 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADA-Net: Attention-Guided Domain Adaptation Network with Contrastive Learning for Standing Dead Tree Segmentation Using Aerial Imagery
Apr 05, 2025Information on standing dead trees is important for understanding forest ecosystem functioning and resilience but has been lacking over large geographic regions. Climate change has caused large-scale tree mortality events that can remain undetected due to limited data. In this study, we propose a novel method for segmenting standing dead trees using aerial multispectral orthoimages. Because access to annotated datasets has been a significant problem in forest remote sensing due to the need for forest expertise, we introduce a method for domain transfer by leveraging domain adaptation to learn a transformation from a source domain X to target domain Y. In this Image-to-Image translation task, we aim to utilize available annotations in the target domain by pre-training a segmentation network. When images from a new study site without annotations are introduced (source domain X), these images are transformed into the target domain. Then, transfer learning is applied by inferring the pre-trained network on domain-adapted images. In addition to investigating the feasibility of current domain adaptation approaches for this objective, we propose a novel approach called the Attention-guided Domain Adaptation Network (ADA-Net) with enhanced contrastive learning. Accordingly, the ADA-Net approach provides new state-of-the-art domain adaptation performance levels outperforming existing approaches. We have evaluated the proposed approach using two datasets from Finland and the US. The USA images are converted to the Finland domain, and we show that the synthetic USA2Finland dataset exhibits similar characteristics to the Finland domain images. The software implementation is shared at https://github.com/meteahishali/ADA-Net. The data is publicly available at https://www.kaggle.com/datasets/meteahishali/aerial-imagery-for-standing-dead-tree-segmentation.
Dual-Task Learning for Dead Tree Detection and Segmentation with Hybrid Self-Attention U-Nets in Aerial Imagery
Mar 27, 2025Mapping standing dead trees is critical for assessing forest health, monitoring biodiversity, and mitigating wildfire risks, for which aerial imagery has proven useful. However, dense canopy structures, spectral overlaps between living and dead vegetation, and over-segmentation errors limit the reliability of existing methods. This study introduces a hybrid postprocessing framework that refines deep learning-based tree segmentation by integrating watershed algorithms with adaptive filtering, enhancing boundary delineation, and reducing false positives in complex forest environments. Tested on high-resolution aerial imagery from boreal forests, the framework improved instance-level segmentation accuracy by 41.5% and reduced positional errors by 57%, demonstrating robust performance in densely vegetated regions. By balancing detection accuracy and over-segmentation artifacts, the method enabled the precise identification of individual dead trees, which is critical for ecological monitoring. The framework's computational efficiency supports scalable applications, such as wall-to-wall tree mortality mapping over large geographic regions using aerial or satellite imagery. These capabilities directly benefit wildfire risk assessment (identifying fuel accumulations), carbon stock estimation (tracking emissions from decaying biomass), and precision forestry (targeting salvage loggings). By bridging advanced remote sensing techniques with practical forest management needs, this work advances tools for large-scale ecological conservation and climate resilience planning.
Deep dual stream residual network with contextual attention for pansharpening of remote sensing images
Jul 25, 2022
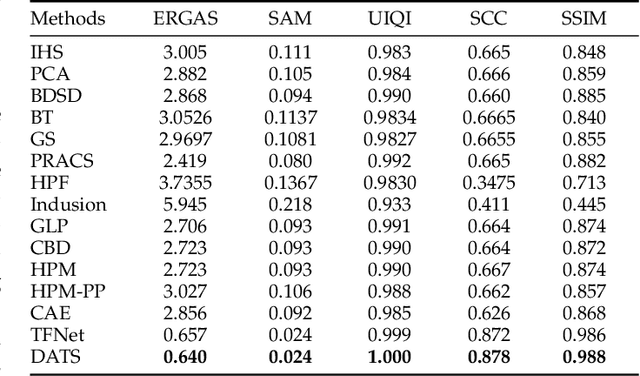

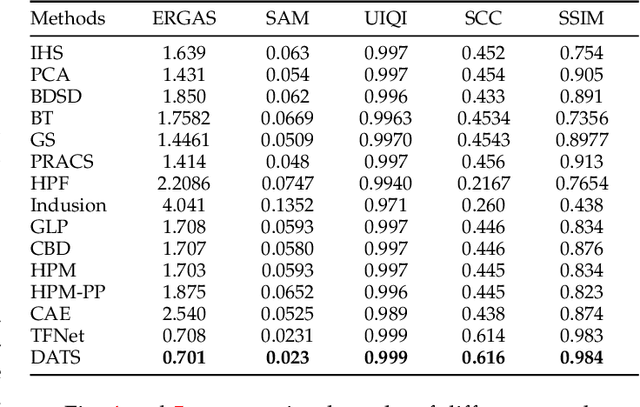
Pansharpening enhances spatial details of high spectral resolution multispectral images using features of high spatial resolution panchromatic image. There are a number of traditional pansharpening approaches but producing an image exhibiting high spectral and spatial fidelity is still an open problem. Recently, deep learning has been used to produce promising pansharpened images; however, most of these approaches apply similar treatment to both multispectral and panchromatic images by using the same network for feature extraction. In this work, we present present a novel dual attention-based two-stream network. It starts with feature extraction using two separate networks for both images, an encoder with attention mechanism to recalibrate the extracted features. This is followed by fusion of the features forming a compact representation fed into an image reconstruction network to produce a pansharpened image. The experimental results on the Pl\'{e}iades dataset using standard quantitative evaluation metrics and visual inspection demonstrates that the proposed approach performs better than other approaches in terms of pansharpened image quality.
Audiovisual Saliency Prediction in Uncategorized Video Sequences based on Audio-Video Correlation
Jan 07, 2021

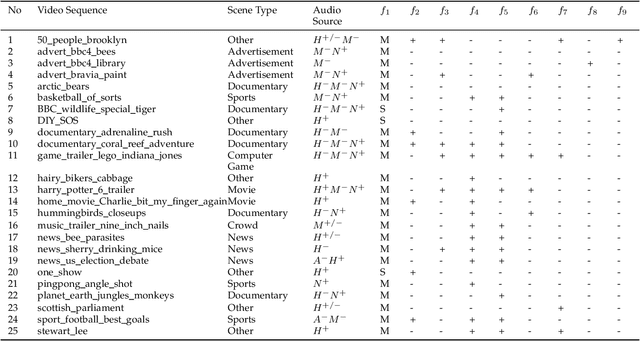

Substantial research has been done in saliency modeling to develop intelligent machines that can perceive and interpret their surroundings. But existing models treat videos as merely image sequences excluding any audio information, unable to cope with inherently varying content. Based on the hypothesis that an audiovisual saliency model will be an improvement over traditional saliency models for natural uncategorized videos, this work aims to provide a generic audio/video saliency model augmenting a visual saliency map with an audio saliency map computed by synchronizing low-level audio and visual features. The proposed model was evaluated using different criteria against eye fixations data for a publicly available DIEM video dataset. The results show that the model outperformed two state-of-the-art visual saliency models.