 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnecting the Dots: Leveraging Spatio-Temporal Graph Neural Networks for Accurate Bangla Sign Language Recognition
Jan 22, 2024Recent advances in Deep Learning and Computer Vision have been successfully leveraged to serve marginalized communities in various contexts. One such area is Sign Language - a primary means of communication for the deaf community. However, so far, the bulk of research efforts and investments have gone into American Sign Language, and research activity into low-resource sign languages - especially Bangla Sign Language - has lagged significantly. In this research paper, we present a new word-level Bangla Sign Language dataset - BdSL40 - consisting of 611 videos over 40 words, along with two different approaches: one with a 3D Convolutional Neural Network model and another with a novel Graph Neural Network approach for the classification of BdSL40 dataset. This is the first study on word-level BdSL recognition, and the dataset was transcribed from Indian Sign Language (ISL) using the Bangla Sign Language Dictionary (1997). The proposed GNN model achieved an F1 score of 89%. The study highlights the significant lexical and semantic similarity between BdSL, West Bengal Sign Language, and ISL, and the lack of word-level datasets for BdSL in the literature. We release the dataset and source code to stimulate further research.
PULSAR: Graph based Positive Unlabeled Learning with Multi Stream Adaptive Convolutions for Parkinson's Disease Recognition
Dec 10, 2023



Parkinson's disease (PD) is a neuro-degenerative disorder that affects movement, speech, and coordination. Timely diagnosis and treatment can improve the quality of life for PD patients. However, access to clinical diagnosis is limited in low and middle income countries (LMICs). Therefore, development of automated screening tools for PD can have a huge social impact, particularly in the public health sector. In this paper, we present PULSAR, a novel method to screen for PD from webcam-recorded videos of the finger-tapping task from the Movement Disorder Society - Unified Parkinson's Disease Rating Scale (MDS-UPDRS). PULSAR is trained and evaluated on data collected from 382 participants (183 self-reported as PD patients). We used an adaptive graph convolutional neural network to dynamically learn the spatio temporal graph edges specific to the finger-tapping task. We enhanced this idea with a multi stream adaptive convolution model to learn features from different modalities of data critical to detect PD, such as relative location of the finger joints, velocity and acceleration of tapping. As the labels of the videos are self-reported, there could be cases of undiagnosed PD in the non-PD labeled samples. We leveraged the idea of Positive Unlabeled (PU) Learning that does not need labeled negative data. Our experiments show clear benefit of modeling the problem in this way. PULSAR achieved 80.95% accuracy in validation set and a mean accuracy of 71.29% (2.49% standard deviation) in independent test, despite being trained with limited amount of data. This is specially promising as labeled data is scarce in health care sector. We hope PULSAR will make PD screening more accessible to everyone. The proposed techniques could be extended for assessment of other movement disorders, such as ataxia, and Huntington's disease.
BanglaCoNER: Towards Robust Bangla Complex Named Entity Recognition
Mar 17, 2023
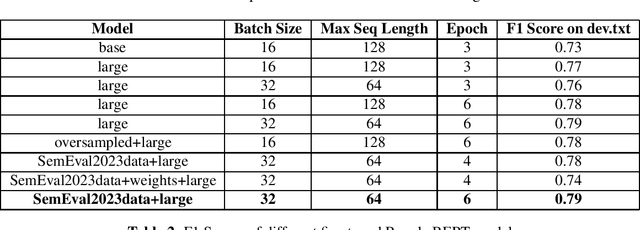
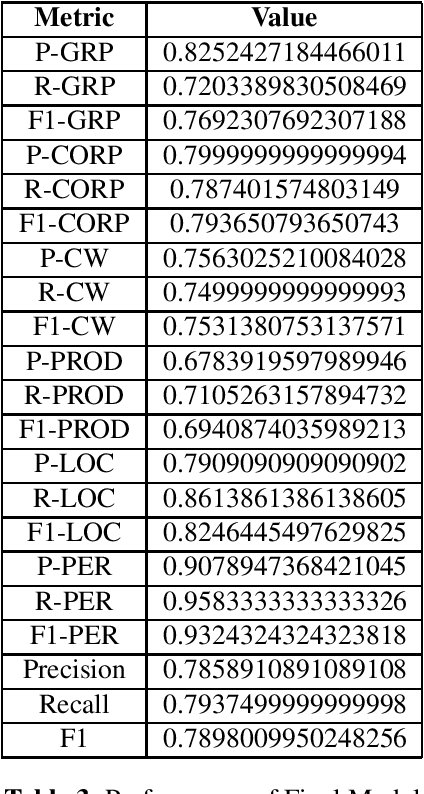
Named Entity Recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying named entities in text. But much work hasn't been done for complex named entity recognition in Bangla, despite being the seventh most spoken language globally. CNER is a more challenging task than traditional NER as it involves identifying and classifying complex and compound entities, which are not common in Bangla language. In this paper, we present the winning solution of Bangla Complex Named Entity Recognition Challenge - addressing the CNER task on BanglaCoNER dataset using two different approaches, namely Conditional Random Fields (CRF) and finetuning transformer based Deep Learning models such as BanglaBERT. The dataset consisted of 15300 sentences for training and 800 sentences for validation, in the .conll format. Exploratory Data Analysis (EDA) on the dataset revealed that the dataset had 7 different NER tags, with notable presence of English words, suggesting that the dataset is synthetic and likely a product of translation. We experimented with a variety of feature combinations including Part of Speech (POS) tags, word suffixes, Gazetteers, and cluster information from embeddings, while also finetuning the BanglaBERT (large) model for NER. We found that not all linguistic patterns are immediately apparent or even intuitive to humans, which is why Deep Learning based models has proved to be the more effective model in NLP, including CNER task. Our fine tuned BanglaBERT (large) model achieves an F1 Score of 0.79 on the validation set. Overall, our study highlights the importance of Bangla Complex Named Entity Recognition, particularly in the context of synthetic datasets. Our findings also demonstrate the efficacy of Deep Learning models such as BanglaBERT for NER in Bangla language.