 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOphthalmic Biomarker Detection Using Ensembled Vision Transformers -- Winning Solution to IEEE SPS VIP Cup 2023
Oct 21, 2023



This report outlines our approach in the IEEE SPS VIP Cup 2023: Ophthalmic Biomarker Detection competition. Our primary objective in this competition was to identify biomarkers from Optical Coherence Tomography (OCT) images obtained from a diverse range of patients. Using robust augmentations and 5-fold cross-validation, we trained two vision transformer-based models: MaxViT and EVA-02, and ensembled them at inference time. We find MaxViT's use of convolution layers followed by strided attention to be better suited for the detection of local features while EVA-02's use of normal attention mechanism and knowledge distillation is better for detecting global features. Ours was the best-performing solution in the competition, achieving a patient-wise F1 score of 0.814 in the first phase and 0.8527 in the second and final phase of VIP Cup 2023, scoring 3.8% higher than the next-best solution.
Bangla Grammatical Error Detection Using T5 Transformer Model
Mar 19, 2023



This paper presents a method for detecting grammatical errors in Bangla using a Text-to-Text Transfer Transformer (T5) Language Model, using the small variant of BanglaT5, fine-tuned on a corpus of 9385 sentences where errors were bracketed by the dedicated demarcation symbol. The T5 model was primarily designed for translation and is not specifically designed for this task, so extensive post-processing was necessary to adapt it to the task of error detection. Our experiments show that the T5 model can achieve low Levenshtein Distance in detecting grammatical errors in Bangla, but post-processing is essential to achieve optimal performance. The final average Levenshtein Distance after post-processing the output of the fine-tuned model was 1.0394 on a test set of 5000 sentences. This paper also presents a detailed analysis of the errors detected by the model and discusses the challenges of adapting a translation model for grammar. Our approach can be extended to other languages, demonstrating the potential of T5 models for detecting grammatical errors in a wide range of languages.
Applying wav2vec2 for Speech Recognition on Bengali Common Voices Dataset
Sep 11, 2022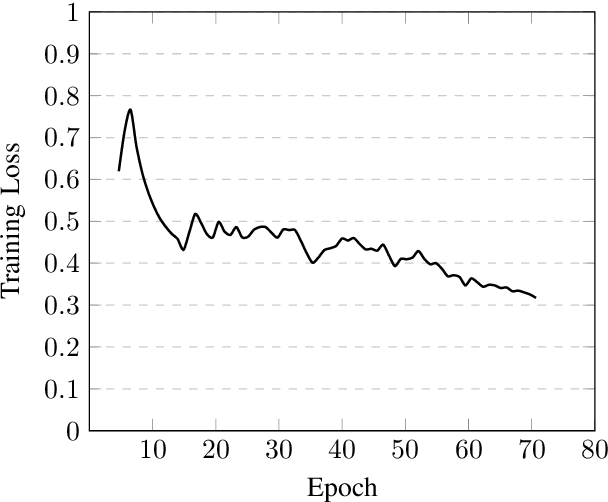
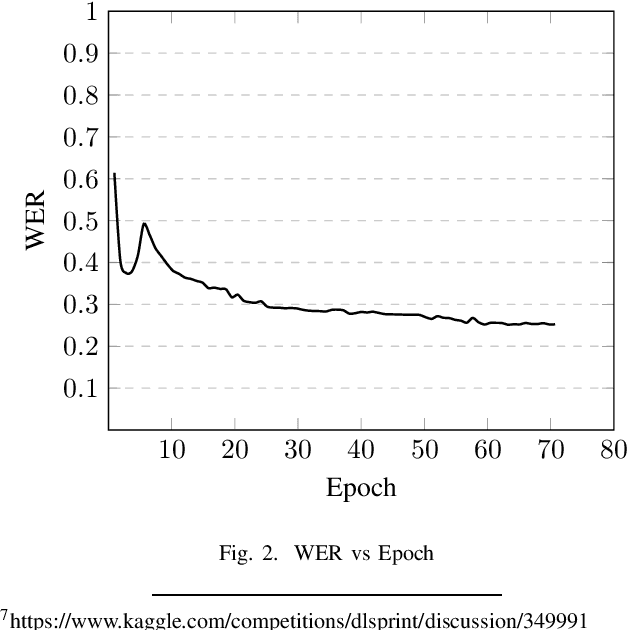

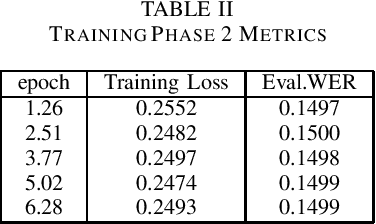
Speech is inherently continuous, where discrete words, phonemes and other units are not clearly segmented, and so speech recognition has been an active research problem for decades. In this work we have fine-tuned wav2vec 2.0 to recognize and transcribe Bengali speech -- training it on the Bengali Common Voice Speech Dataset. After training for 71 epochs, on a training set consisting of 36919 mp3 files, we achieved a training loss of 0.3172 and WER of 0.2524 on a validation set of size 7,747. Using a 5-gram language model, the Levenshtein Distance was 2.6446 on a test set of size 7,747. Then the training set and validation set were combined, shuffled and split into 85-15 ratio. Training for 7 more epochs on this combined dataset yielded an improved Levenshtein Distance of 2.60753 on the test set. Our model was the best performing one, achieving a Levenshtein Distance of 6.234 on a hidden dataset, which was 1.1049 units lower than other competing submissions.