 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTS-CSNet: Multiscale Tensor Factorization for Deep Compressive Sensing on RGB Images
Feb 04, 2026Deep learning based compressive sensing (CS) methods typically learn sampling operators using convolutional or block wise fully connected layers, which limit receptive fields and scale poorly for high dimensional data. We propose MTSCSNet, a CS framework based on Multiscale Tensor Summation (MTS) factorization, a structured operator for efficient multidimensional signal processing. MTS performs mode-wise linear transformations with multiscale summation, enabling large receptive fields and effective modeling of cross-dimensional correlations. In MTSCSNet, MTS is first used as a learnable CS operator that performs linear dimensionality reduction in tensor space, with its adjoint defining the initial back-projection, and is then applied in the reconstruction stage to directly refine this estimate. This results in a simple feed-forward architecture without iterative or proximal optimization, while remaining parameter and computation efficient. Experiments on standard CS benchmarks show that MTSCSNet achieves state-of-the-art reconstruction performance on RGB images, with notable PSNR gains and faster inference, even compared to recent diffusion-based CS methods, while using a significantly more compact feed-forward architecture.
Multi-Scale Tensorial Summation and Dimensional Reduction Guided Neural Network for Edge Detection
Apr 22, 2025



Edge detection has attracted considerable attention thanks to its exceptional ability to enhance performance in downstream computer vision tasks. In recent years, various deep learning methods have been explored for edge detection tasks resulting in a significant performance improvement compared to conventional computer vision algorithms. In neural networks, edge detection tasks require considerably large receptive fields to provide satisfactory performance. In a typical convolutional operation, such a large receptive field can be achieved by utilizing a significant number of consecutive layers, which yields deep network structures. Recently, a Multi-scale Tensorial Summation (MTS) factorization operator was presented, which can achieve very large receptive fields even from the initial layers. In this paper, we propose a novel MTS Dimensional Reduction (MTS-DR) module guided neural network, MTS-DR-Net, for the edge detection task. The MTS-DR-Net uses MTS layers, and corresponding MTS-DR blocks as a new backbone to remove redundant information initially. Such a dimensional reduction module enables the neural network to focus specifically on relevant information (i.e., necessary subspaces). Finally, a weight U-shaped refinement module follows MTS-DR blocks in the MTS-DR-Net. We conducted extensive experiments on two benchmark edge detection datasets: BSDS500 and BIPEDv2 to verify the effectiveness of our model. The implementation of the proposed MTS-DR-Net can be found at https://github.com/LeiXuAI/MTS-DR-Net.git.
Operational Support Estimator Networks
Jul 13, 2023



In this work, we propose a novel approach called Operational Support Estimator Networks (OSENs) for the support estimation task. Support Estimation (SE) is defined as finding the locations of non-zero elements in a sparse signal. By its very nature, the mapping between the measurement and sparse signal is a non-linear operation. Traditional support estimators rely on computationally expensive iterative signal recovery techniques to achieve such non-linearity. Contrary to the convolution layers, the proposed OSEN approach consists of operational layers that can learn such complex non-linearities without the need for deep networks. In this way, the performance of the non-iterative support estimation is greatly improved. Moreover, the operational layers comprise so-called generative \textit{super neurons} with non-local kernels. The kernel location for each neuron/feature map is optimized jointly for the SE task during the training. We evaluate the OSENs in three different applications: i. support estimation from Compressive Sensing (CS) measurements, ii. representation-based classification, and iii. learning-aided CS reconstruction where the output of OSENs is used as prior knowledge to the CS algorithm for an enhanced reconstruction. Experimental results show that the proposed approach achieves computational efficiency and outperforms competing methods, especially at low measurement rates by a significant margin. The software implementation is publicly shared at https://github.com/meteahishali/OSEN.
