 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavefront Coding for Accommodation-Invariant Near-Eye Displays
Oct 14, 2025



We present a new computational near-eye display method that addresses the vergence-accommodation conflict problem in stereoscopic displays through accommodation-invariance. Our system integrates a refractive lens eyepiece with a novel wavefront coding diffractive optical element, operating in tandem with a pre-processing convolutional neural network. We employ end-to-end learning to jointly optimize the wavefront-coding optics and the image pre-processing module. To implement this approach, we develop a differentiable retinal image formation model that accounts for limiting aperture and chromatic aberrations introduced by the eye optics. We further integrate the neural transfer function and the contrast sensitivity function into the loss model to account for related perceptual effects. To tackle off-axis distortions, we incorporate position dependency into the pre-processing module. In addition to conducting rigorous analysis based on simulations, we also fabricate the designed diffractive optical element and build a benchtop setup, demonstrating accommodation-invariance for depth ranges of up to four diopters.
WAVE-UNET: Wavelength based Image Reconstruction method using attention UNET for OCT images
Oct 05, 2024In this work, we propose to leverage a deep-learning (DL) based reconstruction framework for high quality Swept-Source Optical Coherence Tomography (SS-OCT) images, by incorporating wavelength ({\lambda}) space interferometric fringes. Generally, the SS-OCT captured fringe is linear in wavelength space and if Inverse Discrete Fourier Transform (IDFT) is applied to extract depth-resolved spectral information, the resultant images are blurred due to the broadened Point Spread Function (PSF). Thus, the recorded wavelength space fringe is to be scaled to uniform grid in wavenumber (k) space using k-linearization and calibration involving interpolations which may result in loss of information along with increased system complexity. Another challenge in OCT is the speckle noise, inherent in the low coherence interferometry-based systems. Hence, we propose a systematic design methodology WAVE-UNET to reconstruct the high-quality OCT images directly from the {\lambda}-space to reduce the complexity. The novel design paradigm surpasses the linearization procedures and uses DL to enhance the realism and quality of raw {\lambda}-space scans. This framework uses modified UNET having attention gating and residual connections, with IDFT processed {\lambda}-space fringes as the input. The method consistently outperforms the traditional OCT system by generating good-quality B-scans with highly reduced time-complexity.
Optical modelling of accommodative light field display system and prediction of human eye responses
Apr 02, 2022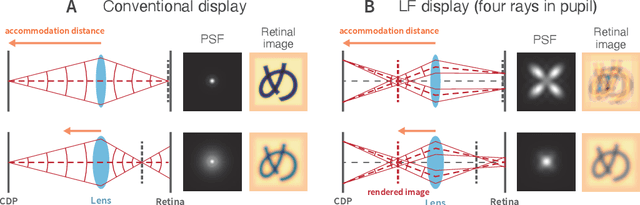
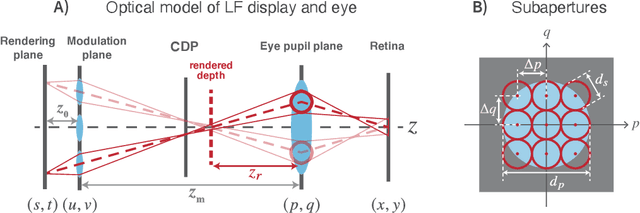

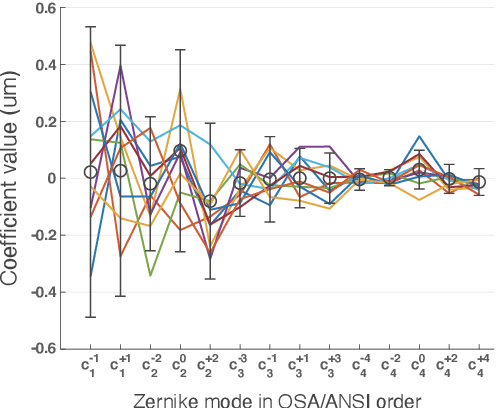
The spatio-angular resolution of a light field (LF) display is a crucial factor for delivering adequate spatial image quality and eliciting an accommodation response. Previous studies have modelled retinal image formation with an LF display and evaluated whether accommodation would be evoked correctly. The models were mostly based on ray-tracing and a schematic eye model, which pose computational complexity and inaccurately represent the human eye population's behaviour. We propose an efficient wave-optics-based framework to model the human eye and a general LF display. With the model, we simulated the retinal point spread function (PSF) of a point rendered by an LF display at various depths to characterise the retinal image quality. Additionally, accommodation responses to rendered LF images were estimated by computing the visual Strehl ratio based on the optical transfer function (VSOTF) from the PSFs. We assumed an ideal LF display that had an infinite spatial resolution and was free from optical aberrations in the simulation. We tested images rendered at 0--4 dioptres of depths having angular resolutions of up to 4x4 viewpoints within a pupil. The simulation predicted small and constant accommodation errors, which contradict the findings of previous studies. An evaluation of the optical resolution of the rendered retinal image suggested a trade-off between the maximum resolution achievable and the depth range of a rendered image where in-focus resolution is kept high. The proposed framework can be used to evaluate the upper bound of the optical performance of an LF display for realistically aberrated eyes, which may help to find an optimal spatio-angular resolution required to render a high quality 3D scene.
Generalized Tensor Summation Compressive Sensing Network (GTSNET): An Easy to Learn Compressive Sensing Operation
Aug 04, 2021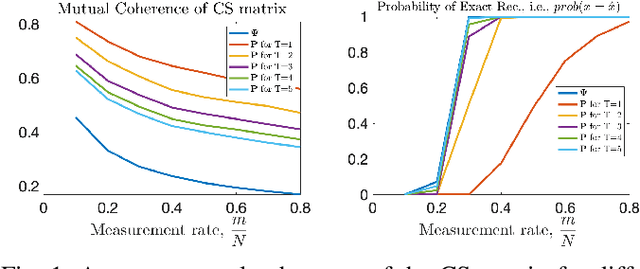


