 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNet-34 with Lightweight Decoder for Accurate and Efficient Segmentation of Fetal Brain MRI
May 31, 2026Accurate segmentation of fetal brain tissues in Magnetic Resonance Imaging (MRI) is critical for early diagnosis of congenital abnormalities and improving prenatal care. However, the task remains difficult because of fetal motion, low tissue contrast, and major anatomical variability throughout gestational ages, particularly in segmenting complex structures such as white matter, gray matter, lateral ventricles, deep gray matter, extra-cerebrospinal fluid, cerebellum, and brainstem. As a solution to these difficulties, this research introduces a novel deep learning model that combines a ResNet-34 encoder with a lightweight decoder leveraging multi-layer perceptron (MLP) modules for adaptive feature refinement. This design specifically enhances the model's ability to preserve anatomical boundaries and mitigate segmentation errors caused by motion artifacts and intensity inhomogeneities. Computational efficiency is achieved by reducing parameter count, employing bilinear upsampling instead of transposed convolutions, and optimizing the decoder for speed without sacrificing accuracy. Trained and validated on the FeTA 2021 dataset using 5-fold cross-validation, the proposed model outperforms baseline architectures such as UNet, UNet++, DeepLabV3, and DeepLabV3+, achieving an average Accuracy of 97.37% with a mean Dice Similarity Coefficient (DSC) of 90.33%, mean Intersection over Union (IoU) of 86.93%, and Precision of 90.83%. Additionally, its fast inference time and reduced computational load make it well-suited for integration into real-time clinical workflows.
Attention-Guided Dual-Stream Learning for Group Engagement Recognition: Fusing Transformer-Encoded Motion Dynamics with Scene Context via Adaptive Gating
Apr 11, 2026Student engagement is crucial for improving learning outcomes in group activities. Highly engaged students perform better both individually and contribute to overall group success. However, most existing automated engagement recognition methods are designed for online classrooms or estimate engagement at the individual level. Addressing this gap, we propose DualEngage, a novel two-stream framework for group-level engagement recognition from in-classroom videos. It models engagement as a joint function of both individual and group-level behaviors. The primary stream models person-level motion dynamics by detecting and tracking students, extracting dense optical flow with the Recurrent All-Pairs Field Transforms network, encoding temporal motion patterns using a transformer encoder, and finally aggregating per-student representations through attention pooling into a unified representation. The secondary stream captures scene-level spatiotemporal information from the full video clip, leveraging a pretrained three-dimensional Residual Network. The two-stream representations are combined via softmax-gated fusion, which dynamically weights each stream's contribution based on the joint context of both features. DualEngage learns a joint representation of individual actions with overarching group dynamics. We evaluate the proposed approach using fivefold cross-validation on the Classroom Group Engagement Dataset developed by Ocean University of China, achieving an average classification accuracy of 0.9621+/-0.0161 with a macro-averaged F1 of 0.9530+/-0.0204. To understand the contribution of each branch, we further conduct an ablation study comparing single-stream variants against the two-stream model. This work is among the first in classroom engagement recognition to adopt a dual-stream design that explicitly leverages motion cues as an estimator.
Alignment-Aware and Reliability-Gated Multimodal Fusion for Unmanned Aerial Vehicle Detection Across Heterogeneous Thermal-Visual Sensors
Mar 09, 2026Reliable unmanned aerial vehicle (UAV) detection is critical for autonomous airspace monitoring but remains challenging when integrating sensor streams that differ substantially in resolution, perspective, and field of view. Conventional fusion methods-such as wavelet-, Laplacian-, and decision-level approaches-often fail to preserve spatial correspondence across modalities and suffer from annotation of inconsistencies, limiting their robustness in real-world settings. This study introduces two fusion strategies, Registration-aware Guided Image Fusion (RGIF) and Reliability-Gated Modality-Attention Fusion (RGMAF), designed to overcome these limitations. RGIF employs Enhanced Correlation Coefficient (ECC)-based affine registration combined with guided filtering to maintain thermal saliency while enhancing structural detail. RGMAF integrates affine and optical-flow registration with a reliability-weighted attention mechanism that adaptively balances thermal contrast and visual sharpness. Experiments were conducted on the Multi-Sensor and Multi-View Fixed-Wing (MMFW)-UAV dataset comprising 147,417 annotated air-to-air frames collected from infrared, wide-angle, and zoom sensors. Among single-modality detectors, YOLOv10x demonstrated the most stable cross-domain performance and was selected as the detection backbone for evaluating fused imagery. RGIF improved the visual baseline by 2.13% mAP@50 (achieving 97.65%), while RGMAF attained the highest recall of 98.64%. These findings show that registration-aware and reliability-adaptive fusion provides a robust framework for integrating heterogeneous modalities, substantially enhancing UAV detection performance in multimodal environments.