Deformable Convolutions and LSTM-based Flexible Event Frame Fusion Network for Motion Deblurring
Jun 01, 2023Event cameras differ from conventional RGB cameras in that they produce asynchronous data sequences. While RGB cameras capture every frame at a fixed rate, event cameras only capture changes in the scene, resulting in sparse and asynchronous data output. Despite the fact that event data carries useful information that can be utilized in motion deblurring of RGB cameras, integrating event and image information remains a challenge. Recent state-of-the-art CNN-based deblurring solutions produce multiple 2-D event frames based on the accumulation of event data over a time period. In most of these techniques, however, the number of event frames is fixed and predefined, which reduces temporal resolution drastically, particularly for scenarios when fast-moving objects are present or when longer exposure times are required. It is also important to note that recent modern cameras (e.g., cameras in mobile phones) dynamically set the exposure time of the image, which presents an additional problem for networks developed for a fixed number of event frames. A Long Short-Term Memory (LSTM)-based event feature extraction module has been developed for addressing these challenges, which enables us to use a dynamically varying number of event frames. Using these modules, we constructed a state-of-the-art deblurring network, Deformable Convolutions and LSTM-based Flexible Event Frame Fusion Network (DLEFNet). It is particularly useful for scenarios in which exposure times vary depending on factors such as lighting conditions or the presence of fast-moving objects in the scene. It has been demonstrated through evaluation results that the proposed method can outperform the existing state-of-the-art networks for deblurring task in synthetic and real-world data sets.
