 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchocardiography to Cardiac MRI View Transformation for Real-Time Blind Restoration
Dec 09, 2024



Echocardiography is the most widely used imaging to monitor cardiac functions, serving as the first line in early detection of myocardial ischemia and infarction. However, echocardiography often suffers from several artifacts including sensor noise, lack of contrast, severe saturation, and missing myocardial segments which severely limit its usage in clinical diagnosis. In recent years, several machine learning methods have been proposed to improve echocardiography views. Yet, these methods usually address only a specific problem (e.g. denoising) and thus cannot provide a robust and reliable restoration in general. On the other hand, cardiac MRI provides a clean view of the heart without suffering such severe issues. However, due to its significantly higher cost, it is often only afforded by a few major hospitals, hence hindering its use and accessibility. In this pilot study, we propose a novel approach to transform echocardiography into the cardiac MRI view. For this purpose, Echo2MRI dataset, consisting of echocardiography and real cardiac MRI image pairs, is composed and will be shared publicly. A dedicated Cycle-consistent Generative Adversarial Network (Cycle-GAN) is trained to learn the transformation from echocardiography frames to cardiac MRI views. An extensive set of qualitative evaluations shows that the proposed transformer can synthesize high-quality artifact-free synthetic cardiac MRI views from a given sequence of echocardiography frames. Medical evaluations performed by a group of cardiologists further demonstrate that synthetic MRI views are indistinguishable from their original counterparts and are preferred over their initial sequence of echocardiography frames for diagnosis in 78.9% of the cases.
Refining Myocardial Infarction Detection: A Novel Multi-Modal Composite Kernel Strategy in One-Class Classification
Feb 09, 2024


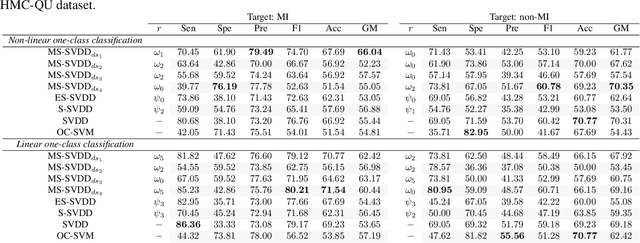
Early detection of myocardial infarction (MI), a critical condition arising from coronary artery disease (CAD), is vital to prevent further myocardial damage. This study introduces a novel method for early MI detection using a one-class classification (OCC) algorithm in echocardiography. Our study overcomes the challenge of limited echocardiography data availability by adopting a novel approach based on Multi-modal Subspace Support Vector Data Description. The proposed technique involves a specialized MI detection framework employing multi-view echocardiography incorporating a composite kernel in the non-linear projection trick, fusing Gaussian and Laplacian sigmoid functions. Additionally, we enhance the update strategy of the projection matrices by adapting maximization for both or one of the modalities in the optimization process. Our method boosts MI detection capability by efficiently transforming features extracted from echocardiography data into an optimized lower-dimensional subspace. The OCC model trained specifically on target class instances from the comprehensive HMC-QU dataset that includes multiple echocardiography views indicates a marked improvement in MI detection accuracy. Our findings reveal that our proposed multi-view approach achieves a geometric mean of 71.24\%, signifying a substantial advancement in echocardiography-based MI diagnosis and offering more precise and efficient diagnostic tools.
