 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMscope: a snapshot Hyperspectral Autofluorescence Miniscope for real-time molecular imaging
Nov 12, 2025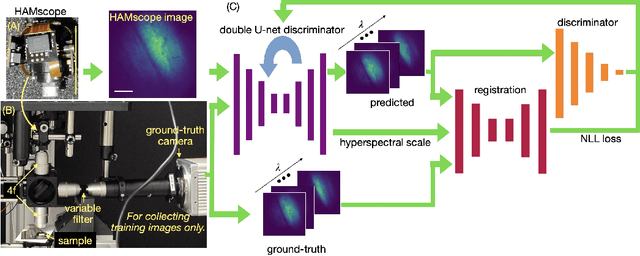
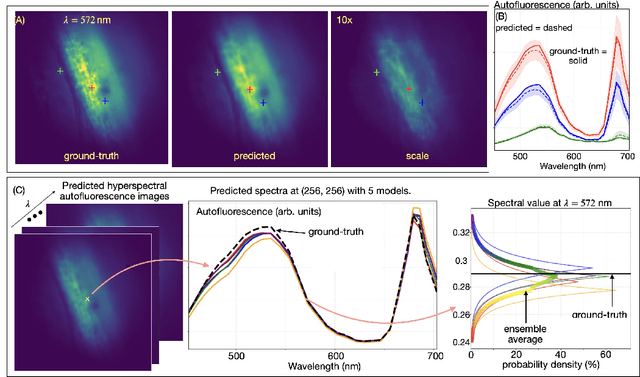
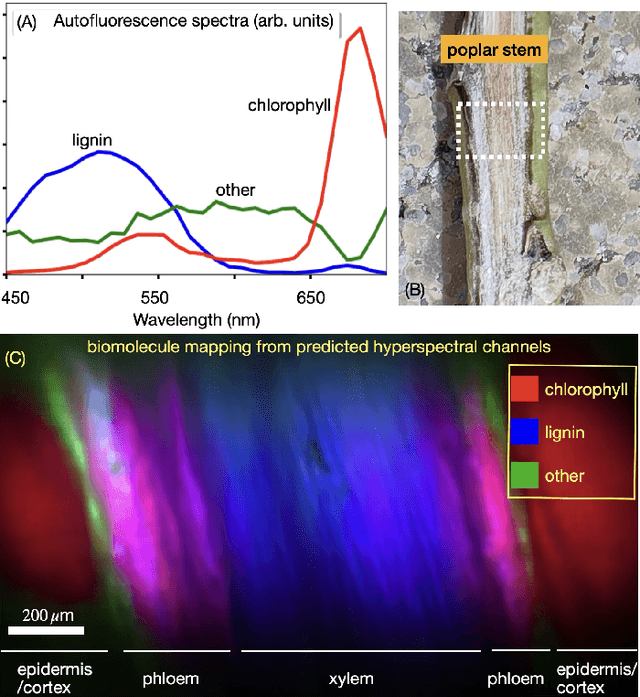
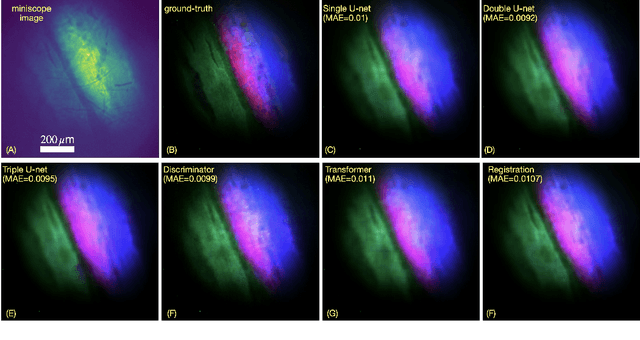
We introduce HAMscope, a compact, snapshot hyperspectral autofluorescence miniscope that enables real-time, label-free molecular imaging in a wide range of biological systems. By integrating a thin polymer diffuser into a widefield miniscope, HAMscope spectrally encodes each frame and employs a probabilistic deep learning framework to reconstruct 30-channel hyperspectral stacks (452 to 703 nm) or directly infer molecular composition maps from single images. A scalable multi-pass U-Net architecture with transformer-based attention and per-pixel uncertainty estimation enables high spatio-spectral fidelity (mean absolute error ~ 0.0048) at video rates. While initially demonstrated in plant systems, including lignin, chlorophyll, and suberin imaging in intact poplar and cork tissues, the platform is readily adaptable to other applications such as neural activity mapping, metabolic profiling, and histopathology. We show that the system generalizes to out-of-distribution tissue types and supports direct molecular mapping without the need for spectral unmixing. HAMscope establishes a general framework for compact, uncertainty-aware spectral imaging that combines minimal optics with advanced deep learning, offering broad utility for real-time biochemical imaging across neuroscience, environmental monitoring, and biomedicine.
