 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainRotViT: Transformer-ResNet Hybrid for Explainable Modeling of Brain Aging from 3D sMRI
Nov 19, 2025Accurate brain age estimation from structural MRI is a valuable biomarker for studying aging and neurodegeneration. Traditional regression and CNN-based methods face limitations such as manual feature engineering, limited receptive fields, and overfitting on heterogeneous data. Pure transformer models, while effective, require large datasets and high computational cost. We propose Brain ResNet over trained Vision Transformer (BrainRotViT), a hybrid architecture that combines the global context modeling of vision transformers (ViT) with the local refinement of residual CNNs. A ViT encoder is first trained on an auxiliary age and sex classification task to learn slice-level features. The frozen encoder is then applied to all sagittal slices to generate a 2D matrix of embedding vectors, which is fed into a residual CNN regressor that incorporates subject sex at the final fully-connected layer to estimate continuous brain age. Our method achieves an MAE of 3.34 years (Pearson $r=0.98$, Spearman $ρ=0.97$, $R^2=0.95$) on validation across 11 MRI datasets encompassing more than 130 acquisition sites, outperforming baseline and state-of-the-art models. It also generalizes well across 4 independent cohorts with MAEs between 3.77 and 5.04 years. Analyses on the brain age gap (the difference between the predicted age and actual age) show that aging patterns are associated with Alzheimer's disease, cognitive impairment, and autism spectrum disorder. Model attention maps highlight aging-associated regions of the brain, notably the cerebellar vermis, precentral and postcentral gyri, temporal lobes, and medial superior frontal gyrus. Our results demonstrate that this method provides an efficient, interpretable, and generalizable framework for brain-age prediction, bridging the gap between CNN- and transformer-based approaches while opening new avenues for aging and neurodegeneration research.
Entropy-Driven Genetic Optimization for Deep-Feature-Guided Low-Light Image Enhancement
May 16, 2025Image enhancement methods often prioritize pixel level information, overlooking the semantic features. We propose a novel, unsupervised, fuzzy-inspired image enhancement framework guided by NSGA-II algorithm that optimizes image brightness, contrast, and gamma parameters to achieve a balance between visual quality and semantic fidelity. Central to our proposed method is the use of a pre trained deep neural network as a feature extractor. To find the best enhancement settings, we use a GPU-accelerated NSGA-II algorithm that balances multiple objectives, namely, increasing image entropy, improving perceptual similarity, and maintaining appropriate brightness. We further improve the results by applying a local search phase to fine-tune the top candidates from the genetic algorithm. Our approach operates entirely without paired training data making it broadly applicable across domains with limited or noisy labels. Quantitatively, our model achieves excellent performance with average BRISQUE and NIQE scores of 19.82 and 3.652, respectively, in all unpaired datasets. Qualitatively, enhanced images by our model exhibit significantly improved visibility in shadowed regions, natural balance of contrast and also preserve the richer fine detail without introducing noticable artifacts. This work opens new directions for unsupervised image enhancement where semantic consistency is critical.
GroundHog: Revolutionizing GLDAS Groundwater Storage Downscaling for Enhanced Recharge Estimation in Bangladesh
Mar 28, 2025Long-term groundwater level (GWL) measurement is vital for effective policymaking and recharge estimation using annual maxima and minima. However, current methods prioritize short-term predictions and lack multi-year applicability, limiting their utility. Moreover, sparse in-situ measurements lead to reliance on low-resolution satellite data like GLDAS as the ground truth for Machine Learning models, further constraining accuracy. To overcome these challenges, we first develop an ML model to mitigate data gaps, achieving $R^2$ scores of 0.855 and 0.963 for maximum and minimum GWL predictions, respectively. Subsequently, using these predictions and well observations as ground truth, we train an Upsampling Model that uses low-resolution (25 km) GLDAS data as input to produce high-resolution (2 km) GWLs, achieving an excellent $R^2$ score of 0.96. Our approach successfully upscales GLDAS data for 2003-2024, allowing high-resolution recharge estimations and revealing critical trends for proactive resource management. Our method allows upsampling of groundwater storage (GWS) from GLDAS to high-resolution GWLs for any points independently of officially curated piezometer data, making it a valuable tool for decision-making.