SAF-Net: Self-Attention Fusion Network for Myocardial Infarction Detection using Multi-View Echocardiography
Sep 27, 2023


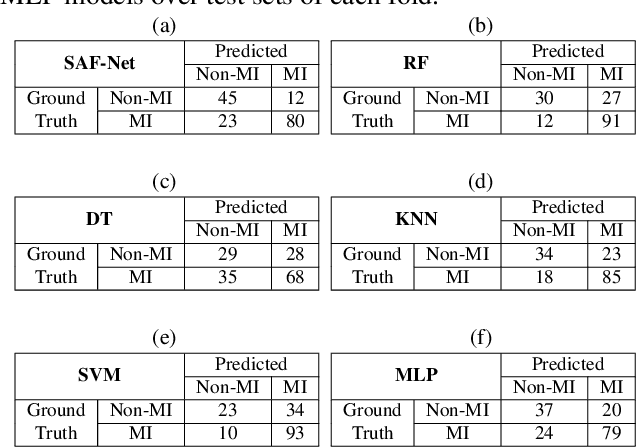
Myocardial infarction (MI) is a severe case of coronary artery disease (CAD) and ultimately, its detection is substantial to prevent progressive damage to the myocardium. In this study, we propose a novel view-fusion model named self-attention fusion network (SAF-Net) to detect MI from multi-view echocardiography recordings. The proposed framework utilizes apical 2-chamber (A2C) and apical 4-chamber (A4C) view echocardiography recordings for classification. Three reference frames are extracted from each recording of both views and deployed pre-trained deep networks to extract highly representative features. The SAF-Net model utilizes a self-attention mechanism to learn dependencies in extracted feature vectors. The proposed model is computationally efficient thanks to its compact architecture having three main parts: a feature embedding to reduce dimensionality, self-attention for view-pooling, and dense layers for the classification. Experimental evaluation is performed using the HMC-QU-TAU dataset which consists of 160 patients with A2C and A4C view echocardiography recordings. The proposed SAF-Net model achieves a high-performance level with 88.26% precision, 77.64% sensitivity, and 78.13% accuracy. The results demonstrate that the SAF-Net model achieves the most accurate MI detection over multi-view echocardiography recordings.
MAMAF-Net: Motion-Aware and Multi-Attention Fusion Network for Stroke Diagnosis
Apr 19, 2023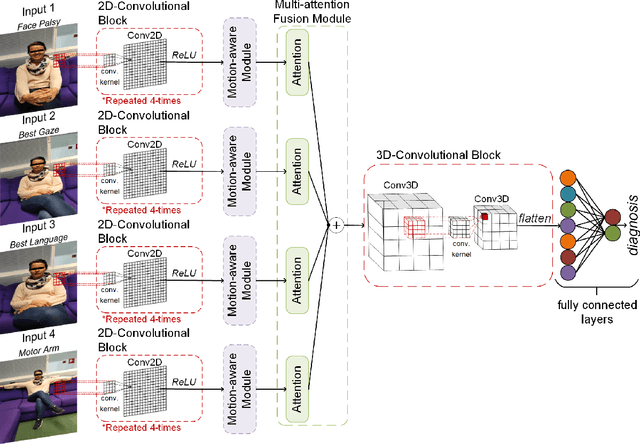
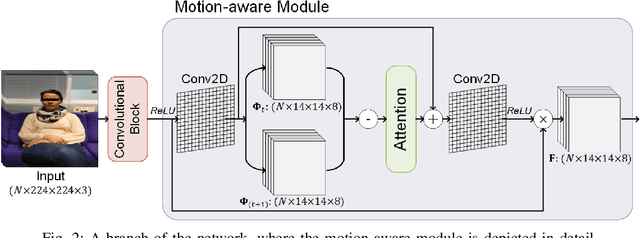
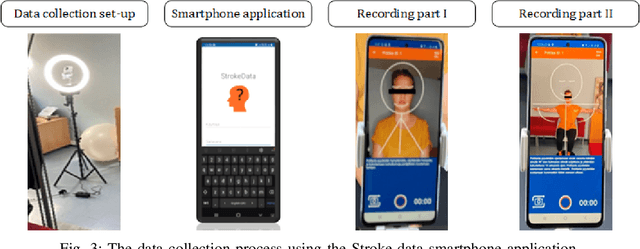
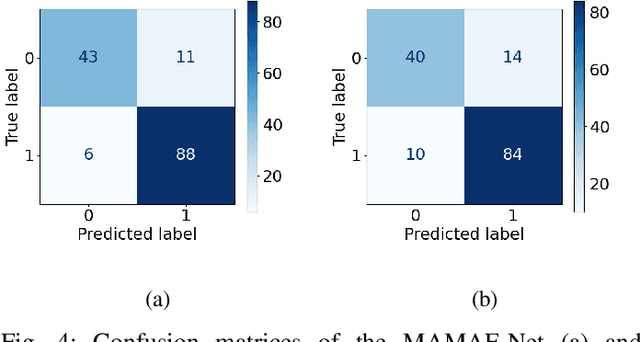
Stroke is a major cause of mortality and disability worldwide from which one in four people are in danger of incurring in their lifetime. The pre-hospital stroke assessment plays a vital role in identifying stroke patients accurately to accelerate further examination and treatment in hospitals. Accordingly, the National Institutes of Health Stroke Scale (NIHSS), Cincinnati Pre-hospital Stroke Scale (CPSS) and Face Arm Speed Time (F.A.S.T.) are globally known tests for stroke assessment. However, the validity of these tests is skeptical in the absence of neurologists. Therefore, in this study, we propose a motion-aware and multi-attention fusion network (MAMAF-Net) that can detect stroke from multimodal examination videos. Contrary to other studies on stroke detection from video analysis, our study for the first time proposes an end-to-end solution from multiple video recordings of each subject with a dataset encapsulating stroke, transient ischemic attack (TIA), and healthy controls. The proposed MAMAF-Net consists of motion-aware modules to sense the mobility of patients, attention modules to fuse the multi-input video data, and 3D convolutional layers to perform diagnosis from the attention-based extracted features. Experimental results over the collected StrokeDATA dataset show that the proposed MAMAF-Net achieves a successful detection of stroke with 93.62% sensitivity and 95.33% AUC score.