In CS literature, the efforts can be divided into two groups: finding a measurement matrix that preserves the compressed information at the maximum level, and finding a reconstruction algorithm for the compressed information. In the traditional CS setup, the measurement matrices are selected as random matrices, and optimization-based iterative solutions are used to recover the signals. However, when we handle large signals, using random matrices become cumbersome especially when it comes to iterative optimization-based solutions. Even though recent deep learning-based solutions boost the reconstruction accuracy performance while speeding up the recovery, still jointly learning the whole measurement matrix is a difficult process. In this work, we introduce a separable multi-linear learning of the CS matrix by representing it as the summation of arbitrary number of tensors. For a special case where the CS operation is set as a single tensor multiplication, the model is reduced to the learning-based separable CS; while a dense CS matrix can be approximated and learned as the summation of multiple tensors. Both cases can be used in CS of two or multi-dimensional signals e.g., images, multi-spectral images, videos, etc. Structural CS matrices can also be easily approximated and learned in our multi-linear separable learning setup with structural tensor sum representation. Hence, our learnable generalized tensor summation CS operation encapsulates most CS setups including separable CS, non-separable CS (traditional vector-matrix multiplication), structural CS, and CS of the multi-dimensional signals. For both gray-scale and RGB images, the proposed scheme surpasses most state-of-the-art solutions, especially in lower measurement rates. Although the performance gain remains limited from tensor to the sum of tensor representation for gray-scale images, it becomes significant in the RGB case.
Learning Wavefront Coding for Extended Depth of Field Imaging
Dec 31, 2019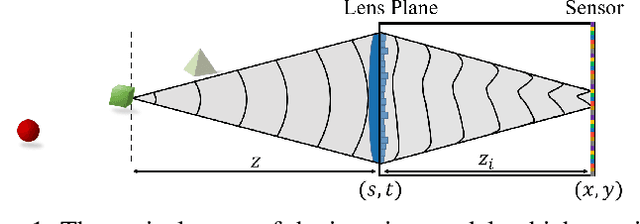

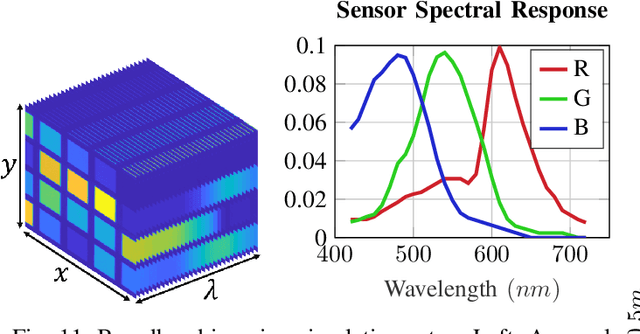

The depth of field constitutes an important quality factor of imaging systems that highly affects the content of the acquired spatial information in the captured images. Extended depth of field (EDoF) imaging is a challenging problem due to its highly ill-posed nature, hence it has been extensively addressed in the literature. We propose a computational imaging approach for EDoF, where we employ wavefront coding via a diffractive optical element (DOE) and we achieve deblurring through a convolutional neural network. Thanks to the end-to-end differentiable modeling of optical image formation and computational post-processing, we jointly optimize the optical design, i.e., DOE, and the deblurring through standard gradient descent methods. Based on the properties of the underlying refractive lens and the desired EDoF range, we provide an analytical expression for the search space of the DOE, which helps in the convergence of the end-to-end network. We achieve superior EDoF imaging performance compared to state of the art, where we demonstrate results with minimal artifacts in various scenarios, including deep 3D scenes and broadband imaging.