Ophthalmic Biomarker Detection Using Ensembled Vision Transformers -- Winning Solution to IEEE SPS VIP Cup 2023
Oct 21, 2023



This report outlines our approach in the IEEE SPS VIP Cup 2023: Ophthalmic Biomarker Detection competition. Our primary objective in this competition was to identify biomarkers from Optical Coherence Tomography (OCT) images obtained from a diverse range of patients. Using robust augmentations and 5-fold cross-validation, we trained two vision transformer-based models: MaxViT and EVA-02, and ensembled them at inference time. We find MaxViT's use of convolution layers followed by strided attention to be better suited for the detection of local features while EVA-02's use of normal attention mechanism and knowledge distillation is better for detecting global features. Ours was the best-performing solution in the competition, achieving a patient-wise F1 score of 0.814 in the first phase and 0.8527 in the second and final phase of VIP Cup 2023, scoring 3.8% higher than the next-best solution.
Image Contrast Enhancement using Fuzzy Technique with Parameter Determination using Metaheuristics
Jan 30, 2023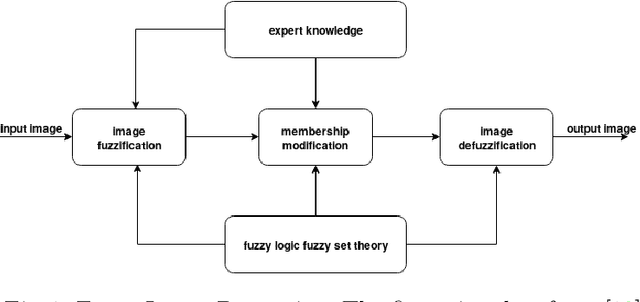

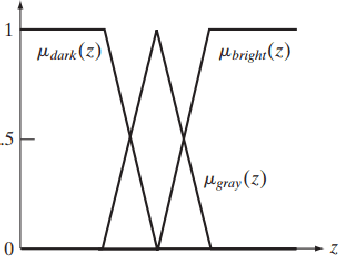
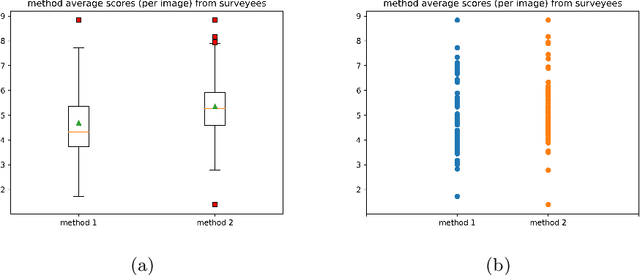
In this work, we have presented a way to increase the contrast of an image. Our target is to find a transformation that will be image specific. We have used a fuzzy system as our transformation function. To tune the system according to an image, we have used Genetic Algorithm and Hill Climbing in multiple ways to evolve the fuzzy system and conducted several experiments. Different variants of the method are tested on several images and two variants that are superior to others in terms of fitness are selected. We have also conducted a survey to assess the visual improvement of the enhancements made by the two variants. The survey indicates that one of the methods can enhance the contrast of the images visually.