Operational Neural Networks for Efficient Hyperspectral Single-Image Super-Resolution
Mar 29, 2023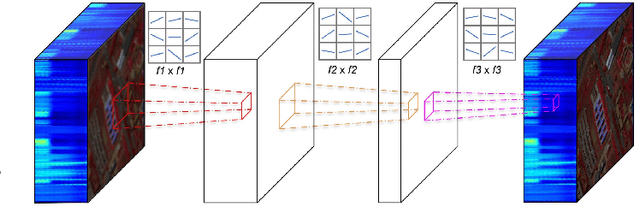
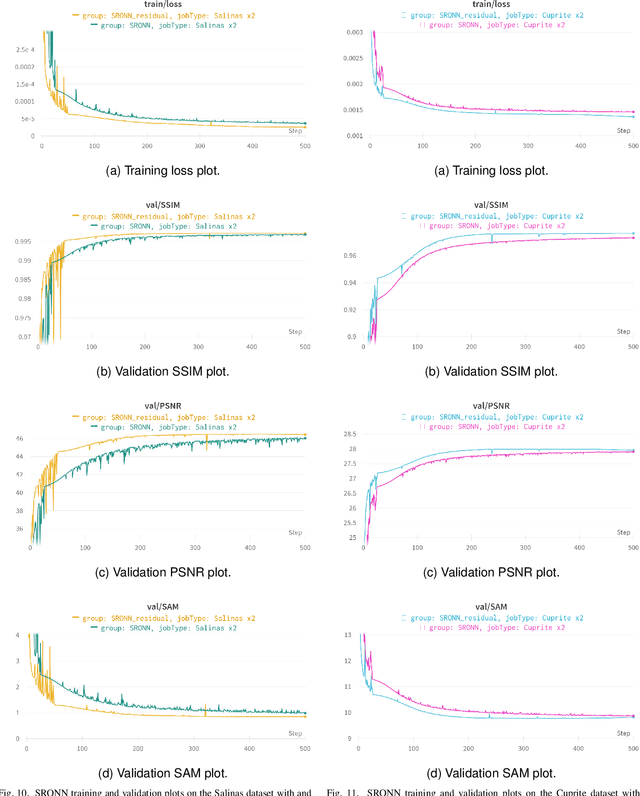
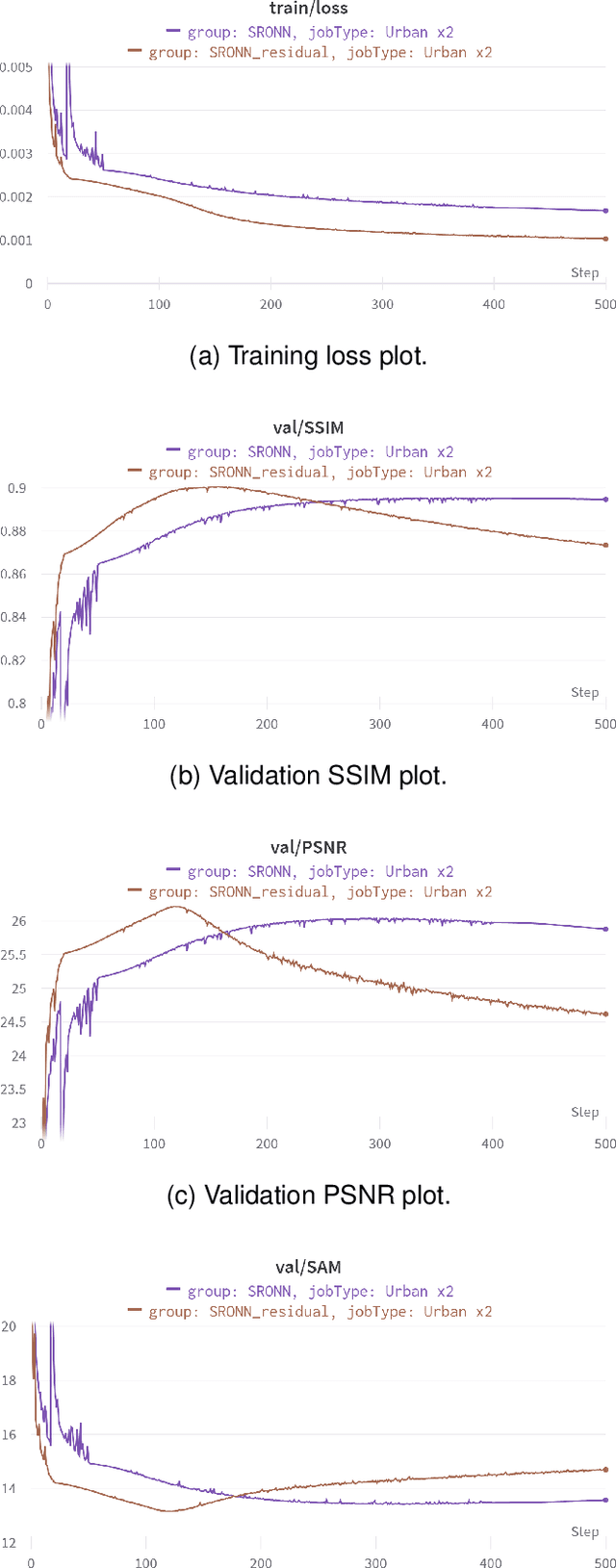
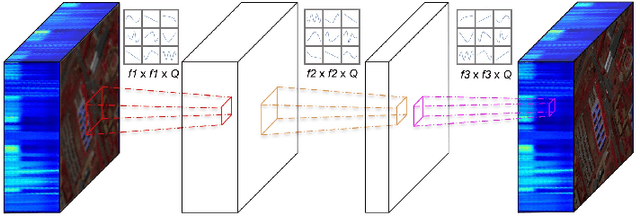
Hyperspectral Imaging is a crucial tool in remote sensing which captures far more spectral information than standard color images. However, the increase in spectral information comes at the cost of spatial resolution. Super-resolution is a popular technique where the goal is to generate a high-resolution version of a given low-resolution input. The majority of modern super-resolution approaches use convolutional neural networks. However, convolution itself is a linear operation and the networks rely on the non-linear activation functions after each layer to provide the necessary non-linearity to learn the complex underlying function. This means that convolutional neural networks tend to be very deep to achieve the desired results. Recently, self-organized operational neural networks have been proposed that aim to overcome this limitation by replacing the convolutional filters with learnable non-linear functions through the use of MacLaurin series expansions. This work focuses on extending the convolutional filters of a popular super-resolution model to more powerful operational filters to enhance the model performance on hyperspectral images. We also investigate the effects that residual connections and different normalization types have on this type of enhanced network. Despite having fewer parameters than their convolutional network equivalents, our results show that operational neural networks achieve superior super-resolution performance on small hyperspectral image datasets.
