 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxiomatizing Neural Networks via Pursuit of Subspaces
May 19, 2026While deep neural networks have achieved remarkable success across a wide range of domains, their underlying mechanisms remain poorly understood, and they are often regarded as black boxes. This gap between empirical performance and theoretical understanding poses a challenge analogous to the pre-axiomatic stage of classical geometry. In this work, we introduce the Pursuit of Subspaces (PoS) hypothesis, an axiomatic framework that formulates neural network behavior through a set of geometric postulates. These axioms, together with their derived consequences, provide a unified perspective on representation, computation, and generalization in both shallow and deep architectures. We show that this framework yields geometric explanations for fundamental questions in deep learning, including representation structure, architectural mechanisms, and generalization behavior, offering a principled step toward a coherent theoretical foundation.
MTS-CSNet: Multiscale Tensor Factorization for Deep Compressive Sensing on RGB Images
Feb 04, 2026Deep learning based compressive sensing (CS) methods typically learn sampling operators using convolutional or block wise fully connected layers, which limit receptive fields and scale poorly for high dimensional data. We propose MTSCSNet, a CS framework based on Multiscale Tensor Summation (MTS) factorization, a structured operator for efficient multidimensional signal processing. MTS performs mode-wise linear transformations with multiscale summation, enabling large receptive fields and effective modeling of cross-dimensional correlations. In MTSCSNet, MTS is first used as a learnable CS operator that performs linear dimensionality reduction in tensor space, with its adjoint defining the initial back-projection, and is then applied in the reconstruction stage to directly refine this estimate. This results in a simple feed-forward architecture without iterative or proximal optimization, while remaining parameter and computation efficient. Experiments on standard CS benchmarks show that MTSCSNet achieves state-of-the-art reconstruction performance on RGB images, with notable PSNR gains and faster inference, even compared to recent diffusion-based CS methods, while using a significantly more compact feed-forward architecture.
Multiscale Tensor Summation Factorization as a New Neural Network Layer (MTS Layer) for Multidimensional Data Processing
Apr 17, 2025Multilayer perceptrons (MLP), or fully connected artificial neural networks, are known for performing vector-matrix multiplications using learnable weight matrices; however, their practical application in many machine learning tasks, especially in computer vision, can be limited due to the high dimensionality of input-output pairs at each layer. To improve efficiency, convolutional operators have been utilized to facilitate weight sharing and local connections, yet they are constrained by limited receptive fields. In this paper, we introduce Multiscale Tensor Summation (MTS) Factorization, a novel neural network operator that implements tensor summation at multiple scales, where each tensor to be summed is obtained through Tucker-decomposition-like mode products. Unlike other tensor decomposition methods in the literature, MTS is not introduced as a network compression tool; instead, as a new backbone neural layer. MTS not only reduces the number of parameters required while enhancing the efficiency of weight optimization compared to traditional dense layers (i.e., unfactorized weight matrices in MLP layers), but it also demonstrates clear advantages over convolutional layers. The proof-of-concept experimental comparison of the proposed MTS networks with MLPs and Convolutional Neural Networks (CNNs) demonstrates their effectiveness across various tasks, such as classification, compression, and signal restoration. Additionally, when integrated with modern non-linear units such as the multi-head gate (MHG), also introduced in this study, the corresponding neural network, MTSNet, demonstrates a more favorable complexity-performance tradeoff compared to state-of-the-art transformers in various computer vision applications. The software implementation of the MTS layer and the corresponding MTS-based networks, MTSNets, is shared at https://github.com/mehmetyamac/MTSNet.