RamanNet: A generalized neural network architecture for Raman Spectrum Analysis
Jan 20, 2022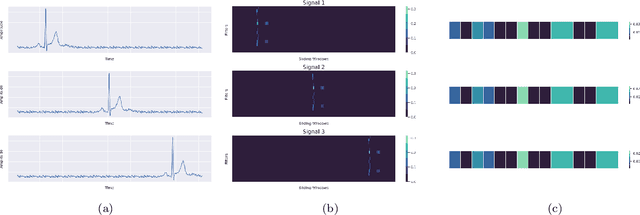
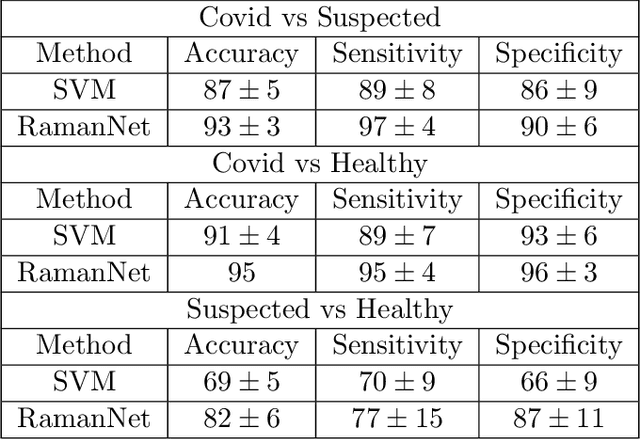
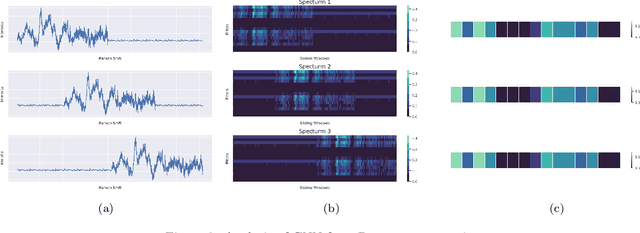

Raman spectroscopy provides a vibrational profile of the molecules and thus can be used to uniquely identify different kind of materials. This sort of fingerprinting molecules has thus led to widespread application of Raman spectrum in various fields like medical dignostics, forensics, mineralogy, bacteriology and virology etc. Despite the recent rise in Raman spectra data volume, there has not been any significant effort in developing generalized machine learning methods for Raman spectra analysis. We examine, experiment and evaluate existing methods and conjecture that neither current sequential models nor traditional machine learning models are satisfactorily sufficient to analyze Raman spectra. Both has their perks and pitfalls, therefore we attempt to mix the best of both worlds and propose a novel network architecture RamanNet. RamanNet is immune to invariance property in CNN and at the same time better than traditional machine learning models for the inclusion of sparse connectivity. Our experiments on 4 public datasets demonstrate superior performance over the much complex state-of-the-art methods and thus RamanNet has the potential to become the defacto standard in Raman spectra data analysis
