 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Tensorial Summation and Dimensional Reduction Guided Neural Network for Edge Detection
Apr 22, 2025



Edge detection has attracted considerable attention thanks to its exceptional ability to enhance performance in downstream computer vision tasks. In recent years, various deep learning methods have been explored for edge detection tasks resulting in a significant performance improvement compared to conventional computer vision algorithms. In neural networks, edge detection tasks require considerably large receptive fields to provide satisfactory performance. In a typical convolutional operation, such a large receptive field can be achieved by utilizing a significant number of consecutive layers, which yields deep network structures. Recently, a Multi-scale Tensorial Summation (MTS) factorization operator was presented, which can achieve very large receptive fields even from the initial layers. In this paper, we propose a novel MTS Dimensional Reduction (MTS-DR) module guided neural network, MTS-DR-Net, for the edge detection task. The MTS-DR-Net uses MTS layers, and corresponding MTS-DR blocks as a new backbone to remove redundant information initially. Such a dimensional reduction module enables the neural network to focus specifically on relevant information (i.e., necessary subspaces). Finally, a weight U-shaped refinement module follows MTS-DR blocks in the MTS-DR-Net. We conducted extensive experiments on two benchmark edge detection datasets: BSDS500 and BIPEDv2 to verify the effectiveness of our model. The implementation of the proposed MTS-DR-Net can be found at https://github.com/LeiXuAI/MTS-DR-Net.git.
ADA-Net: Attention-Guided Domain Adaptation Network with Contrastive Learning for Standing Dead Tree Segmentation Using Aerial Imagery
Apr 05, 2025Information on standing dead trees is important for understanding forest ecosystem functioning and resilience but has been lacking over large geographic regions. Climate change has caused large-scale tree mortality events that can remain undetected due to limited data. In this study, we propose a novel method for segmenting standing dead trees using aerial multispectral orthoimages. Because access to annotated datasets has been a significant problem in forest remote sensing due to the need for forest expertise, we introduce a method for domain transfer by leveraging domain adaptation to learn a transformation from a source domain X to target domain Y. In this Image-to-Image translation task, we aim to utilize available annotations in the target domain by pre-training a segmentation network. When images from a new study site without annotations are introduced (source domain X), these images are transformed into the target domain. Then, transfer learning is applied by inferring the pre-trained network on domain-adapted images. In addition to investigating the feasibility of current domain adaptation approaches for this objective, we propose a novel approach called the Attention-guided Domain Adaptation Network (ADA-Net) with enhanced contrastive learning. Accordingly, the ADA-Net approach provides new state-of-the-art domain adaptation performance levels outperforming existing approaches. We have evaluated the proposed approach using two datasets from Finland and the US. The USA images are converted to the Finland domain, and we show that the synthetic USA2Finland dataset exhibits similar characteristics to the Finland domain images. The software implementation is shared at https://github.com/meteahishali/ADA-Net. The data is publicly available at https://www.kaggle.com/datasets/meteahishali/aerial-imagery-for-standing-dead-tree-segmentation.
Dual-Task Learning for Dead Tree Detection and Segmentation with Hybrid Self-Attention U-Nets in Aerial Imagery
Mar 27, 2025Mapping standing dead trees is critical for assessing forest health, monitoring biodiversity, and mitigating wildfire risks, for which aerial imagery has proven useful. However, dense canopy structures, spectral overlaps between living and dead vegetation, and over-segmentation errors limit the reliability of existing methods. This study introduces a hybrid postprocessing framework that refines deep learning-based tree segmentation by integrating watershed algorithms with adaptive filtering, enhancing boundary delineation, and reducing false positives in complex forest environments. Tested on high-resolution aerial imagery from boreal forests, the framework improved instance-level segmentation accuracy by 41.5% and reduced positional errors by 57%, demonstrating robust performance in densely vegetated regions. By balancing detection accuracy and over-segmentation artifacts, the method enabled the precise identification of individual dead trees, which is critical for ecological monitoring. The framework's computational efficiency supports scalable applications, such as wall-to-wall tree mortality mapping over large geographic regions using aerial or satellite imagery. These capabilities directly benefit wildfire risk assessment (identifying fuel accumulations), carbon stock estimation (tracking emissions from decaying biomass), and precision forestry (targeting salvage loggings). By bridging advanced remote sensing techniques with practical forest management needs, this work advances tools for large-scale ecological conservation and climate resilience planning.
Audio-based Anomaly Detection in Industrial Machines Using Deep One-Class Support Vector Data Description
Dec 14, 2024The frequent breakdowns and malfunctions of industrial equipment have driven increasing interest in utilizing cost-effective and easy-to-deploy sensors, such as microphones, for effective condition monitoring of machinery. Microphones offer a low-cost alternative to widely used condition monitoring sensors with their high bandwidth and capability to detect subtle anomalies that other sensors might have less sensitivity. In this study, we investigate malfunctioning industrial machines to evaluate and compare anomaly detection performance across different machine types and fault conditions. Log-Mel spectrograms of machinery sound are used as input, and the performance is evaluated using the area under the curve (AUC) score for two different methods: baseline dense autoencoder (AE) and one-class deep Support Vector Data Description (deep SVDD) with different subspace dimensions. Our results over the MIMII sound dataset demonstrate that the deep SVDD method with a subspace dimension of 2 provides superior anomaly detection performance, achieving average AUC scores of 0.84, 0.80, and 0.69 for 6 dB, 0 dB, and -6 dB signal-to-noise ratios (SNRs), respectively, compared to 0.82, 0.72, and 0.64 for the baseline model. Moreover, deep SVDD requires 7.4 times fewer trainable parameters than the baseline dense AE, emphasizing its advantage in both effectiveness and computational efficiency.
Echocardiography to Cardiac MRI View Transformation for Real-Time Blind Restoration
Dec 09, 2024