Wavefront Coding for Accommodation-Invariant Near-Eye Displays
Oct 14, 2025



We present a new computational near-eye display method that addresses the vergence-accommodation conflict problem in stereoscopic displays through accommodation-invariance. Our system integrates a refractive lens eyepiece with a novel wavefront coding diffractive optical element, operating in tandem with a pre-processing convolutional neural network. We employ end-to-end learning to jointly optimize the wavefront-coding optics and the image pre-processing module. To implement this approach, we develop a differentiable retinal image formation model that accounts for limiting aperture and chromatic aberrations introduced by the eye optics. We further integrate the neural transfer function and the contrast sensitivity function into the loss model to account for related perceptual effects. To tackle off-axis distortions, we incorporate position dependency into the pre-processing module. In addition to conducting rigorous analysis based on simulations, we also fabricate the designed diffractive optical element and build a benchtop setup, demonstrating accommodation-invariance for depth ranges of up to four diopters.
HD snapshot diffractive spectral imaging and inferencing
Jun 25, 2024



We present a novel high-definition (HD) snapshot diffractive spectral imaging system utilizing a diffractive filter array (DFA) to capture a single image that encodes both spatial and spectral information. This single diffractogram can be computationally reconstructed into a spectral image cube, providing a high-resolution representation of the scene across 25 spectral channels in the 440-800 nm range at 1304x744 spatial pixels (~1 MP). This unique approach offers numerous advantages including snapshot capture, a form of optical compression, flexible offline reconstruction, the ability to select the spectral basis after capture, and high light throughput due to the absence of lossy filters. We demonstrate a 30-50 nm spectral resolution and compared our reconstructed spectra against ground truth obtained by conventional spectrometers. Proof-of-concept experiments in diverse applications including biological tissue classification, food quality assessment, and simulated stellar photometry validate our system's capability to perform robust and accurate inference. These results establish the DFA-based imaging system as a versatile and powerful tool for advancing scientific and industrial imaging applications.