R2C-GAN: Restore-to-Classify GANs for Blind X-Ray Restoration and COVID-19 Classification
Sep 29, 2022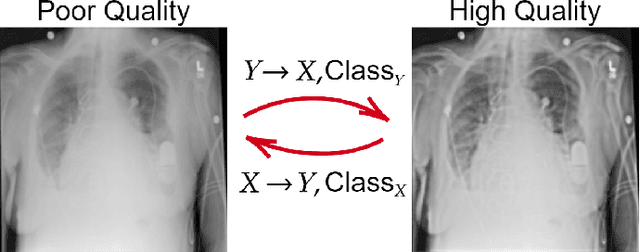
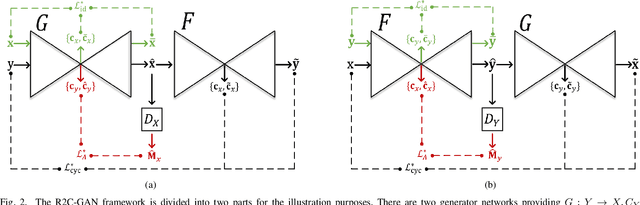
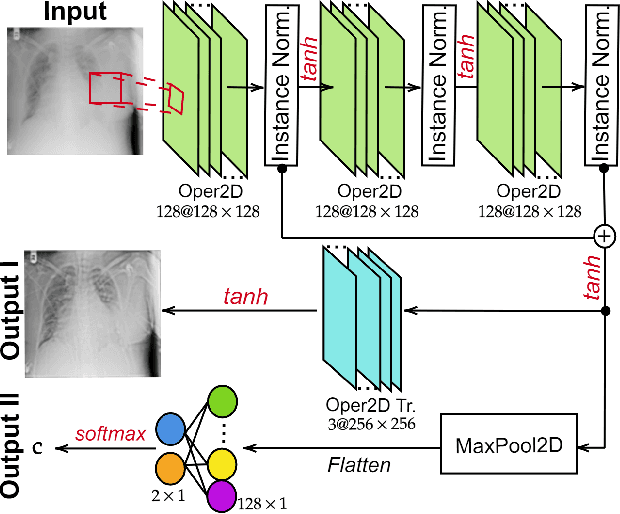
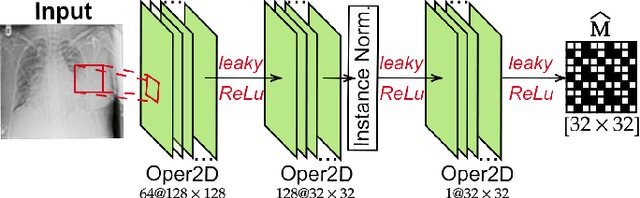
Restoration of poor quality images with a blended set of artifacts plays a vital role for a reliable diagnosis. Existing studies have focused on specific restoration problems such as image deblurring, denoising, and exposure correction where there is usually a strong assumption on the artifact type and severity. As a pioneer study in blind X-ray restoration, we propose a joint model for generic image restoration and classification: Restore-to-Classify Generative Adversarial Networks (R2C-GANs). Such a jointly optimized model keeps any disease intact after the restoration. Therefore, this will naturally lead to a higher diagnosis performance thanks to the improved X-ray image quality. To accomplish this crucial objective, we define the restoration task as an Image-to-Image translation problem from poor quality having noisy, blurry, or over/under-exposed images to high quality image domain. The proposed R2C-GAN model is able to learn forward and inverse transforms between the two domains using unpaired training samples. Simultaneously, the joint classification preserves the disease label during restoration. Moreover, the R2C-GANs are equipped with operational layers/neurons reducing the network depth and further boosting both restoration and classification performances. The proposed joint model is extensively evaluated over the QaTa-COV19 dataset for Coronavirus Disease 2019 (COVID-19) classification. The proposed restoration approach achieves over 90% F1-Score which is significantly higher than the performance of any deep model. Moreover, in the qualitative analysis, the restoration performance of R2C-GANs is approved by a group of medical doctors. We share the software implementation at https://github.com/meteahishali/R2C-GAN.
