 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in Signal Processing Education: An Audio Foundation Model Based Approach
Feb 01, 2026Audio Foundation Models (AFMs), a specialized category of Generative AI (GenAI), have the potential to transform signal processing (SP) education by integrating core applications such as speech and audio enhancement, denoising, source separation, feature extraction, automatic classification, and real-time signal analysis into learning and research. This paper introduces SPEduAFM, a conceptual AFM tailored for SP education, bridging traditional SP principles with GenAI-driven innovations. Through an envisioned case study, we outline how AFMs can enable a range of applications, including automated lecture transcription, interactive demonstrations, and inclusive learning tools, showcasing their potential to transform abstract concepts into engaging, practical experiences. This paper also addresses challenges such as ethics, explainability, and customization by highlighting dynamic, real-time auditory interactions that foster experiential and authentic learning. By presenting SPEduAFM as a forward-looking vision, we aim to inspire broader adoption of GenAI in engineering education, enhancing accessibility, engagement, and innovation in the classroom and beyond.
Machine-agnostic Automated Lumbar MRI Segmentation using a Cascaded Model Based on Generative Neurons
Nov 23, 2024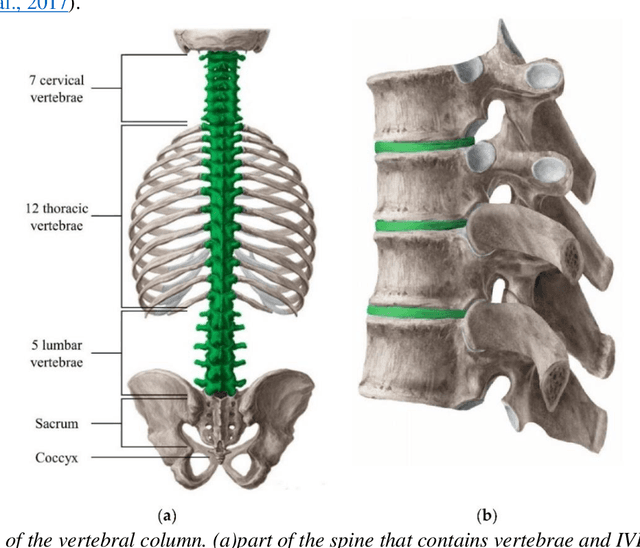

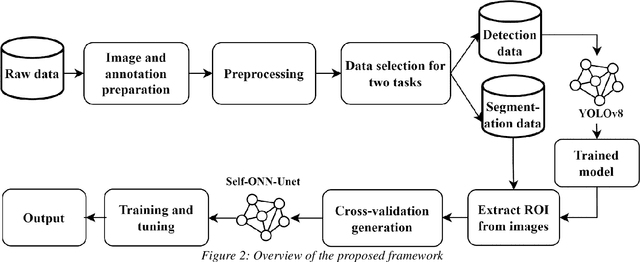
Automated lumbar spine segmentation is very crucial for modern diagnosis systems. In this study, we introduce a novel machine-agnostic approach for segmenting lumbar vertebrae and intervertebral discs from MRI images, employing a cascaded model that synergizes an ROI detection and a Self-organized Operational Neural Network (Self-ONN)-based encoder-decoder network for segmentation. Addressing the challenge of diverse MRI modalities, our methodology capitalizes on a unique dataset comprising images from 12 scanners and 34 subjects, enhanced through strategic preprocessing and data augmentation techniques. The YOLOv8 medium model excels in ROI extraction, achieving an excellent performance of 0.916 mAP score. Significantly, our Self-ONN-based model, combined with a DenseNet121 encoder, demonstrates excellent performance in lumbar vertebrae and IVD segmentation with a mean Intersection over Union (IoU) of 83.66%, a sensitivity of 91.44%, and Dice Similarity Coefficient (DSC) of 91.03%, as validated through rigorous 10-fold cross-validation. This study not only showcases an effective approach to MRI segmentation in spine-related disorders but also sets the stage for future advancements in automated diagnostic tools, emphasizing the need for further dataset expansion and model refinement for broader clinical applicability.
Exploiting Consistency-Preserving Loss and Perceptual Contrast Stretching to Boost SSL-based Speech Enhancement
Aug 08, 2024Self-supervised representation learning (SSL) has attained SOTA results on several downstream speech tasks, but SSL-based speech enhancement (SE) solutions still lag behind. To address this issue, we exploit three main ideas: (i) Transformer-based masking generation, (ii) consistency-preserving loss, and (iii) perceptual contrast stretching (PCS). In detail, conformer layers, leveraging an attention mechanism, are introduced to effectively model frame-level representations and obtain the Ideal Ratio Mask (IRM) for SE. Moreover, we incorporate consistency in the loss function, which processes the input to account for the inconsistency effects of signal reconstruction from the spectrogram. Finally, PCS is employed to improve the contrast of input and target features according to perceptual importance. Evaluated on the VoiceBank-DEMAND task, the proposed solution outperforms previously SSL-based SE solutions when tested on several objective metrics, attaining a SOTA PESQ score of 3.54.
Single channel speech enhancement by colored spectrograms
Oct 26, 2023