STEREOFOG -- Computational DeFogging via Image-to-Image Translation on a real-world Dataset
Dec 04, 2023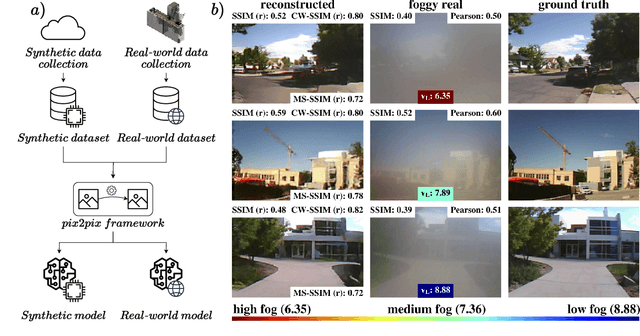

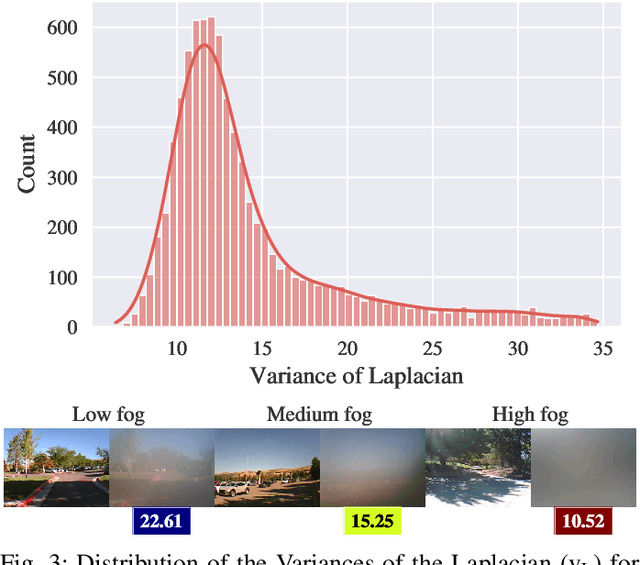

Image-to-Image translation (I2I) is a subtype of Machine Learning (ML) that has tremendous potential in applications where two domains of images and the need for translation between the two exist, such as the removal of fog. For example, this could be useful for autonomous vehicles, which currently struggle with adverse weather conditions like fog. However, datasets for I2I tasks are not abundant and typically hard to acquire. Here, we introduce STEREOFOG, a dataset comprised of $10,067$ paired fogged and clear images, captured using a custom-built device, with the purpose of exploring I2I's potential in this domain. It is the only real-world dataset of this kind to the best of our knowledge. Furthermore, we apply and optimize the pix2pix I2I ML framework to this dataset. With the final model achieving an average Complex Wavelet-Structural Similarity (CW-SSIM) score of $0.76$, we prove the technique's suitability for the problem.
