 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Late to Train, Too Early To Use? A Study on Necessity and Viability of Low-Resource Bengali LLMs
Jun 29, 2024



Each new generation of English-oriented Large Language Models (LLMs) exhibits enhanced cross-lingual transfer capabilities and significantly outperforms older LLMs on low-resource languages. This prompts the question: Is there a need for LLMs dedicated to a particular low-resource language? We aim to explore this question for Bengali, a low-to-moderate resource Indo-Aryan language native to the Bengal region of South Asia. We compare the performance of open-weight and closed-source LLMs such as LLaMA-3 and GPT-4 against fine-tuned encoder-decoder models across a diverse set of Bengali downstream tasks, including translation, summarization, paraphrasing, question-answering, and natural language inference. Our findings reveal that while LLMs generally excel in reasoning tasks, their performance in tasks requiring Bengali script generation is inconsistent. Key challenges include inefficient tokenization of Bengali script by existing LLMs, leading to increased computational costs and potential performance degradation. Additionally, we highlight biases in machine-translated datasets commonly used for Bengali NLP tasks. We conclude that there is a significant need for a Bengali-oriented LLM, but the field currently lacks the high-quality pretraining and instruction-tuning datasets necessary to develop a highly effective model.
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Mar 30, 2024The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
Connecting the Dots: Leveraging Spatio-Temporal Graph Neural Networks for Accurate Bangla Sign Language Recognition
Jan 22, 2024Recent advances in Deep Learning and Computer Vision have been successfully leveraged to serve marginalized communities in various contexts. One such area is Sign Language - a primary means of communication for the deaf community. However, so far, the bulk of research efforts and investments have gone into American Sign Language, and research activity into low-resource sign languages - especially Bangla Sign Language - has lagged significantly. In this research paper, we present a new word-level Bangla Sign Language dataset - BdSL40 - consisting of 611 videos over 40 words, along with two different approaches: one with a 3D Convolutional Neural Network model and another with a novel Graph Neural Network approach for the classification of BdSL40 dataset. This is the first study on word-level BdSL recognition, and the dataset was transcribed from Indian Sign Language (ISL) using the Bangla Sign Language Dictionary (1997). The proposed GNN model achieved an F1 score of 89%. The study highlights the significant lexical and semantic similarity between BdSL, West Bengal Sign Language, and ISL, and the lack of word-level datasets for BdSL in the literature. We release the dataset and source code to stimulate further research.
Ophthalmic Biomarker Detection Using Ensembled Vision Transformers -- Winning Solution to IEEE SPS VIP Cup 2023
Oct 21, 2023



This report outlines our approach in the IEEE SPS VIP Cup 2023: Ophthalmic Biomarker Detection competition. Our primary objective in this competition was to identify biomarkers from Optical Coherence Tomography (OCT) images obtained from a diverse range of patients. Using robust augmentations and 5-fold cross-validation, we trained two vision transformer-based models: MaxViT and EVA-02, and ensembled them at inference time. We find MaxViT's use of convolution layers followed by strided attention to be better suited for the detection of local features while EVA-02's use of normal attention mechanism and knowledge distillation is better for detecting global features. Ours was the best-performing solution in the competition, achieving a patient-wise F1 score of 0.814 in the first phase and 0.8527 in the second and final phase of VIP Cup 2023, scoring 3.8% higher than the next-best solution.
Bangla Grammatical Error Detection Using T5 Transformer Model
Mar 19, 2023