Data transformation based optimized customer churn prediction model for the telecommunication industry
Jan 11, 2022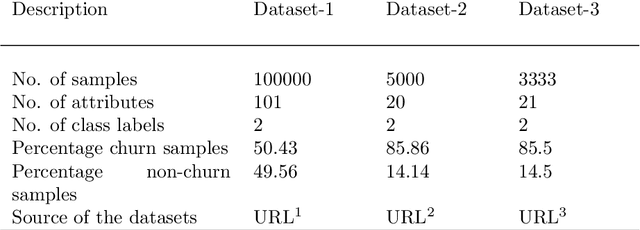
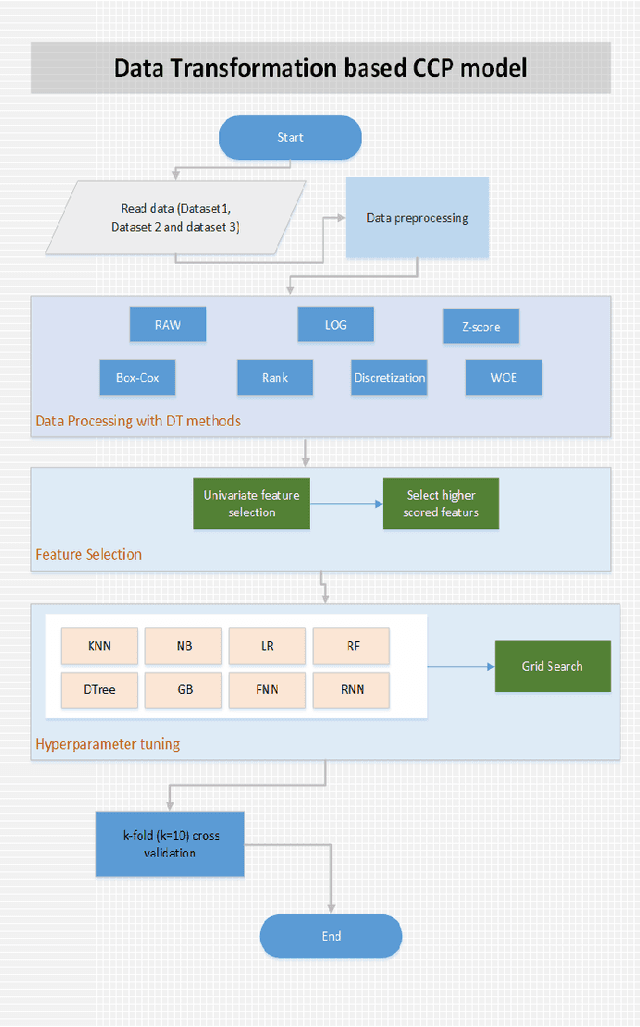
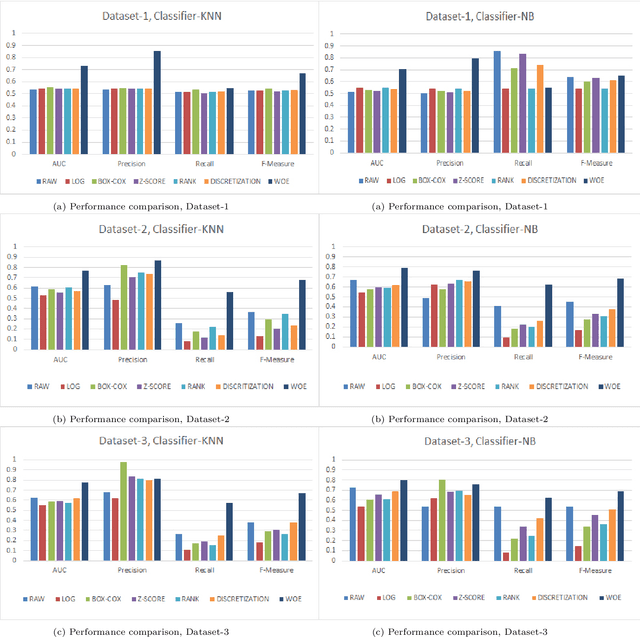
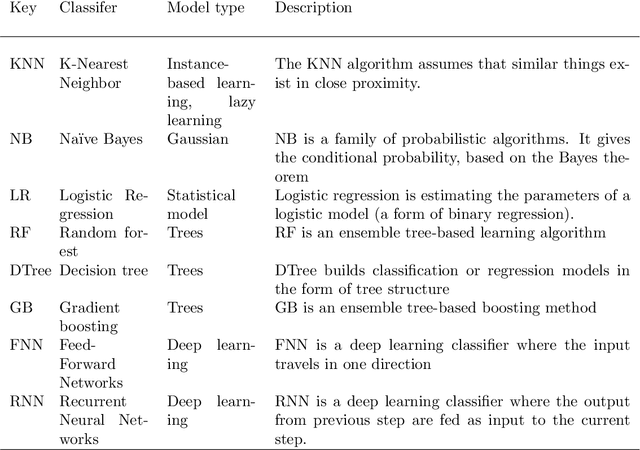
Data transformation (DT) is a process that transfers the original data into a form which supports a particular classification algorithm and helps to analyze the data for a special purpose. To improve the prediction performance we investigated various data transform methods. This study is conducted in a customer churn prediction (CCP) context in the telecommunication industry (TCI), where customer attrition is a common phenomenon. We have proposed a novel approach of combining data transformation methods with the machine learning models for the CCP problem. We conducted our experiments on publicly available TCI datasets and assessed the performance in terms of the widely used evaluation measures (e.g. AUC, precision, recall, and F-measure). In this study, we presented comprehensive comparisons to affirm the effect of the transformation methods. The comparison results and statistical test proved that most of the proposed data transformation based optimized models improve the performance of CCP significantly. Overall, an efficient and optimized CCP model for the telecommunication industry has been presented through this manuscript.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022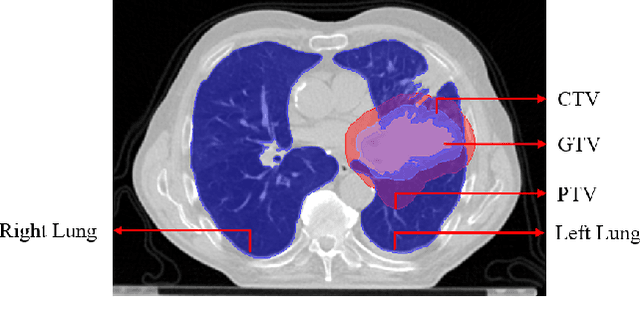