Tracing 3D Anatomy in 2D Strokes: A Multi-Stage Projection Driven Approach to Cervical Spine Fracture Identification
Jan 21, 2026Cervical spine fractures are critical medical conditions requiring precise and efficient detection for effective clinical management. This study explores the viability of 2D projection-based vertebra segmentation for vertebra-level fracture detection in 3D CT volumes, presenting an end-to-end pipeline for automated analysis of cervical vertebrae (C1-C7). By approximating a 3D volume through optimized 2D axial, sagittal, and coronal projections, regions of interest are identified using the YOLOv8 model from all views and combined to approximate the 3D cervical spine area, achieving a 3D mIoU of 94.45 percent. This projection-based localization strategy reduces computational complexity compared to traditional 3D segmentation methods while maintaining high performance. It is followed by a DenseNet121-Unet-based multi-label segmentation leveraging variance- and energy-based projections, achieving a Dice score of 87.86 percent. Strategic approximation of 3D vertebral masks from these 2D segmentation masks enables the extraction of individual vertebra volumes. The volumes are analyzed for fractures using an ensemble of 2.5D Spatio-Sequential models incorporating both raw slices and projections per vertebra for complementary evaluation. This ensemble achieves vertebra-level and patient-level F1 scores of 68.15 and 82.26, and ROC-AUC scores of 91.62 and 83.04, respectively. We further validate our approach through an explainability study that provides saliency map visualizations highlighting anatomical regions relevant for diagnosis, and an interobserver variability analysis comparing our model's performance with expert radiologists, demonstrating competitive results.
CASR-Net: An Image Processing-focused Deep Learning-based Coronary Artery Segmentation and Refinement Network for X-ray Coronary Angiogram
Oct 31, 2025Early detection of coronary artery disease (CAD) is critical for reducing mortality and improving patient treatment planning. While angiographic image analysis from X-rays is a common and cost-effective method for identifying cardiac abnormalities, including stenotic coronary arteries, poor image quality can significantly impede clinical diagnosis. We present the Coronary Artery Segmentation and Refinement Network (CASR-Net), a three-stage pipeline comprising image preprocessing, segmentation, and refinement. A novel multichannel preprocessing strategy combining CLAHE and an improved Ben Graham method provides incremental gains, increasing Dice Score Coefficient (DSC) by 0.31-0.89% and Intersection over Union (IoU) by 0.40-1.16% compared with using the techniques individually. The core innovation is a segmentation network built on a UNet with a DenseNet121 encoder and a Self-organized Operational Neural Network (Self-ONN) based decoder, which preserves the continuity of narrow and stenotic vessel branches. A final contour refinement module further suppresses false positives. Evaluated with 5-fold cross-validation on a combination of two public datasets that contain both healthy and stenotic arteries, CASR-Net outperformed several state-of-the-art models, achieving an IoU of 61.43%, a DSC of 76.10%, and clDice of 79.36%. These results highlight a robust approach to automated coronary artery segmentation, offering a valuable tool to support clinicians in diagnosis and treatment planning.
