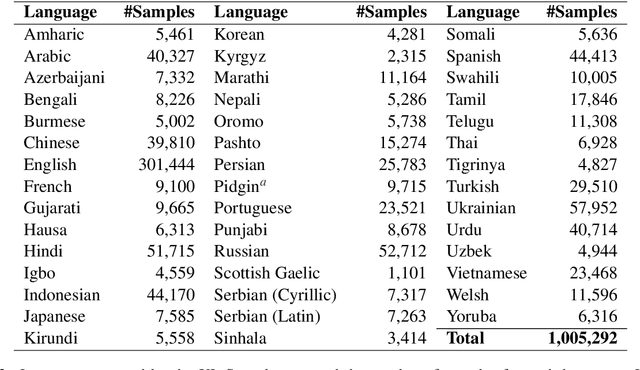
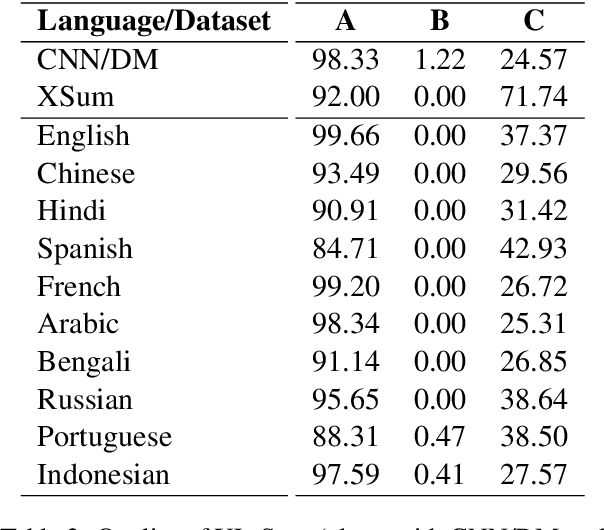
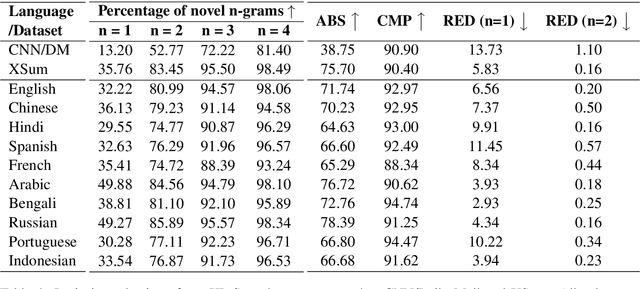
Contemporary works on abstractive text summarization have focused primarily on high-resource languages like English, mostly due to the limited availability of datasets for low/mid-resource ones. In this work, we present XL-Sum, a comprehensive and diverse dataset comprising 1 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 44 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation. We fine-tune mT5, a state-of-the-art pretrained multilingual model, with XL-Sum and experiment on multilingual and low-resource summarization tasks. XL-Sum induces competitive results compared to the ones obtained using similar monolingual datasets: we show higher than 11 ROUGE-2 scores on 10 languages we benchmark on, with some of them exceeding 15, as obtained by multilingual training. Additionally, training on low-resource languages individually also provides competitive performance. To the best of our knowledge, XL-Sum is the largest abstractive summarization dataset in terms of the number of samples collected from a single source and the number of languages covered. We are releasing our dataset and models to encourage future research on multilingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/xl-sum}.
BanglaBERT: Combating Embedding Barrier for Low-Resource Language Understanding
Jan 01, 2021Pre-training language models on large volume of data with self-supervised objectives has become a standard practice in natural language processing. However, most such state-of-the-art models are available in only English and other resource-rich languages. Even in multilingual models, which are trained on hundreds of languages, low-resource ones still remain underrepresented. Bangla, the seventh most widely spoken language in the world, is still low in terms of resources. Few downstream task datasets for language understanding in Bangla are publicly available, and there is a clear shortage of good quality data for pre-training. In this work, we build a Bangla natural language understanding model pre-trained on 18.6 GB data we crawled from top Bangla sites on the internet. We introduce a new downstream task dataset and benchmark on four tasks on sentence classification, document classification, natural language understanding, and sequence tagging. Our model outperforms multilingual baselines and previous state-of-the-art results by 1-6%. In the process, we identify a major shortcoming of multilingual models that hurt performance for low-resource languages that don't share writing scripts with any high resource one, which we name the `Embedding Barrier'. We perform extensive experiments to study this barrier. We release all our datasets and pre-trained models to aid future NLP research on Bangla and other low-resource languages. Our code and data are available at https://github.com/csebuetnlp/banglabert.
Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for Bengali-English Machine Translation
Oct 07, 2020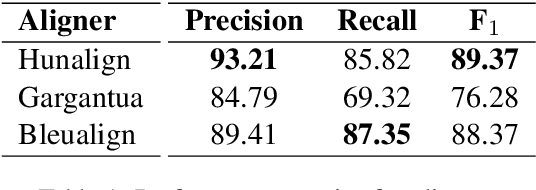
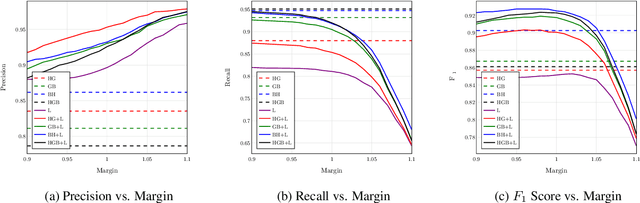
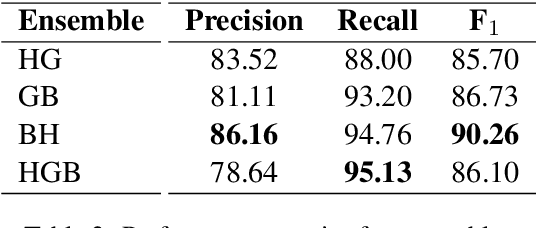
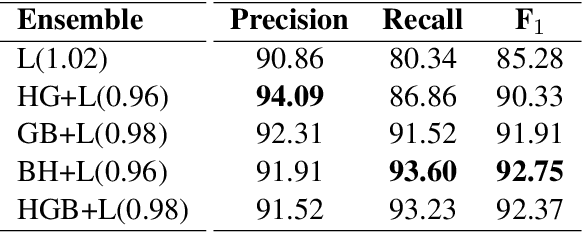
Despite being the seventh most widely spoken language in the world, Bengali has received much less attention in machine translation literature due to being low in resources. Most publicly available parallel corpora for Bengali are not large enough; and have rather poor quality, mostly because of incorrect sentence alignments resulting from erroneous sentence segmentation, and also because of a high volume of noise present in them. In this work, we build a customized sentence segmenter for Bengali and propose two novel methods for parallel corpus creation on low-resource setups: aligner ensembling and batch filtering. With the segmenter and the two methods combined, we compile a high-quality Bengali-English parallel corpus comprising of 2.75 million sentence pairs, more than 2 million of which were not available before. Training on neural models, we achieve an improvement of more than 9 BLEU score over previous approaches to Bengali-English machine translation. We also evaluate on a new test set of 1000 pairs made with extensive quality control. We release the segmenter, parallel corpus, and the evaluation set, thus elevating Bengali from its low-resource status. To the best of our knowledge, this is the first ever large scale study on Bengali-English machine translation. We believe our study will pave the way for future research on Bengali-English machine translation as well as other low-resource languages. Our data and code are available at https://github.com/csebuetnlp/banglanmt.