 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Saliency Prediction in Uncategorized Video Sequences based on Audio-Video Correlation
Jan 07, 2021

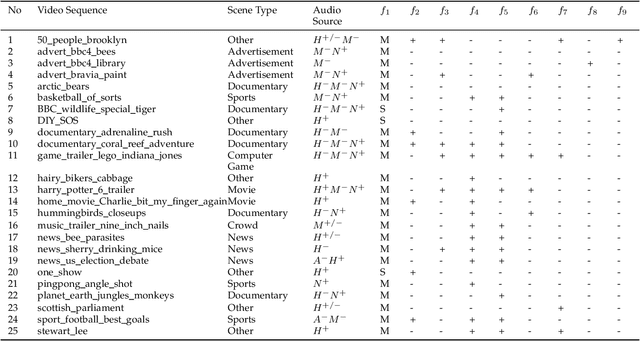

Substantial research has been done in saliency modeling to develop intelligent machines that can perceive and interpret their surroundings. But existing models treat videos as merely image sequences excluding any audio information, unable to cope with inherently varying content. Based on the hypothesis that an audiovisual saliency model will be an improvement over traditional saliency models for natural uncategorized videos, this work aims to provide a generic audio/video saliency model augmenting a visual saliency map with an audio saliency map computed by synchronizing low-level audio and visual features. The proposed model was evaluated using different criteria against eye fixations data for a publicly available DIEM video dataset. The results show that the model outperformed two state-of-the-art visual saliency models.