Progressive Transfer Learning for Multi-Pass Fundus Image Restoration
Apr 14, 2025


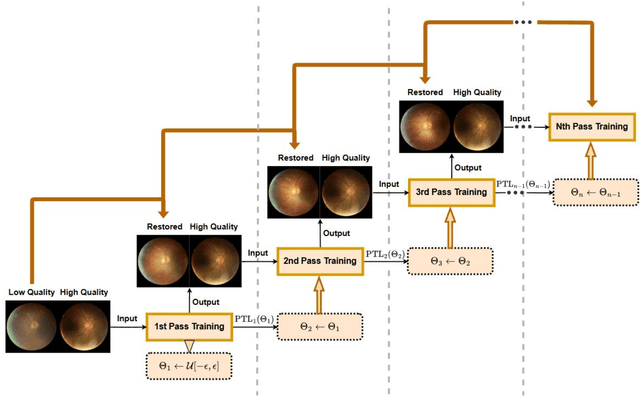
Diabetic retinopathy is a leading cause of vision impairment, making its early diagnosis through fundus imaging critical for effective treatment planning. However, the presence of poor quality fundus images caused by factors such as inadequate illumination, noise, blurring and other motion artifacts yields a significant challenge for accurate DR screening. In this study, we propose progressive transfer learning for multi pass restoration to iteratively enhance the quality of degraded fundus images, ensuring more reliable DR screening. Unlike previous methods that often focus on a single pass restoration, multi pass restoration via PTL can achieve a superior blind restoration performance that can even improve most of the good quality fundus images in the dataset. Initially, a Cycle GAN model is trained to restore low quality images, followed by PTL induced restoration passes over the latest restored outputs to improve overall quality in each pass. The proposed method can learn blind restoration without requiring any paired data while surpassing its limitations by leveraging progressive learning and fine tuning strategies to minimize distortions and preserve critical retinal features. To evaluate PTL's effectiveness on multi pass restoration, we conducted experiments on DeepDRiD, a large scale fundus imaging dataset specifically curated for diabetic retinopathy detection. Our result demonstrates state of the art performance, showcasing PTL's potential as a superior approach to iterative image quality restoration.
Semi-Supervised Co-Training of Time and Time-Frequency Models: Application to Bearing Fault Diagnosis
Mar 14, 2025



Neural networks require massive amounts of annotated data to train intelligent solutions. Acquiring many labeled data in industrial applications is often difficult; therefore, semi-supervised approaches are preferred. We propose a new semi-supervised co-training method, which combines time and time-frequency (TF) machine learning models to improve performance and reliability. The developed framework collaboratively co-trains fast time-domain models by utilizing high-performing TF techniques without increasing the inference complexity. Besides, it operates in cloud-edge networks and offers holistic support for many applications covering edge-real-time monitoring and cloud-based updates and corrections. Experimental results on bearing fault diagnosis verify the superiority of our technique compared to a competing self-training method. The results from two case studies show that our method outperforms self-training for different noise levels and amounts of available data with accuracy gains reaching from 10.6% to 33.9%. They demonstrate that fusing time-domain and TF-based models offers opportunities for developing high-performance industrial solutions.
Deep Learning in Automated Power Line Inspection: A Review
Feb 10, 2025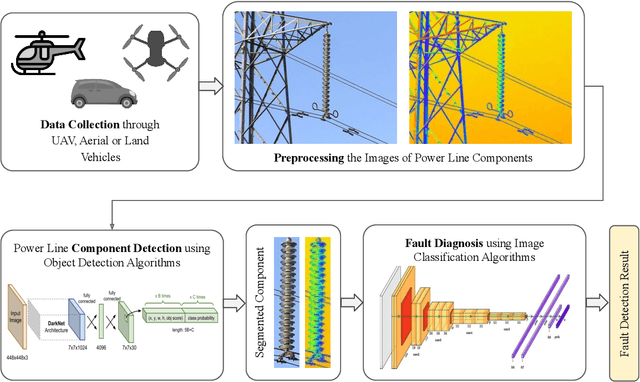



In recent years, power line maintenance has seen a paradigm shift by moving towards computer vision-powered automated inspection. The utilization of an extensive collection of videos and images has become essential for maintaining the reliability, safety, and sustainability of electricity transmission. A significant focus on applying deep learning techniques for enhancing power line inspection processes has been observed in recent research. A comprehensive review of existing studies has been conducted in this paper, to aid researchers and industries in developing improved deep learning-based systems for analyzing power line data. The conventional steps of data analysis in power line inspections have been examined, and the body of current research has been systematically categorized into two main areas: the detection of components and the diagnosis of faults. A detailed summary of the diverse methods and techniques employed in these areas has been encapsulated, providing insights into their functionality and use cases. Special attention has been given to the exploration of deep learning-based methodologies for the analysis of power line inspection data, with an exposition of their fundamental principles and practical applications. Moreover, a vision for future research directions has been outlined, highlighting the need for advancements such as edge-cloud collaboration, and multi-modal analysis among others. Thus, this paper serves as a comprehensive resource for researchers delving into deep learning for power line analysis, illuminating the extent of current knowledge and the potential areas for future investigation.