Early Myocardial Infarction Detection with One-Class Classification over Multi-view Echocardiography
Apr 14, 2022

Myocardial infarction (MI) is the leading cause of mortality and morbidity in the world. Early therapeutics of MI can ensure the prevention of further myocardial necrosis. Echocardiography is the fundamental imaging technique that can reveal the earliest sign of MI. However, the scarcity of echocardiographic datasets for the MI detection is the major issue for training data-driven classification algorithms. In this study, we propose a framework for early detection of MI over multi-view echocardiography that leverages one-class classification (OCC) techniques. The OCC techniques are used to train a model for detecting a specific target class using instances from that particular category only. We investigated the usage of uni-modal and multi-modal one-class classification techniques in the proposed framework using the HMC-QU dataset that includes apical 4-chamber (A4C) and apical 2-chamber (A2C) views in a total of 260 echocardiography recordings. Experimental results show that the multi-modal approach achieves a sensitivity level of 85.23% and F1-Score of 80.21%.
OSegNet: Operational Segmentation Network for COVID-19 Detection using Chest X-ray Images
Feb 21, 2022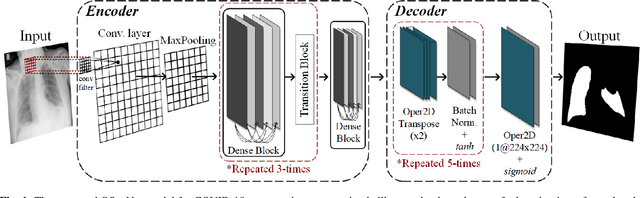



Coronavirus disease 2019 (COVID-19) has been diagnosed automatically using Machine Learning algorithms over chest X-ray (CXR) images. However, most of the earlier studies used Deep Learning models over scarce datasets bearing the risk of overfitting. Additionally, previous studies have revealed the fact that deep networks are not reliable for classification since their decisions may originate from irrelevant areas on the CXRs. Therefore, in this study, we propose Operational Segmentation Network (OSegNet) that performs detection by segmenting COVID-19 pneumonia for a reliable diagnosis. To address the data scarcity encountered in training and especially in evaluation, this study extends the largest COVID-19 CXR dataset: QaTa-COV19 with 121,378 CXRs including 9258 COVID-19 samples with their corresponding ground-truth segmentation masks that are publicly shared with the research community. Consequently, OSegNet has achieved a detection performance with the highest accuracy of 99.65% among the state-of-the-art deep models with 98.09% precision.