GastroViT: A Vision Transformer Based Ensemble Learning Approach for Gastrointestinal Disease Classification with Grad CAM & SHAP Visualization
Sep 30, 2025The gastrointestinal (GI) tract of humans can have a wide variety of aberrant mucosal abnormality findings, ranging from mild irritations to extremely fatal illnesses. Prompt identification of gastrointestinal disorders greatly contributes to arresting the progression of the illness and improving therapeutic outcomes. This paper presents an ensemble of pre-trained vision transformers (ViTs) for accurately classifying endoscopic images of the GI tract to categorize gastrointestinal problems and illnesses. ViTs, attention-based neural networks, have revolutionized image recognition by leveraging the transformative power of the transformer architecture, achieving state-of-the-art (SOTA) performance across various visual tasks. The proposed model was evaluated on the publicly available HyperKvasir dataset with 10,662 images of 23 different GI diseases for the purpose of identifying GI tract diseases. An ensemble method is proposed utilizing the predictions of two pre-trained models, MobileViT_XS and MobileViT_V2_200, which achieved accuracies of 90.57% and 90.48%, respectively. All the individual models are outperformed by the ensemble model, GastroViT, with an average precision, recall, F1 score, and accuracy of 69%, 63%, 64%, and 91.98%, respectively, in the first testing that involves 23 classes. The model comprises only 20 million (M) parameters, even without data augmentation and despite the highly imbalanced dataset. For the second testing with 16 classes, the scores are even higher, with average precision, recall, F1 score, and accuracy of 87%, 86%, 87%, and 92.70%, respectively. Additionally, the incorporation of explainable AI (XAI) methods such as Grad-CAM (Gradient Weighted Class Activation Mapping) and SHAP (Shapley Additive Explanations) enhances model interpretability, providing valuable insights for reliable GI diagnosis in real-world settings.
Deep Learning in Automated Power Line Inspection: A Review
Feb 10, 2025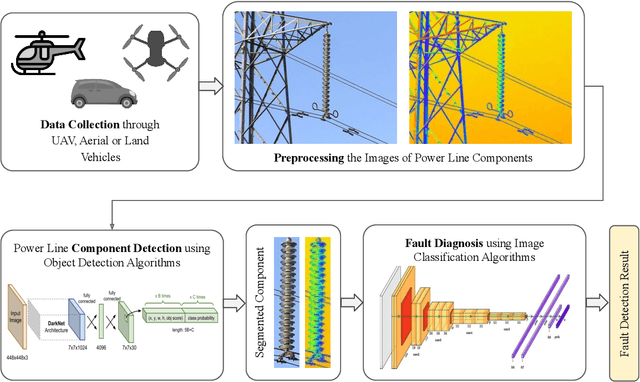



In recent years, power line maintenance has seen a paradigm shift by moving towards computer vision-powered automated inspection. The utilization of an extensive collection of videos and images has become essential for maintaining the reliability, safety, and sustainability of electricity transmission. A significant focus on applying deep learning techniques for enhancing power line inspection processes has been observed in recent research. A comprehensive review of existing studies has been conducted in this paper, to aid researchers and industries in developing improved deep learning-based systems for analyzing power line data. The conventional steps of data analysis in power line inspections have been examined, and the body of current research has been systematically categorized into two main areas: the detection of components and the diagnosis of faults. A detailed summary of the diverse methods and techniques employed in these areas has been encapsulated, providing insights into their functionality and use cases. Special attention has been given to the exploration of deep learning-based methodologies for the analysis of power line inspection data, with an exposition of their fundamental principles and practical applications. Moreover, a vision for future research directions has been outlined, highlighting the need for advancements such as edge-cloud collaboration, and multi-modal analysis among others. Thus, this paper serves as a comprehensive resource for researchers delving into deep learning for power line analysis, illuminating the extent of current knowledge and the potential areas for future investigation.