CoRe-Net: Co-Operational Regressor Network with Progressive Transfer Learning for Blind Radar Signal Restoration
Jan 28, 2025



Real-world radar signals are frequently corrupted by various artifacts, including sensor noise, echoes, interference, and intentional jamming, differing in type, severity, and duration. This pilot study introduces a novel model, called Co-Operational Regressor Network (CoRe-Net) for blind radar signal restoration, designed to address such limitations and drawbacks. CoRe-Net replaces adversarial training with a novel cooperative learning strategy, leveraging the complementary roles of its Apprentice Regressor (AR) and Master Regressor (MR). The AR restores radar signals corrupted by various artifacts, while the MR evaluates the quality of the restoration and provides immediate and task-specific feedback, ensuring stable and efficient learning. The AR, therefore, has the advantage of both self-learning and assistive learning by the MR. The proposed model has been extensively evaluated over the benchmark Blind Radar Signal Restoration (BRSR) dataset, which simulates diverse real-world artifact scenarios. Under the fair experimental setup, this study shows that the CoRe-Net surpasses the Op-GANs over a 1 dB mean SNR improvement. To further boost the performance gain, this study proposes multi-pass restoration by cascaded CoRe-Nets trained with a novel paradigm called Progressive Transfer Learning (PTL), which enables iterative refinement, thus achieving an additional 2 dB mean SNR enhancement. Multi-pass CoRe-Net training by PTL consistently yields incremental performance improvements through successive restoration passes whilst highlighting CoRe-Net ability to handle such a complex and varying blend of artifacts.
Echocardiography to Cardiac MRI View Transformation for Real-Time Blind Restoration
Dec 09, 2024



Echocardiography is the most widely used imaging to monitor cardiac functions, serving as the first line in early detection of myocardial ischemia and infarction. However, echocardiography often suffers from several artifacts including sensor noise, lack of contrast, severe saturation, and missing myocardial segments which severely limit its usage in clinical diagnosis. In recent years, several machine learning methods have been proposed to improve echocardiography views. Yet, these methods usually address only a specific problem (e.g. denoising) and thus cannot provide a robust and reliable restoration in general. On the other hand, cardiac MRI provides a clean view of the heart without suffering such severe issues. However, due to its significantly higher cost, it is often only afforded by a few major hospitals, hence hindering its use and accessibility. In this pilot study, we propose a novel approach to transform echocardiography into the cardiac MRI view. For this purpose, Echo2MRI dataset, consisting of echocardiography and real cardiac MRI image pairs, is composed and will be shared publicly. A dedicated Cycle-consistent Generative Adversarial Network (Cycle-GAN) is trained to learn the transformation from echocardiography frames to cardiac MRI views. An extensive set of qualitative evaluations shows that the proposed transformer can synthesize high-quality artifact-free synthetic cardiac MRI views from a given sequence of echocardiography frames. Medical evaluations performed by a group of cardiologists further demonstrate that synthetic MRI views are indistinguishable from their original counterparts and are preferred over their initial sequence of echocardiography frames for diagnosis in 78.9% of the cases.