Echocardiography is the most widely used imaging to monitor cardiac functions, serving as the first line in early detection of myocardial ischemia and infarction. However, echocardiography often suffers from several artifacts including sensor noise, lack of contrast, severe saturation, and missing myocardial segments which severely limit its usage in clinical diagnosis. In recent years, several machine learning methods have been proposed to improve echocardiography views. Yet, these methods usually address only a specific problem (e.g. denoising) and thus cannot provide a robust and reliable restoration in general. On the other hand, cardiac MRI provides a clean view of the heart without suffering such severe issues. However, due to its significantly higher cost, it is often only afforded by a few major hospitals, hence hindering its use and accessibility. In this pilot study, we propose a novel approach to transform echocardiography into the cardiac MRI view. For this purpose, Echo2MRI dataset, consisting of echocardiography and real cardiac MRI image pairs, is composed and will be shared publicly. A dedicated Cycle-consistent Generative Adversarial Network (Cycle-GAN) is trained to learn the transformation from echocardiography frames to cardiac MRI views. An extensive set of qualitative evaluations shows that the proposed transformer can synthesize high-quality artifact-free synthetic cardiac MRI views from a given sequence of echocardiography frames. Medical evaluations performed by a group of cardiologists further demonstrate that synthetic MRI views are indistinguishable from their original counterparts and are preferred over their initial sequence of echocardiography frames for diagnosis in 78.9% of the cases.
Dropout Concrete Autoencoder for Band Selection on HSI Scenes
Jan 29, 2024Deep learning-based informative band selection methods on hyperspectral images (HSI) recently have gained intense attention to eliminate spectral correlation and redundancies. However, the existing deep learning-based methods either need additional post-processing strategies to select the descriptive bands or optimize the model indirectly, due to the parameterization inability of discrete variables for the selection procedure. To overcome these limitations, this work proposes a novel end-to-end network for informative band selection. The proposed network is inspired by the advances in concrete autoencoder (CAE) and dropout feature ranking strategy. Different from the traditional deep learning-based methods, the proposed network is trained directly given the required band subset eliminating the need for further post-processing. Experimental results on four HSI scenes show that the proposed dropout CAE achieves substantial and effective performance levels outperforming the competing methods.
SAF-Net: Self-Attention Fusion Network for Myocardial Infarction Detection using Multi-View Echocardiography
Sep 27, 2023