Early Myocardial Infarction Detection over Multi-view Echocardiography
Nov 09, 2021
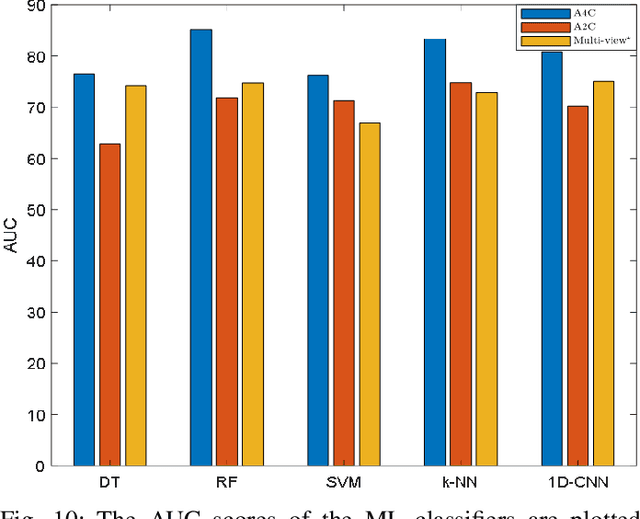


Myocardial infarction (MI) is the leading cause of mortality in the world that occurs due to a blockage of the coronary arteries feeding the myocardium. An early diagnosis of MI and its localization can mitigate the extent of myocardial damage by facilitating early therapeutic interventions. Following the blockage of a coronary artery, the regional wall motion abnormality (RWMA) of the ischemic myocardial segments is the earliest change to set in. Echocardiography is the fundamental tool to assess any RWMA. Assessing the motion of the left ventricle (LV) wall only from a single echocardiography view may lead to missing the diagnosis of MI as the RWMA may not be visible on that specific view. Therefore, in this study, we propose to fuse apical 4-chamber (A4C) and apical 2-chamber (A2C) views in which a total of 11 myocardial segments can be analyzed for MI detection. The proposed method first estimates the motion of the LV wall by Active Polynomials (APs), which extract and track the endocardial boundary to compute myocardial segment displacements. The features are extracted from the A4C and A2C view displacements, which are fused and fed into the classifiers to detect MI. The main contributions of this study are 1) creation of a new benchmark dataset by including both A4C and A2C views in a total of 260 echocardiography recordings, which is publicly shared with the research community, 2) improving the performance of the prior work of threshold-based APs by a Machine Learning based approach, and 3) a pioneer MI detection approach via multi-view echocardiography by fusing the information of A4C and A2C views. Experimental results show that the proposed method achieves 90.91% sensitivity and 86.36% precision for MI detection over multi-view echocardiography.
Reliable COVID-19 Detection Using Chest X-ray Images
Jan 28, 2021

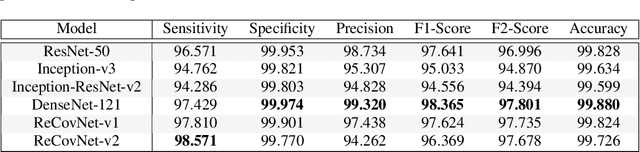
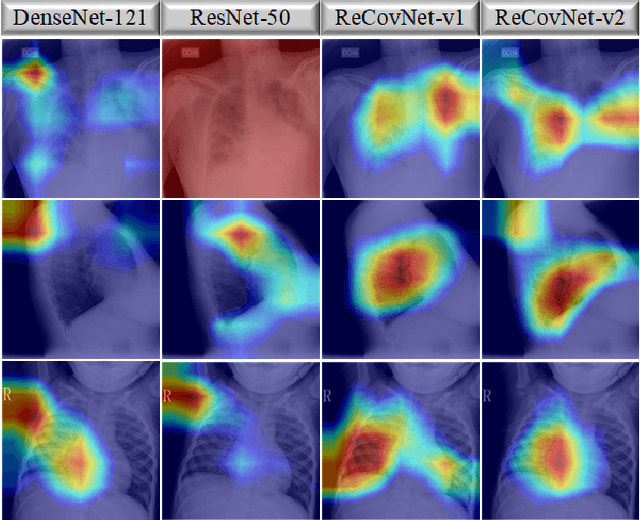
Coronavirus disease 2019 (COVID-19) has emerged the need for computer-aided diagnosis with automatic, accurate, and fast algorithms. Recent studies have applied Machine Learning algorithms for COVID-19 diagnosis over chest X-ray (CXR) images. However, the data scarcity in these studies prevents a reliable evaluation with the potential of overfitting and limits the performance of deep networks. Moreover, these networks can discriminate COVID-19 pneumonia usually from healthy subjects only or occasionally, from limited pneumonia types. Thus, there is a need for a robust and accurate COVID-19 detector evaluated over a large CXR dataset. To address this need, in this study, we propose a reliable COVID-19 detection network: ReCovNet, which can discriminate COVID-19 pneumonia from 14 different thoracic diseases and healthy subjects. To accomplish this, we have compiled the largest COVID-19 CXR dataset: QaTa-COV19 with 124,616 images including 4603 COVID-19 samples. The proposed ReCovNet achieved a detection performance with 98.57% sensitivity and 99.77% specificity.