Generalized Tensor Summation Compressive Sensing Network (GTSNET): An Easy to Learn Compressive Sensing Operation
Aug 04, 2021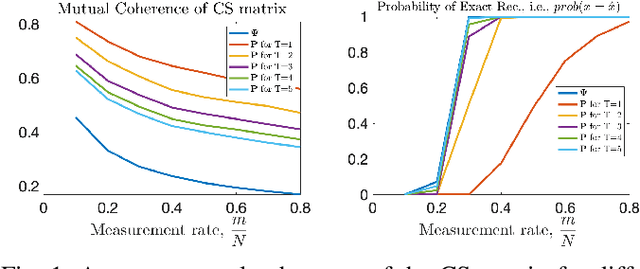


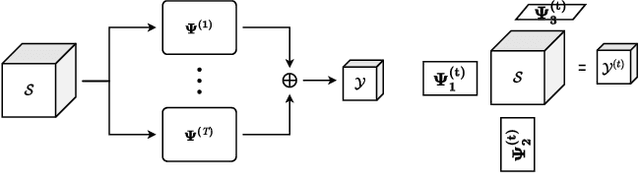
In CS literature, the efforts can be divided into two groups: finding a measurement matrix that preserves the compressed information at the maximum level, and finding a reconstruction algorithm for the compressed information. In the traditional CS setup, the measurement matrices are selected as random matrices, and optimization-based iterative solutions are used to recover the signals. However, when we handle large signals, using random matrices become cumbersome especially when it comes to iterative optimization-based solutions. Even though recent deep learning-based solutions boost the reconstruction accuracy performance while speeding up the recovery, still jointly learning the whole measurement matrix is a difficult process. In this work, we introduce a separable multi-linear learning of the CS matrix by representing it as the summation of arbitrary number of tensors. For a special case where the CS operation is set as a single tensor multiplication, the model is reduced to the learning-based separable CS; while a dense CS matrix can be approximated and learned as the summation of multiple tensors. Both cases can be used in CS of two or multi-dimensional signals e.g., images, multi-spectral images, videos, etc. Structural CS matrices can also be easily approximated and learned in our multi-linear separable learning setup with structural tensor sum representation. Hence, our learnable generalized tensor summation CS operation encapsulates most CS setups including separable CS, non-separable CS (traditional vector-matrix multiplication), structural CS, and CS of the multi-dimensional signals. For both gray-scale and RGB images, the proposed scheme surpasses most state-of-the-art solutions, especially in lower measurement rates. Although the performance gain remains limited from tensor to the sum of tensor representation for gray-scale images, it becomes significant in the RGB case.
Representation Based Regression for Object Distance Estimation
Jun 27, 2021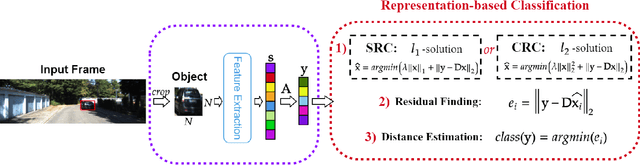
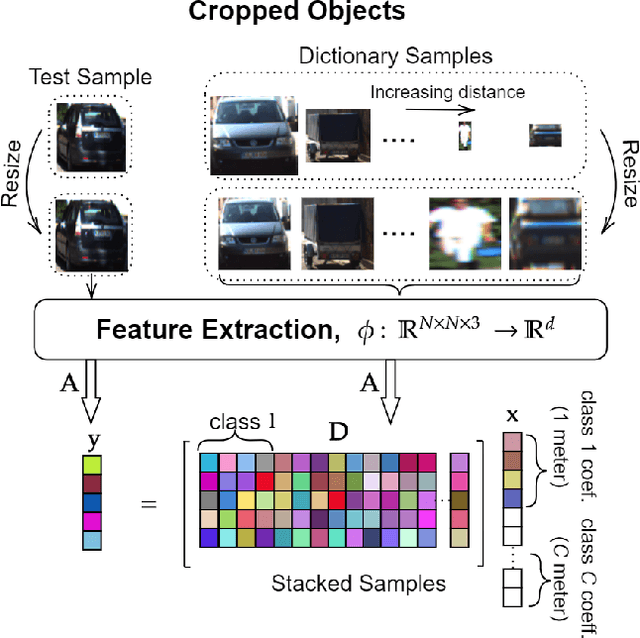