Blind Underwater Image Restoration using Co-Operational Regressor Networks
Dec 05, 2024
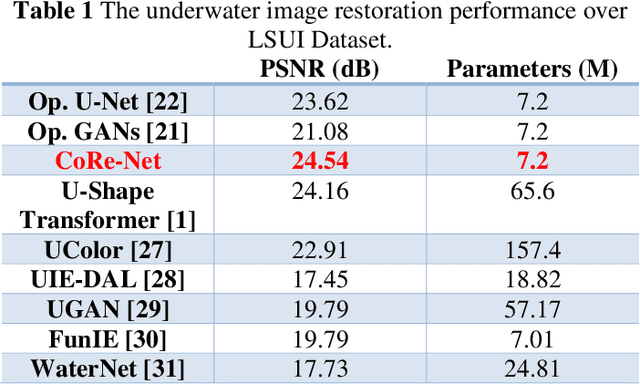
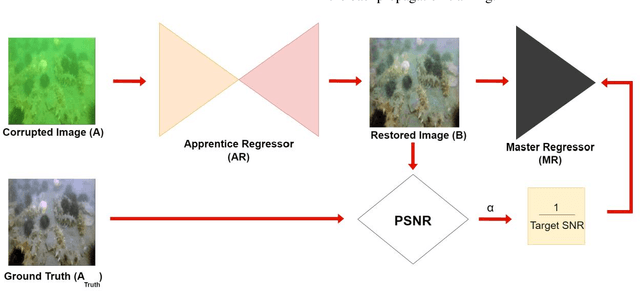
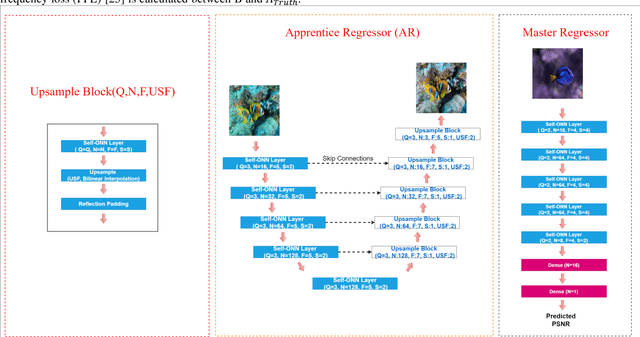
The exploration of underwater environments is essential for applications such as biological research, archaeology, and infrastructure maintenanceHowever, underwater imaging is challenging due to the waters unique properties, including scattering, absorption, color distortion, and reduced visibility. To address such visual degradations, a variety of approaches have been proposed covering from basic signal processing methods to deep learning models; however, none of them has proven to be consistently successful. In this paper, we propose a novel machine learning model, Co-Operational Regressor Networks (CoRe-Nets), designed to achieve the best possible underwater image restoration. A CoRe-Net consists of two co-operating networks: the Apprentice Regressor (AR), responsible for image transformation, and the Master Regressor (MR), which evaluates the Peak Signal-to-Noise Ratio (PSNR) of the images generated by the AR and feeds it back to AR. CoRe-Nets are built on Self-Organized Operational Neural Networks (Self-ONNs), which offer a superior learning capability by modulating nonlinearity in kernel transformations. The effectiveness of the proposed model is demonstrated on the benchmark Large Scale Underwater Image (LSUI) dataset. Leveraging the joint learning capabilities of the two cooperating networks, the proposed model achieves the state-of-art restoration performance with significantly reduced computational complexity and often presents such results that can even surpass the visual quality of the ground truth with a 2-pass application. Our results and the optimized PyTorch implementation of the proposed approach are now publicly shared on GitHub.