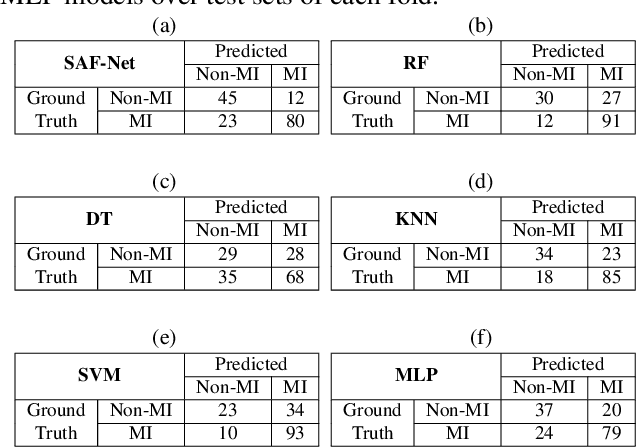
Myocardial infarction (MI) is a severe case of coronary artery disease (CAD) and ultimately, its detection is substantial to prevent progressive damage to the myocardium. In this study, we propose a novel view-fusion model named self-attention fusion network (SAF-Net) to detect MI from multi-view echocardiography recordings. The proposed framework utilizes apical 2-chamber (A2C) and apical 4-chamber (A4C) view echocardiography recordings for classification. Three reference frames are extracted from each recording of both views and deployed pre-trained deep networks to extract highly representative features. The SAF-Net model utilizes a self-attention mechanism to learn dependencies in extracted feature vectors. The proposed model is computationally efficient thanks to its compact architecture having three main parts: a feature embedding to reduce dimensionality, self-attention for view-pooling, and dense layers for the classification. Experimental evaluation is performed using the HMC-QU-TAU dataset which consists of 160 patients with A2C and A4C view echocardiography recordings. The proposed SAF-Net model achieves a high-performance level with 88.26% precision, 77.64% sensitivity, and 78.13% accuracy. The results demonstrate that the SAF-Net model achieves the most accurate MI detection over multi-view echocardiography recordings.
Operational Support Estimator Networks
Jul 13, 2023



In this work, we propose a novel approach called Operational Support Estimator Networks (OSENs) for the support estimation task. Support Estimation (SE) is defined as finding the locations of non-zero elements in a sparse signal. By its very nature, the mapping between the measurement and sparse signal is a non-linear operation. Traditional support estimators rely on computationally expensive iterative signal recovery techniques to achieve such non-linearity. Contrary to the convolution layers, the proposed OSEN approach consists of operational layers that can learn such complex non-linearities without the need for deep networks. In this way, the performance of the non-iterative support estimation is greatly improved. Moreover, the operational layers comprise so-called generative \textit{super neurons} with non-local kernels. The kernel location for each neuron/feature map is optimized jointly for the SE task during the training. We evaluate the OSENs in three different applications: i. support estimation from Compressive Sensing (CS) measurements, ii. representation-based classification, and iii. learning-aided CS reconstruction where the output of OSENs is used as prior knowledge to the CS algorithm for an enhanced reconstruction. Experimental results show that the proposed approach achieves computational efficiency and outperforms competing methods, especially at low measurement rates by a significant margin. The software implementation is publicly shared at https://github.com/meteahishali/OSEN.
Improved Active Fire Detection using Operational U-Nets
Apr 19, 2023


As a consequence of global warming and climate change, the risk and extent of wildfires have been increasing in many areas worldwide. Warmer temperatures and drier conditions can cause quickly spreading fires and make them harder to control; therefore, early detection and accurate locating of active fires are crucial in environmental monitoring. Using satellite imagery to monitor and detect active fires has been critical for managing forests and public land. Many traditional statistical-based methods and more recent deep-learning techniques have been proposed for active fire detection. In this study, we propose a novel approach called Operational U-Nets for the improved early detection of active fires. The proposed approach utilizes Self-Organized Operational Neural Network (Self-ONN) layers in a compact U-Net architecture. The preliminary experimental results demonstrate that Operational U-Nets not only achieve superior detection performance but can also significantly reduce computational complexity.
Hyperspectral Image Analysis with Subspace Learning-based One-Class Classification
Apr 19, 2023Hyperspectral image (HSI) classification is an important task in many applications, such as environmental monitoring, medical imaging, and land use/land cover (LULC) classification. Due to the significant amount of spectral information from recent HSI sensors, analyzing the acquired images is challenging using traditional Machine Learning (ML) methods. As the number of frequency bands increases, the required number of training samples increases exponentially to achieve a reasonable classification accuracy, also known as the curse of dimensionality. Therefore, separate band selection or dimensionality reduction techniques are often applied before performing any classification task over HSI data. In this study, we investigate recently proposed subspace learning methods for one-class classification (OCC). These methods map high-dimensional data to a lower-dimensional feature space that is optimized for one-class classification. In this way, there is no separate dimensionality reduction or feature selection procedure needed in the proposed classification framework. Moreover, one-class classifiers have the ability to learn a data description from the category of a single class only. Considering the imbalanced labels of the LULC classification problem and rich spectral information (high number of dimensions), the proposed classification approach is well-suited for HSI data. Overall, this is a pioneer study focusing on subspace learning-based one-class classification for HSI data. We analyze the performance of the proposed subspace learning one-class classifiers in the proposed pipeline. Our experiments validate that the proposed approach helps tackle the curse of dimensionality along with the imbalanced nature of HSI data.