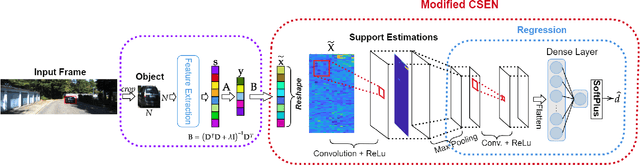
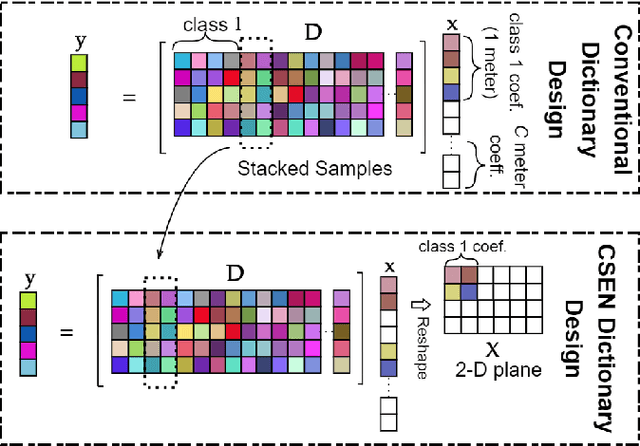
In this study, we propose a novel approach to predict the distances of the detected objects in an observed scene. The proposed approach modifies the recently proposed Convolutional Support Estimator Networks (CSENs). CSENs are designed to compute a direct mapping for the Support Estimation (SE) task in a representation-based classification problem. We further propose and demonstrate that representation-based methods (sparse or collaborative representation) can be used in well-designed regression problems. To the best of our knowledge, this is the first representation-based method proposed for performing a regression task by utilizing the modified CSENs; and hence, we name this novel approach as Representation-based Regression (RbR). The initial version of CSENs has a proxy mapping stage (i.e., a coarse estimation for the support set) that is required for the input. In this study, we improve the CSEN model by proposing Compressive Learning CSEN (CL-CSEN) that has the ability to jointly optimize the so-called proxy mapping stage along with convolutional layers. The experimental evaluations using the KITTI 3D Object Detection distance estimation dataset show that the proposed method can achieve a significantly improved distance estimation performance over all competing methods. Finally, the software implementations of the methods are publicly shared at https://github.com/meteahishali/CSENDistance.
Convolutional versus Self-Organized Operational Neural Networks for Real-World Blind Image Denoising
Mar 04, 2021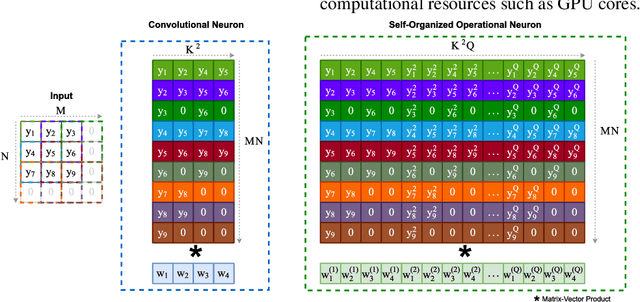
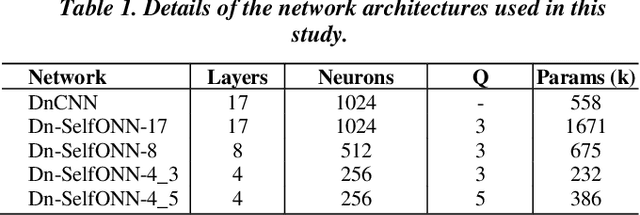

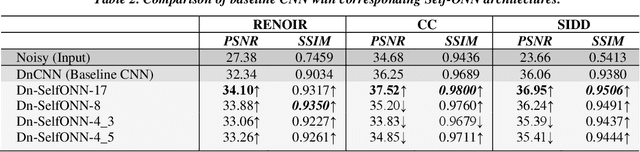
Real-world blind denoising poses a unique image restoration challenge due to the non-deterministic nature of the underlying noise distribution. Prevalent discriminative networks trained on synthetic noise models have been shown to generalize poorly to real-world noisy images. While curating real-world noisy images and improving ground truth estimation procedures remain key points of interest, a potential research direction is to explore extensions to the widely used convolutional neuron model to enable better generalization with fewer data and