Machine Learning enables Ultra-Compact Integrated Photonics through Silicon-Nanopattern Digital Metamaterials
Nov 27, 2020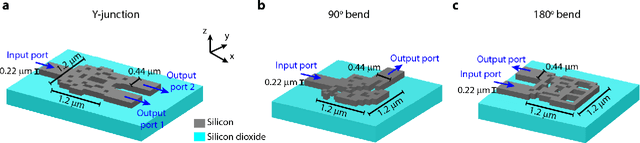
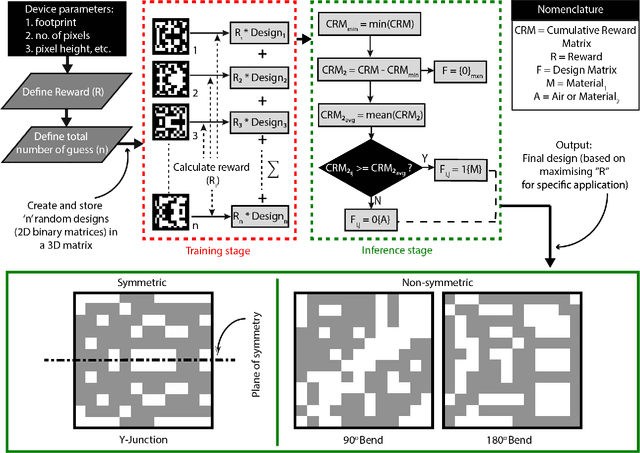
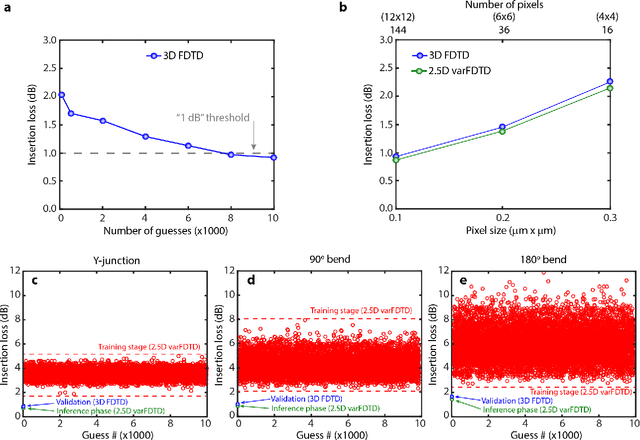
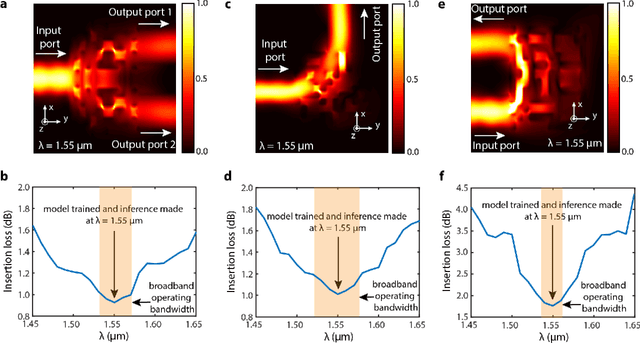
In this work, we demonstrate three ultra-compact integrated-photonics devices, which are designed via a machine-learning algorithm coupled with finite-difference time-domain (FDTD) modeling. Through digitizing the design domain into "binary pixels" these digital metamaterials are readily manufacturable as well. By showing a variety of devices (beamsplitters and waveguide bends), we showcase the generality of our approach. With an area footprint smaller than ${\lambda_0}^2$, our designs are amongst the smallest reported to-date. Our method combines machine learning with digital metamaterials to enable ultra-compact, manufacturable devices, which could power a new "Photonics Moore's Law."
A needle-based deep-neural-network camera
Nov 14, 2020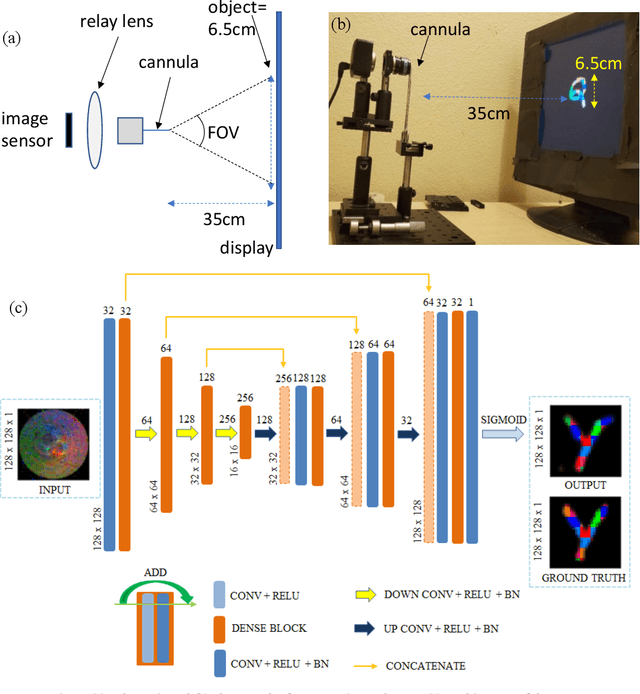

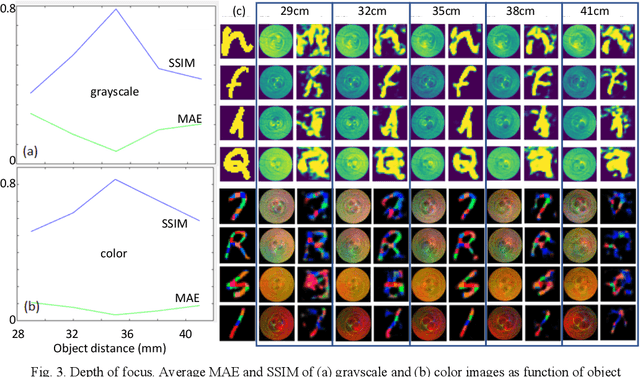
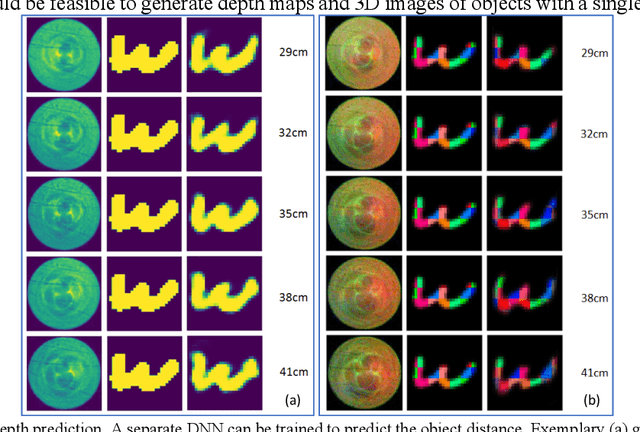