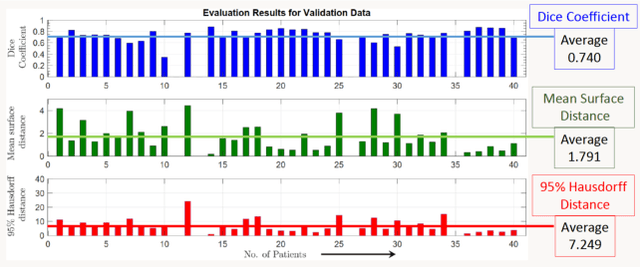
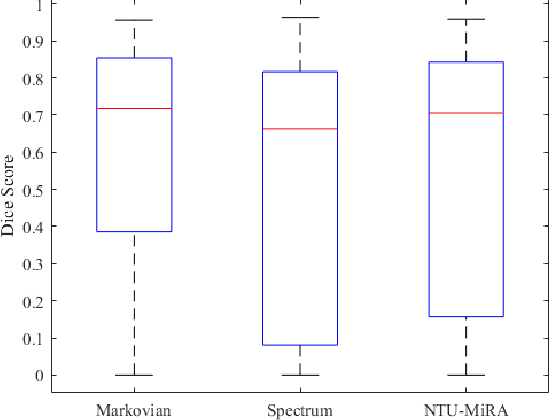
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
Segmentation of Lung Tumor from CT Images using Deep Supervision
Nov 17, 2021
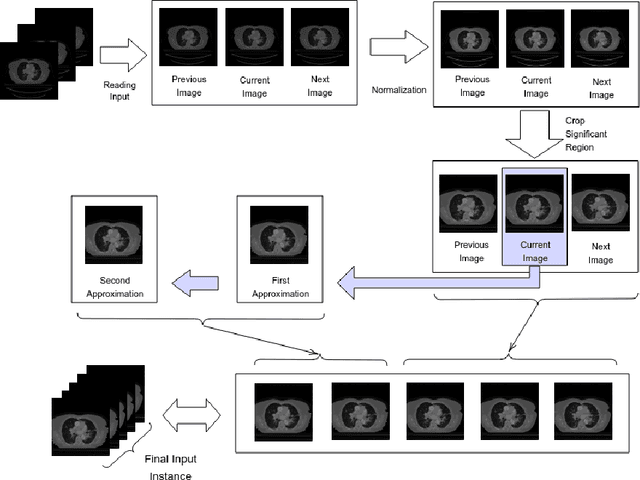

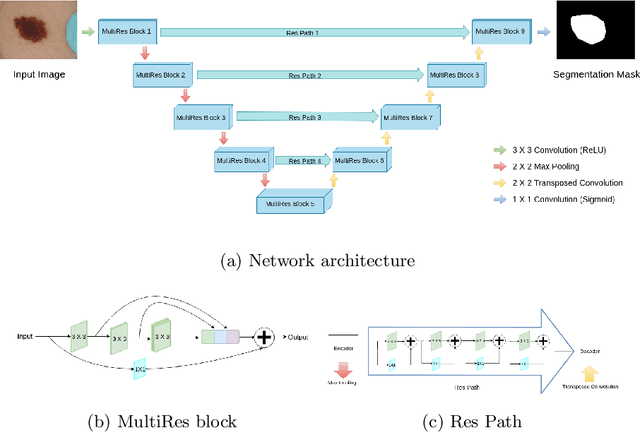
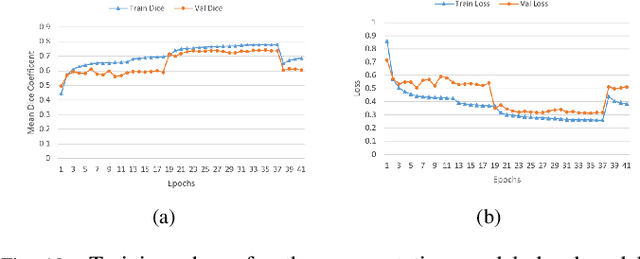
Lung cancer is a leading cause of death in most countries of the world. Since prompt diagnosis of tumors can allow oncologists to discern their nature, type and the mode of treatment, tumor detection and segmentation from CT Scan images is a crucial field of study worldwide. This paper approaches lung tumor segmentation by applying two-dimensional discrete wavelet transform (DWT) on the LOTUS dataset for more meticulous texture analysis whilst integrating information from neighboring CT slices before feeding them to a Deeply Supervised MultiResUNet model. Variations in learning rates, decay and optimization algorithms while training the network have led to different dice co-efficients, the detailed statistics of which have been included in this paper. We also discuss the challenges in this dataset and how we opted to overcome them. In essence, this study aims to maximize the success rate of predicting tumor regions from two dimensional CT Scan slices by experimenting with a number of adequate networks, resulting in a dice co-efficient of 0.8472.