lower network complexity, as opposed to simply using deeper Convolutional Neural Networks (CNNs). Operational Neural Networks (ONNs) and their recent variant, Self-organized ONNs (Self-ONNs), propose to embed enhanced non-linearity into the neuron model and have been shown to outperform CNNs across a variety of regression tasks. However, all such comparisons have been made for compact networks and the efficacy of deploying operational layers as a drop-in replacement for convolutional layers in contemporary deep architectures remains to be seen. In this work, we tackle the real-world blind image denoising problem by employing, for the first time, a deep Self-ONN. Extensive quantitative and qualitative evaluations spanning multiple metrics and four high-resolution real-world noisy image datasets against the state-of-the-art deep CNN network, DnCNN, reveal that deep Self-ONNs consistently achieve superior results with performance gains of up to 1.76dB in PSNR. Furthermore, Self-ONNs with half and even quarter the number of layers that require only a fraction of computational resources as that of DnCNN can still achieve similar or better results compared to the state-of-the-art.
BM3D vs 2-Layer ONN
Mar 04, 2021
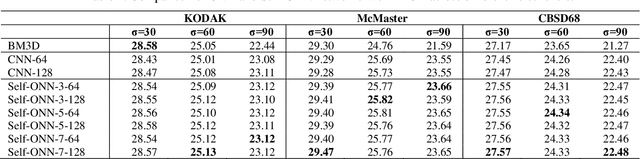
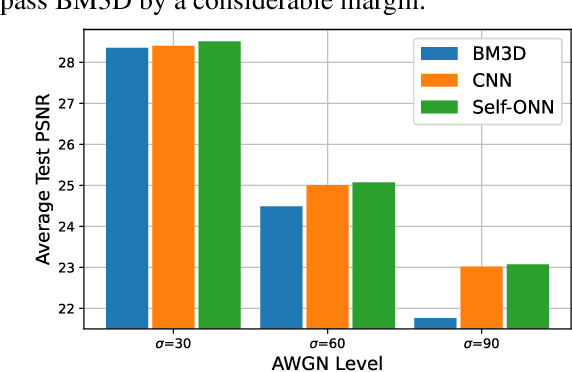
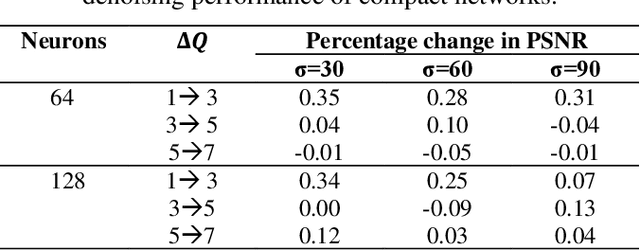
Despite their recent success on image denoising, the need for deep and complex architectures still hinders the practical usage of CNNs. Older but computationally more efficient methods such as BM3D remain a popular choice, especially in resource-constrained scenarios. In this study, we aim to find out whether compact neural networks can learn to produce competitive results as compared to BM3D for AWGN image denoising. To this end, we configure networks with only two hidden layers and employ different neuron models and layer widths for comparing the performance with BM3D across different AWGN noise levels. Our results conclusively show that the recently proposed self-organized variant of operational neural networks based on a generative neuron model (Self-ONNs) is not only a better choice as compared to CNNs, but also provide competitive results as compared to BM3D and even significantly surpass it for high noise levels.
