 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaCoNER: Towards Robust Bangla Complex Named Entity Recognition
Mar 17, 2023
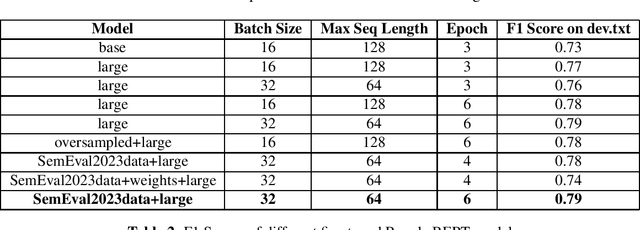
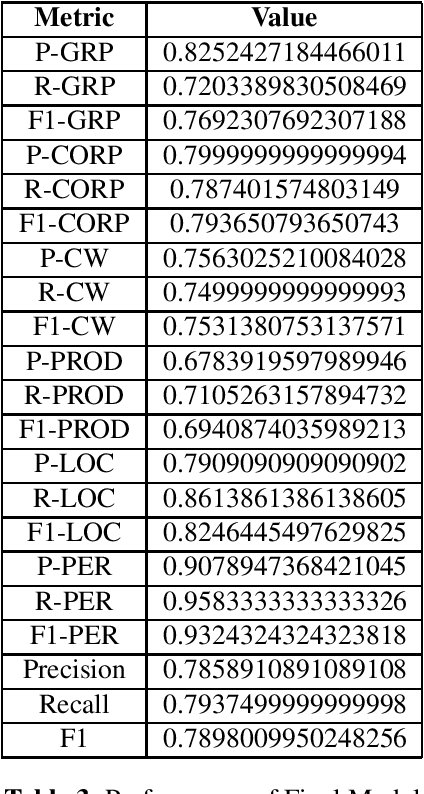
Named Entity Recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying named entities in text. But much work hasn't been done for complex named entity recognition in Bangla, despite being the seventh most spoken language globally. CNER is a more challenging task than traditional NER as it involves identifying and classifying complex and compound entities, which are not common in Bangla language. In this paper, we present the winning solution of Bangla Complex Named Entity Recognition Challenge - addressing the CNER task on BanglaCoNER dataset using two different approaches, namely Conditional Random Fields (CRF) and finetuning transformer based Deep Learning models such as BanglaBERT. The dataset consisted of 15300 sentences for training and 800 sentences for validation, in the .conll format. Exploratory Data Analysis (EDA) on the dataset revealed that the dataset had 7 different NER tags, with notable presence of English words, suggesting that the dataset is synthetic and likely a product of translation. We experimented with a variety of feature combinations including Part of Speech (POS) tags, word suffixes, Gazetteers, and cluster information from embeddings, while also finetuning the BanglaBERT (large) model for NER. We found that not all linguistic patterns are immediately apparent or even intuitive to humans, which is why Deep Learning based models has proved to be the more effective model in NLP, including CNER task. Our fine tuned BanglaBERT (large) model achieves an F1 Score of 0.79 on the validation set. Overall, our study highlights the importance of Bangla Complex Named Entity Recognition, particularly in the context of synthetic datasets. Our findings also demonstrate the efficacy of Deep Learning models such as BanglaBERT for NER in Bangla language.