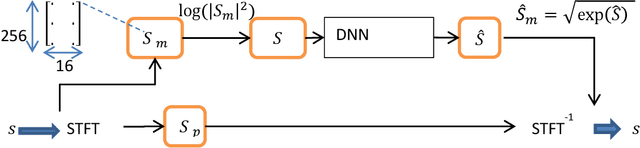

Speech enhancement concerns the processes required to remove unwanted background sounds from the target speech to improve its quality and intelligibility. In this paper, a novel approach for single-channel speech enhancement is presented, using colored spectrograms. We propose the use of a deep neural network (DNN) architecture adapted from the pix2pix generative adversarial network (GAN) and train it over colored spectrograms of speech to denoise them. After denoising, the colors of spectrograms are translated to magnitudes of short-time Fourier transform (STFT) using a shallow regression neural network. These estimated STFT magnitudes are later combined with the noisy phases to obtain an enhanced speech. The results show an improvement of almost 0.84 points in the perceptual evaluation of speech quality (PESQ) and 1% in the short-term objective intelligibility (STOI) over the unprocessed noisy data. The gain in quality and intelligibility over the unprocessed signal is almost equal to the gain achieved by the baseline methods used for comparison with the proposed model, but at a much reduced computational cost. The proposed solution offers a comparative PESQ score at almost 10 times reduced computational cost than a similar baseline model that has generated the highest PESQ score trained on grayscaled spectrograms, while it provides only a 1% deficit in STOI at 28 times reduced computational cost when compared to another baseline system based on convolutional neural network-GAN (CNN-GAN) that produces the most intelligible speech.
Blind Restoration of Real-World Audio by 1D Operational GANs
Dec 30, 2022Objective: Despite numerous studies proposed for audio restoration in the literature, most of them focus on an isolated restoration problem such as denoising or dereverberation, ignoring other artifacts. Moreover, assuming a noisy or reverberant environment with limited number of fixed signal-to-distortion ratio (SDR) levels is a common practice. However, real-world audio is often corrupted by a blend of artifacts such as reverberation, sensor noise, and background audio mixture with varying types, severities, and duration. In this study, we propose a novel approach for blind restoration of real-world audio signals by Operational Generative Adversarial Networks (Op-GANs) with temporal and spectral objective metrics to enhance the quality of restored audio signal regardless of the type and severity of each artifact corrupting it. Methods: 1D Operational-GANs are used with generative neuron model optimized for blind restoration of any corrupted audio signal. Results: The proposed approach has been evaluated extensively over the benchmark TIMIT-RAR (speech) and GTZAN-RAR (non-speech) datasets corrupted with a random blend of artifacts each with a random severity to mimic real-world audio signals. Average SDR improvements of over 7.2 dB and 4.9 dB are achieved, respectively, which are substantial when compared with the baseline methods. Significance: This is a pioneer study in blind audio restoration with the unique capability of direct (time-domain) restoration of real-world audio whilst achieving an unprecedented level of performance for a wide SDR range and artifact types. Conclusion: 1D Op-GANs can achieve robust and computationally effective real-world audio restoration with significantly improved performance. The source codes and the generated real-world audio datasets are shared publicly with the research community in a dedicated GitHub repository1.
Preserving the beamforming effect for spatial cue-based pseudo-binaural dereverberation of a single source
Aug 10, 2022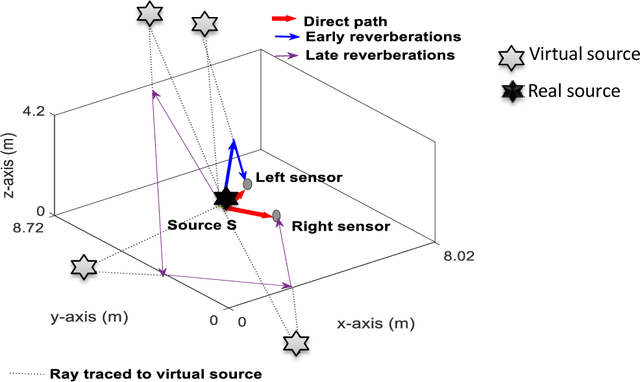