COVID-19 Infection Map Generation and Detection from Chest X-Ray Images
Sep 26, 2020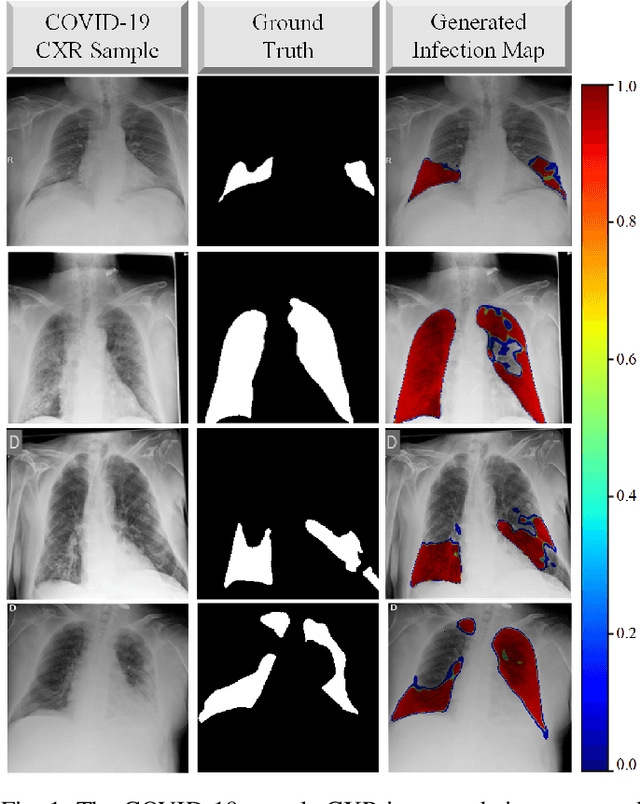
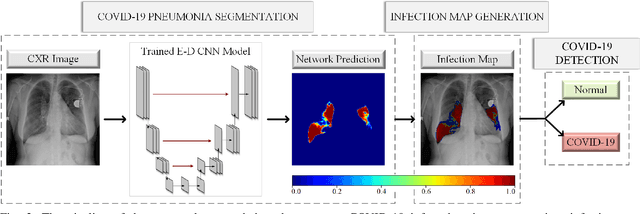
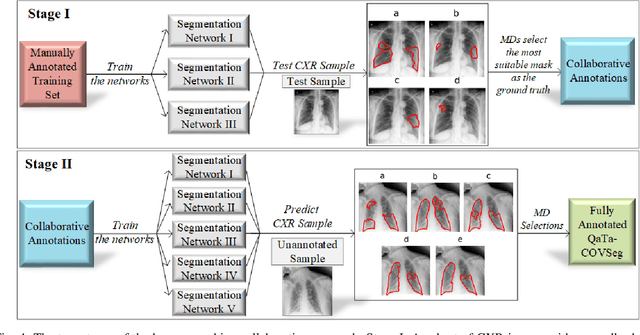
Computer-aided diagnosis has become a necessity for accurate and immediate coronavirus disease 2019 (COVID-19) detection to aid treatment and prevent the spread of the virus. Compared to other diagnosis methodologies, chest X-ray (CXR) imaging is an advantageous tool since it is fast, low-cost, and easily accessible. Thus, CXR has a great potential not only to help diagnose COVID-19 but also to track the progression of the disease. Numerous studies have proposed to use Deep Learning techniques for COVID-19 diagnosis. However, they have used very limited CXR image repositories for evaluation with a small number, a few hundreds, of COVID-19 samples. Moreover, these methods can neither localize nor grade the severity of COVID-19 infection. For this purpose, recent studies proposed to explore the activation maps of deep networks. However, they remain inaccurate for localizing the actual infestation making them unreliable for clinical use. This study proposes a novel method for the joint localization, severity grading, and detection of COVID-19 from CXR images by generating the so-called infection maps that can accurately localize and grade the severity of COVID-19 infection. To accomplish this, we have compiled the largest COVID-19 dataset up to date with 2951 COVID-19 CXR images, where the annotation of the ground-truth segmentation masks is performed on CXRs by a novel collaborative expert human-machine approach. Furthermore, we publicly release the first CXR dataset with the ground-truth segmentation masks of the COVID-19 infected regions. A detailed set of experiments show that state-of-the-art segmentation networks can learn to localize COVID-19 infection with an F1-score of 85.81%, that is significantly superior to the activation maps created by the previous methods. Finally, the proposed approach achieved a COVID-19 detection performance with 98.37% sensitivity and 99.16% specificity.