This paper presents a method for detecting grammatical errors in Bangla using a Text-to-Text Transfer Transformer (T5) Language Model, using the small variant of BanglaT5, fine-tuned on a corpus of 9385 sentences where errors were bracketed by the dedicated demarcation symbol. The T5 model was primarily designed for translation and is not specifically designed for this task, so extensive post-processing was necessary to adapt it to the task of error detection. Our experiments show that the T5 model can achieve low Levenshtein Distance in detecting grammatical errors in Bangla, but post-processing is essential to achieve optimal performance. The final average Levenshtein Distance after post-processing the output of the fine-tuned model was 1.0394 on a test set of 5000 sentences. This paper also presents a detailed analysis of the errors detected by the model and discusses the challenges of adapting a translation model for grammar. Our approach can be extended to other languages, demonstrating the potential of T5 models for detecting grammatical errors in a wide range of languages.
Applying wav2vec2 for Speech Recognition on Bengali Common Voices Dataset
Sep 11, 2022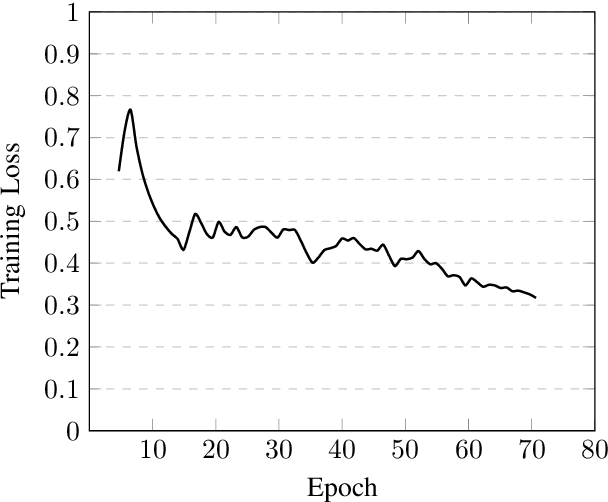
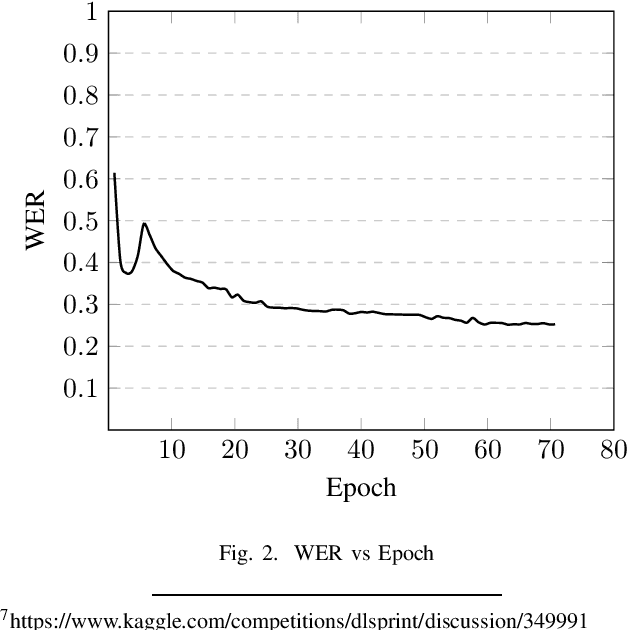

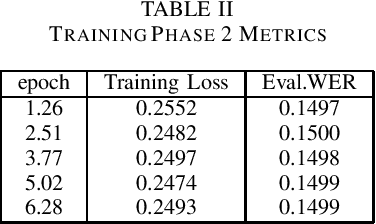
Speech is inherently continuous, where discrete words, phonemes and other units are not clearly segmented, and so speech recognition has been an active research problem for decades. In this work we have fine-tuned wav2vec 2.0 to recognize and transcribe Bengali speech -- training it on the Bengali Common Voice Speech Dataset. After training for 71 epochs, on a training set consisting of 36919 mp3 files, we achieved a training loss of 0.3172 and WER of 0.2524 on a validation set of size 7,747. Using a 5-gram language model, the Levenshtein Distance was 2.6446 on a test set of size 7,747. Then the training set and validation set were combined, shuffled and split into 85-15 ratio. Training for 7 more epochs on this combined dataset yielded an improved Levenshtein Distance of 2.60753 on the test set. Our model was the best performing one, achieving a Levenshtein Distance of 6.234 on a hidden dataset, which was 1.1049 units lower than other competing submissions.