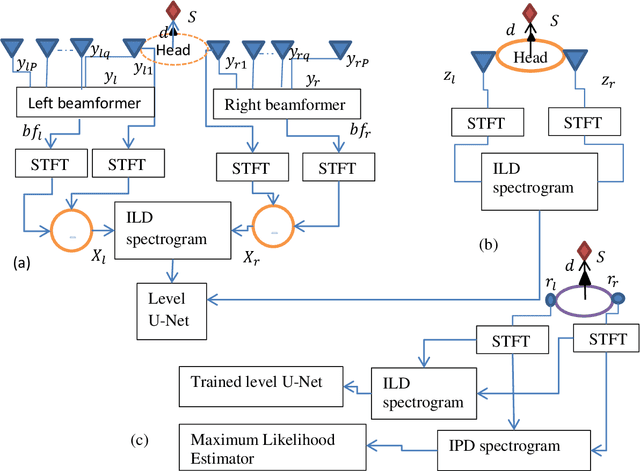

Reverberations are unavoidable in enclosures, resulting in reduced intelligibility for hearing impaired and non native listeners and even for the normal hearing listeners in noisy circumstances. It also degrades the performance of machine listening applications. In this paper, we propose a novel approach of binaural dereverberation of a single speech source, using the differences in the interaural cues of the direct path signal and the reverberations. Two beamformers, spaced at an interaural distance, are used to extract the reverberations from the reverberant speech. The interaural cues generated by these reverberations and those generated by the direct path signal act as a two class dataset, used for the training of U-Net (a deep convolutional neural network). After its training, the beamformers are removed and the trained U-Net along with the maximum likelihood estimation (MLE) algorithm is used to discriminate between the direct path cues from the reverberation cues, when the system is exposed to the interaural spectrogram of the reverberant speech signal. Our proposed model has outperformed the classical signal processing dereverberation model weighted prediction error in terms of cepstral distance (CEP), frequency weighted segmental signal to noise ratio (FWSEGSNR) and signal to reverberation modulation energy ratio (SRMR) by 1.4 points, 8 dB and 0.6dB. It has achieved better performance than the deep learning based dereverberation model by gaining 1.3 points improvement in CEP with comparable FWSEGSNR, using training dataset which is almost 8 times smaller than required for that model. The proposed model also sustained its performance under relatively similar unseen acoustic conditions and at positions in the vicinity of its training position.
Recycling an anechoic pre-trained speech separation deep neural network for binaural dereverberation of a single source
Aug 09, 2022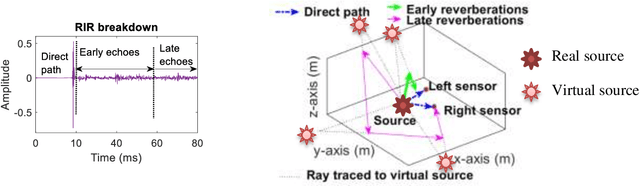