We experimentally demonstrate a camera whose primary optic is a cannula (diameter=0.22mm and length=12.5mm) that acts a lightpipe transporting light intensity from an object plane (35cm away) to its opposite end. Deep neural networks (DNNs) are used to reconstruct color and grayscale images with field of view of 180 and angular resolution of ~0.40. When trained on images with depth information, the DNN can create depth maps. Finally, we show DNN-based classification of the EMNIST dataset without and with image reconstructions. The former could be useful for imaging with enhanced privacy.
Classification of optics-free images with deep neural networks
Nov 10, 2020
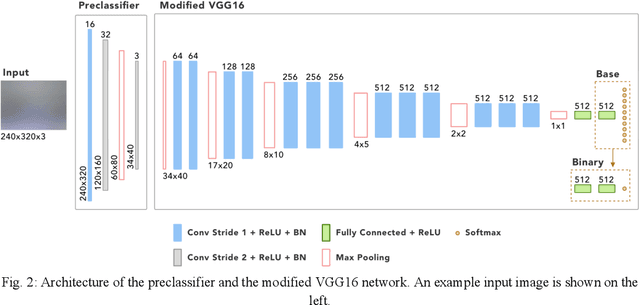
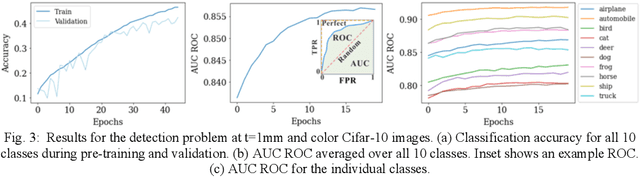
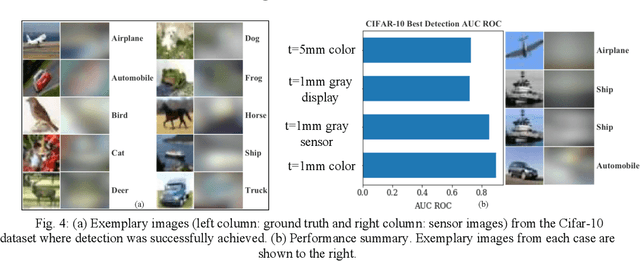
The thinnest possible camera is achieved by removing all optics, leaving only the image sensor. We train deep neural networks to perform multi-class detection and binary classification (with accuracy of 92%) on optics-free images without the need for anthropocentric image reconstructions. Inferencing from optics-free images has the potential for enhanced privacy and power efficiency.