BRSR-OpGAN: Blind Radar Signal Restoration using Operational Generative Adversarial Network
Jul 18, 2024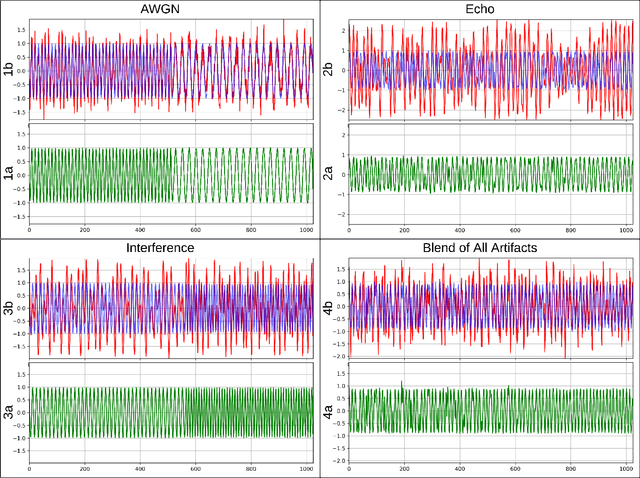
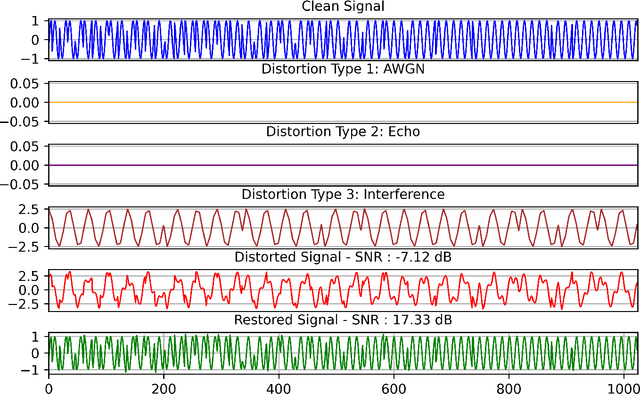
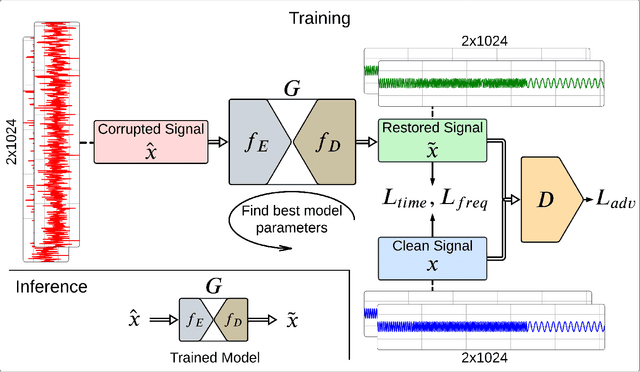
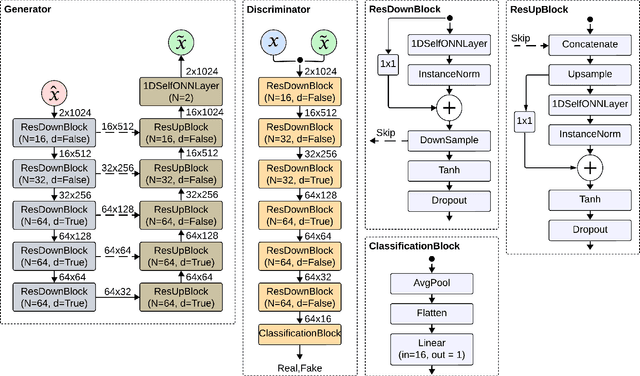
Objective: Many studies on radar signal restoration in the literature focus on isolated restoration problems, such as denoising over a certain type of noise, while ignoring other types of artifacts. Additionally, these approaches usually assume a noisy environment with a limited set of fixed signal-to-noise ratio (SNR) levels. However, real-world radar signals are often corrupted by a blend of artifacts, including but not limited to unwanted echo, sensor noise, intentional jamming, and interference, each of which can vary in type, severity, and duration. This study introduces Blind Radar Signal Restoration using an Operational Generative Adversarial Network (BRSR-OpGAN), which uses a dual domain loss in the temporal and spectral domains. This approach is designed to improve the quality of radar signals, regardless of the diversity and intensity of the corruption. Methods: The BRSR-OpGAN utilizes 1D Operational GANs, which use a generative neuron model specifically optimized for blind restoration of corrupted radar signals. This approach leverages GANs' flexibility to adapt dynamically to a wide range of artifact characteristics. Results: The proposed approach has been extensively evaluated using a well-established baseline and a newly curated extended dataset called the Blind Radar Signal Restoration (BRSR) dataset. This dataset was designed to simulate real-world conditions and includes a variety of artifacts, each varying in severity. The evaluation shows an average SNR improvement over 15.1 dB and 14.3 dB for the baseline and BRSR datasets, respectively. Finally, even on resource-constrained platforms, the proposed approach can be applied in real-time.