Self-CephaloNet: A Two-stage Novel Framework using Operational Neural Network for Cephalometric Analysis
Jan 19, 2025Cephalometric analysis is essential for the diagnosis and treatment planning of orthodontics. In lateral cephalograms, however, the manual detection of anatomical landmarks is a time-consuming procedure. Deep learning solutions hold the potential to address the time constraints associated with certain tasks; however, concerns regarding their performance have been observed. To address this critical issue, we proposed an end-to-end cascaded deep learning framework (Self-CepahloNet) for the task, which demonstrated benchmark performance over the ISBI 2015 dataset in predicting 19 dental landmarks. Due to their adaptive nodal capabilities, Self-ONN (self-operational neural networks) demonstrate superior learning performance for complex feature spaces over conventional convolutional neural networks. To leverage this attribute, we introduced a novel self-bottleneck in the HRNetV2 (High Resolution Network) backbone, which has exhibited benchmark performance on the ISBI 2015 dataset for the dental landmark detection task. Our first-stage results surpassed previous studies, showcasing the efficacy of our singular end-to-end deep learning model, which achieved a remarkable 70.95% success rate in detecting cephalometric landmarks within a 2mm range for the Test1 and Test2 datasets. Moreover, the second stage significantly improved overall performance, yielding an impressive 82.25% average success rate for the datasets above within the same 2mm distance. Furthermore, external validation was conducted using the PKU cephalogram dataset. Our model demonstrated a commendable success rate of 75.95% within the 2mm range.
Deep Learning-Driven Segmentation of Ischemic Stroke Lesions Using Multi-Channel MRI
Jan 04, 2025



Ischemic stroke, caused by cerebral vessel occlusion, presents substantial challenges in medical imaging due to the variability and subtlety of stroke lesions. Magnetic Resonance Imaging (MRI) plays a crucial role in diagnosing and managing ischemic stroke, yet existing segmentation techniques often fail to accurately delineate lesions. This study introduces a novel deep learning-based method for segmenting ischemic stroke lesions using multi-channel MRI modalities, including Diffusion Weighted Imaging (DWI), Apparent Diffusion Coefficient (ADC), and enhanced Diffusion Weighted Imaging (eDWI). The proposed architecture integrates DenseNet121 as the encoder with Self-Organized Operational Neural Networks (SelfONN) in the decoder, enhanced by Channel and Space Compound Attention (CSCA) and Double Squeeze-and-Excitation (DSE) blocks. Additionally, a custom loss function combining Dice Loss and Jaccard Loss with weighted averages is introduced to improve model performance. Trained and evaluated on the ISLES 2022 dataset, the model achieved Dice Similarity Coefficients (DSC) of 83.88% using DWI alone, 85.86% with DWI and ADC, and 87.49% with the integration of DWI, ADC, and eDWI. This approach not only outperforms existing methods but also addresses key limitations in current segmentation practices. These advancements significantly enhance diagnostic precision and treatment planning for ischemic stroke, providing valuable support for clinical decision-making.
Ensemble Machine Learning Model for Inner Speech Recognition: A Subject-Specific Investigation
Dec 09, 2024



Inner speech recognition has gained enormous interest in recent years due to its applications in rehabilitation, developing assistive technology, and cognitive assessment. However, since language and speech productions are a complex process, for which identifying speech components has remained a challenging task. Different approaches were taken previously to reach this goal, but new approaches remain to be explored. Also, a subject-oriented analysis is necessary to understand the underlying brain dynamics during inner speech production, which can bring novel methods to neurological research. A publicly available dataset, Thinking Out Loud Dataset, has been used to develop a Machine Learning (ML)-based technique to classify inner speech using 128-channel surface EEG signals. The dataset is collected on a Spanish cohort of ten subjects while uttering four words (Arriba, Abajo, Derecha, and Izquierda) by each participant. Statistical methods were employed to detect and remove motion artifacts from the Electroencephalography (EEG) signals. A large number (191 per channel) of time-, frequency- and time-frequency-domain features were extracted. Eight feature selection algorithms are explored, and the best feature selection technique is selected for subsequent evaluations. The performance of six ML algorithms is evaluated, and an ensemble model is proposed. Deep Learning (DL) models are also explored, and the results are compared with the classical ML approach. The proposed ensemble model, by stacking the five best logistic regression models, generated an overall accuracy of 81.13% and an F1 score of 81.12% in the classification of four inner speech words using surface EEG signals. The proposed framework with the proposed ensemble of classical ML models shows promise in the classification of inner speech using surface EEG signals.