Lensless-camera based machine learning for image classification
Sep 03, 2017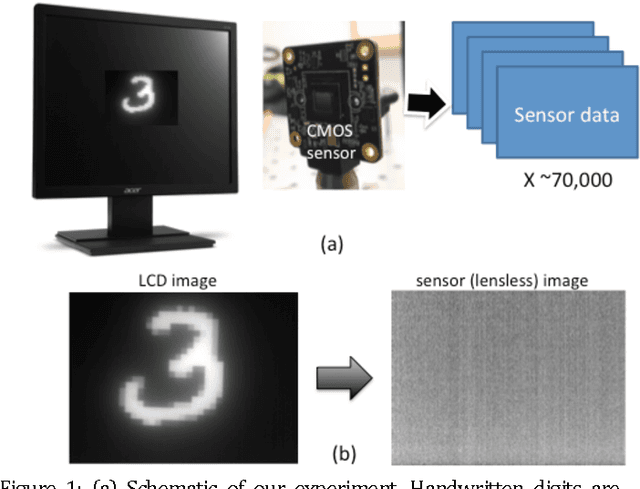
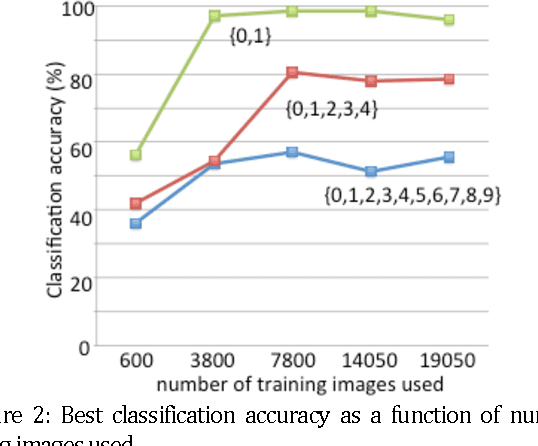
Machine learning (ML) has been widely applied to image classification. Here, we extend this application to data generated by a camera comprised of only a standard CMOS image sensor with no lens. We first created a database of lensless images of handwritten digits. Then, we trained a ML algorithm on this dataset. Finally, we demonstrated that the trained ML algorithm is able to classify the digits with accuracy as high as 99% for 2 digits. Our approach clearly demonstrates the potential for non-human cameras in machine-based decision-making scenarios.
Lensless Photography with only an image sensor
Feb 21, 2017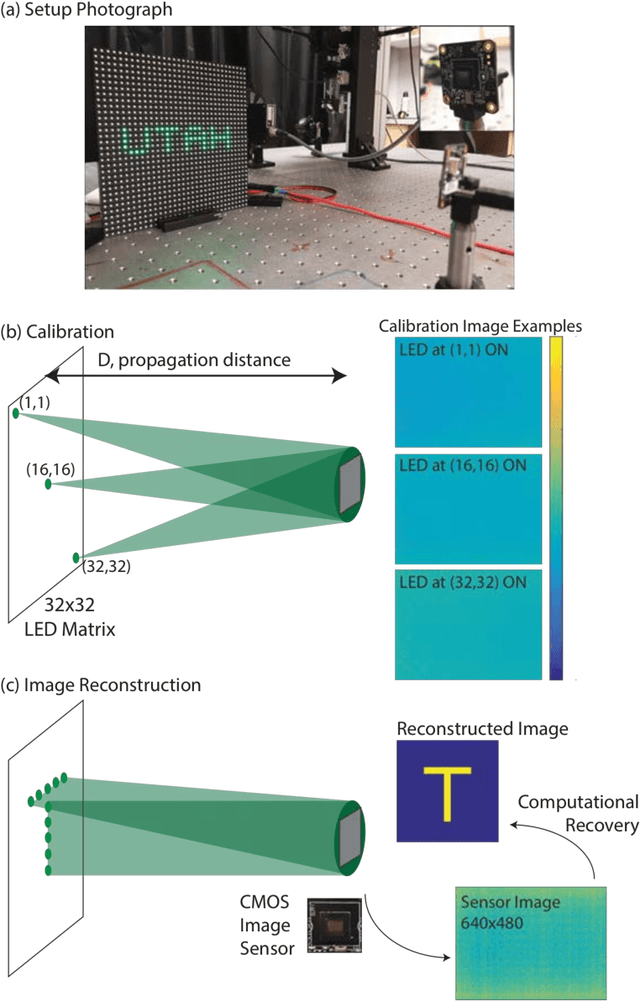
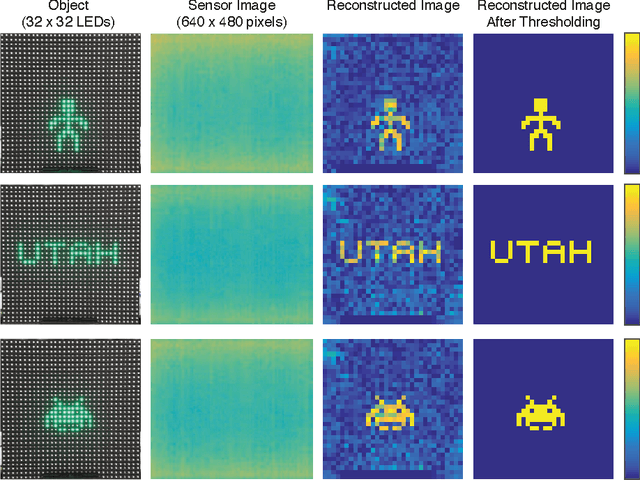
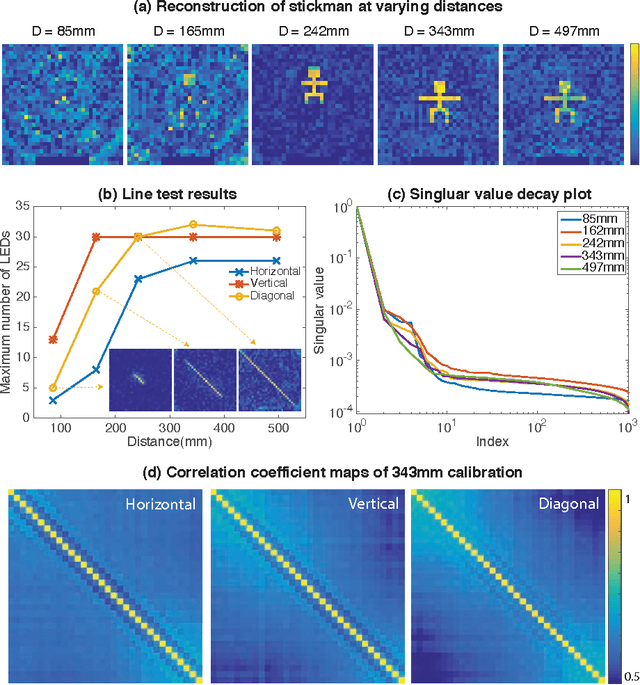