Early Detection of Myocardial Infarction in Low-Quality Echocardiography
Oct 05, 2020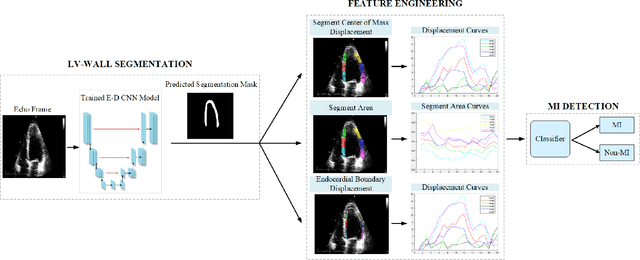
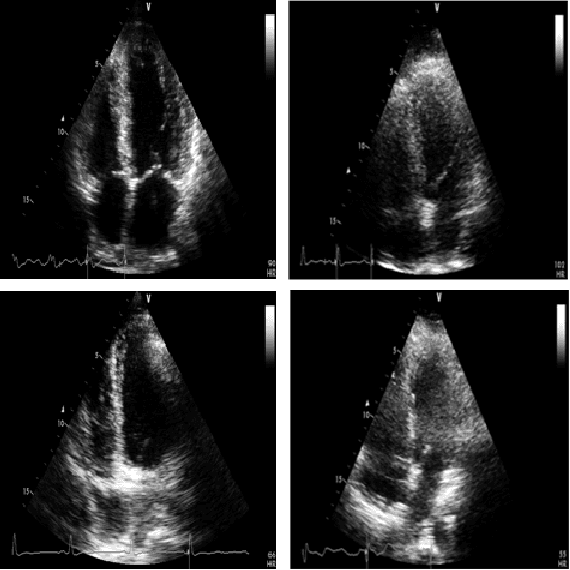
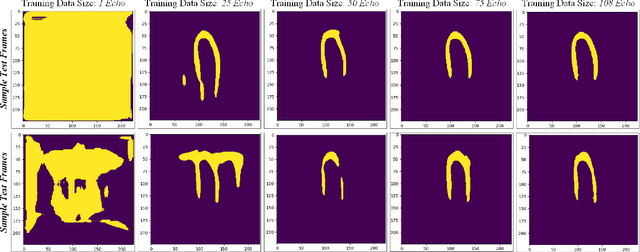
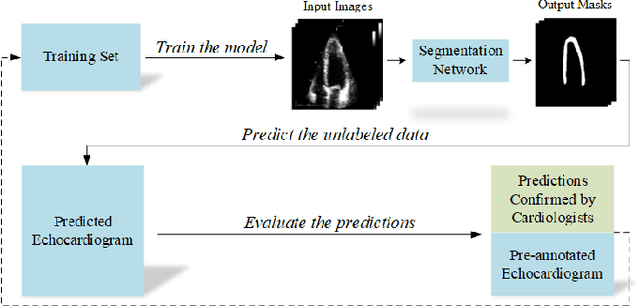
Myocardial infarction (MI), or commonly known as heart attack, is a life-threatening worldwide health problem from which 32.4 million of people suffer each year. Early diagnosis and treatment of MI are crucial to prevent further heart tissue damages. However, MI detection in early stages is challenging because the symptoms are not easy to distinguish in electrocardiography findings or biochemical marker values found in the blood. Echocardiography is a noninvasive clinical tool for a more accurate early MI diagnosis, which is used to analyze the regional wall motion abnormalities. When echocardiography quality is poor, the diagnosis becomes a challenging and sometimes infeasible task even for a cardiologist. In this paper, we introduce a three-phase approach for early MI detection in low-quality echocardiography: 1) segmentation of the entire left ventricle (LV) wall of the heart using state-of-the-art deep learning model, 2) analysis of the segmented LV wall by feature engineering, and 3) early MI detection. The main contributions of this study are: highly accurate segmentation of the LV wall from low-resolution (both temporal and spatial) and noisy echocardiographic data, generating the segmentation ground-truth at pixel-level for the unannotated dataset using pseudo labeling approach, and composition of the first public echocardiographic dataset (HMC-QU) labeled by the cardiologists at the Hamad Medical Corporation Hospital in Qatar. Furthermore, the outputs of the proposed approach can significantly help cardiologists for a better assessment of the LV wall characteristics. The proposed method is evaluated in a 5-fold cross validation scheme on the HMC-QU dataset. The proposed approach has achieved an average level of 95.72% sensitivity and 99.58% specificity for the LV wall segmentation, and 85.97% sensitivity, 74.03% specificity, and 86.85% precision for MI detection.