A Shallow U-Net Architecture for Reliably Predicting Blood Pressure from Photoplethysmogram and Electrocardiogram Signals
Nov 12, 2021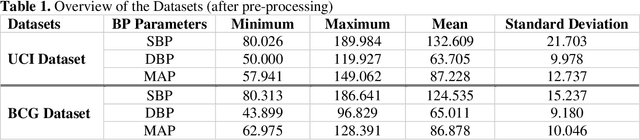
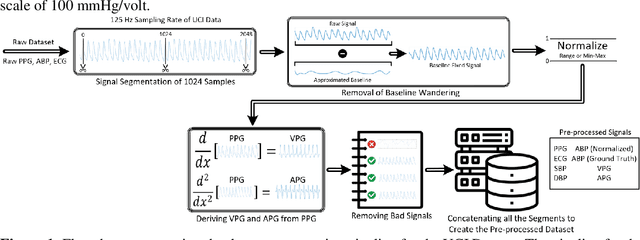
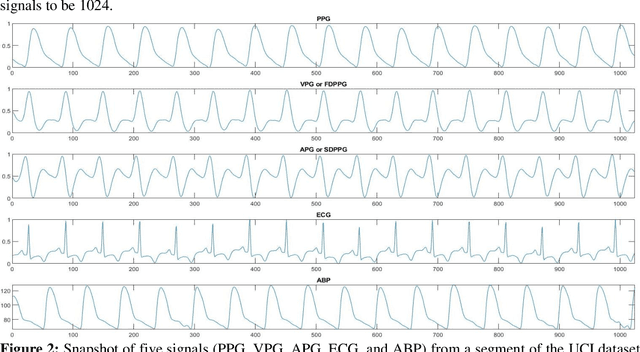
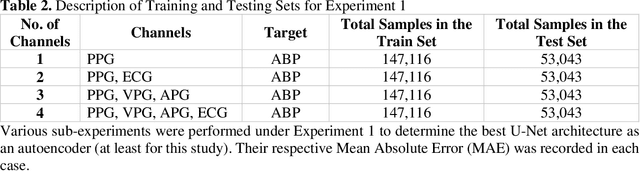
Cardiovascular diseases are the most common causes of death around the world. To detect and treat heart-related diseases, continuous Blood Pressure (BP) monitoring along with many other parameters are required. Several invasive and non-invasive methods have been developed for this purpose. Most existing methods used in the hospitals for continuous monitoring of BP are invasive. On the contrary, cuff-based BP monitoring methods, which can predict Systolic Blood Pressure (SBP) and Diastolic Blood Pressure (DBP), cannot be used for continuous monitoring. Several studies attempted to predict BP from non-invasively collectible signals such as Photoplethysmogram (PPG) and Electrocardiogram (ECG), which can be used for continuous monitoring. In this study, we explored the applicability of autoencoders in predicting BP from PPG and ECG signals. The investigation was carried out on 12,000 instances of 942 patients of the MIMIC-II dataset and it was found that a very shallow, one-dimensional autoencoder can extract the relevant features to predict the SBP and DBP with the state-of-the-art performance on a very large dataset. Independent test set from a portion of the MIMIC-II dataset provides an MAE of 2.333 and 0.713 for SBP and DBP, respectively. On an external dataset of forty subjects, the model trained on the MIMIC-II dataset, provides an MAE of 2.728 and 1.166 for SBP and DBP, respectively. For both the cases, the results met British Hypertension Society (BHS) Grade A and surpassed the studies from the current literature.