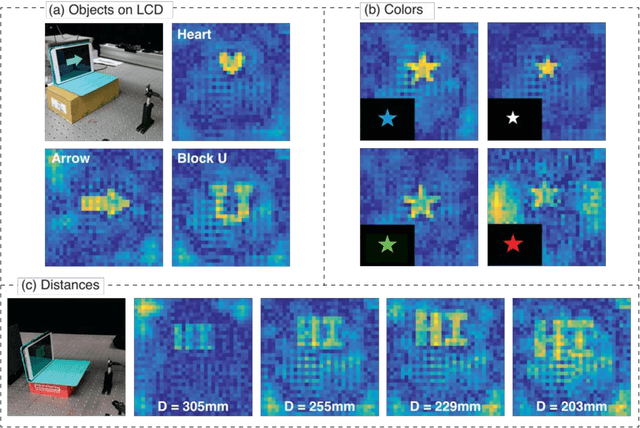
Photography usually requires optics in conjunction with a recording device (an image sensor). Eliminating the optics could lead to new form factors for cameras. Here, we report a simple demonstration of imaging using a bare CMOS sensor that utilizes computation. The technique relies on the space variant point-spread functions resulting from the interaction of a point source in the field of view with the image sensor. These space-variant point-spread functions are combined with a reconstruction algorithm in order to image simple objects displayed on a discrete LED array as well as on an LCD screen. We extended the approach to video imaging at the native frame rate of the sensor. Finally, we performed experiments to analyze the parametric impact of the object distance. Improving the sensor designs and reconstruction algorithms can lead to useful cameras without optics.