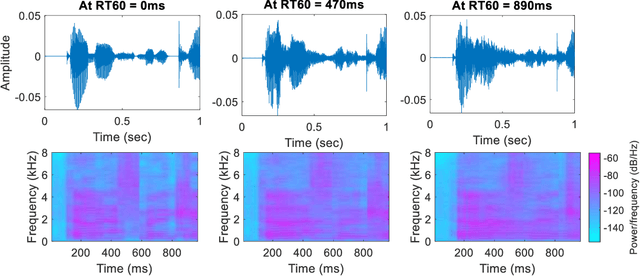

Reverberation results in reduced intelligibility for both normal and hearing-impaired listeners. This paper presents a novel psychoacoustic approach of dereverberation of a single speech source by recycling a pre-trained binaural anechoic speech separation neural network. As training the deep neural network (DNN) is a lengthy and computationally expensive process, the advantage of using a pre-trained separation network for dereverberation is that the network does not need to be retrained, saving both time and computational resources. The interaural cues of a reverberant source are given to this pretrained neural network to discriminate between the direct path signal and the reverberant speech. The results show an average improvement of 1.3% in signal intelligibility, 0.83 dB in SRMR (signal to reverberation energy ratio) and 0.16 points in perceptual evaluation of speech quality (PESQ) over other state-of-the-art signal processing dereverberation algorithms and 14% in intelligibility and 0.35 points in quality over orthogonal matching pursuit with spectral subtraction (OSS), a machine learning based dereverberation algorithm.
BIO-CXRNET: A Robust Multimodal Stacking Machine Learning Technique for Mortality Risk Prediction of COVID-19 Patients using Chest X-Ray Images and Clinical Data
Jun 15, 2022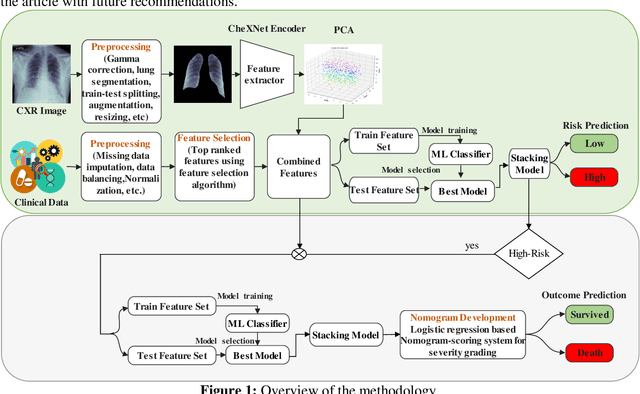
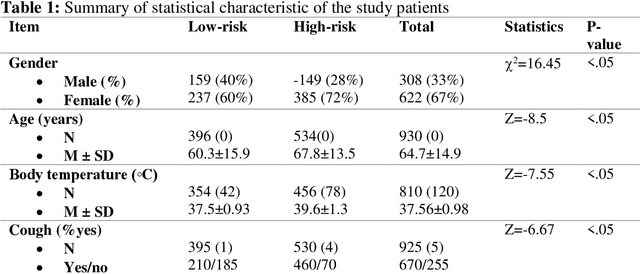
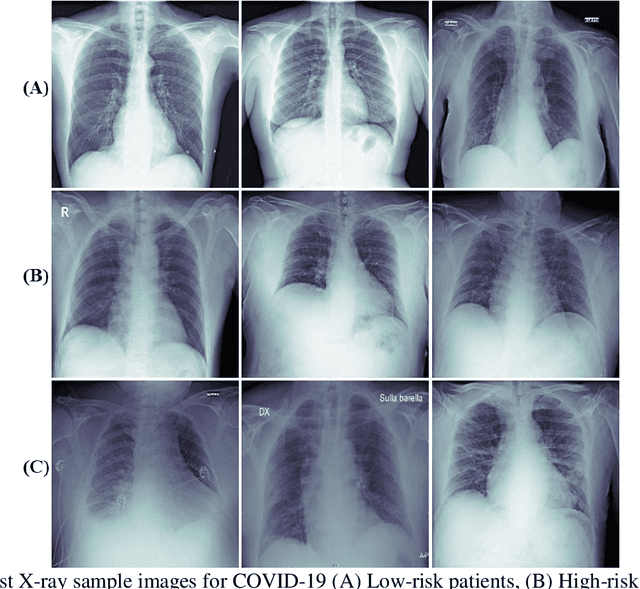

Fast and accurate detection of the disease can significantly help in reducing the strain on the healthcare facility of any country to reduce the mortality during any pandemic. The goal of this work is to create a multimodal system using a novel machine learning framework that uses both Chest X-ray (CXR) images and clinical data to predict severity in COVID-19 patients. In addition, the study presents a nomogram-based scoring technique for predicting the likelihood of death in high-risk patients. This study uses 25 biomarkers and CXR images in predicting the risk in 930 COVID-19 patients admitted during the first wave of COVID-19 (March-June 2020) in Italy. The proposed multimodal stacking technique produced the precision, sensitivity, and F1-score, of 89.03%, 90.44%, and 89.03%, respectively to identify low or high-risk patients. This multimodal approach improved the accuracy by 6% in comparison to the CXR image or clinical data alone. Finally, nomogram scoring system using multivariate logistic regression -- was used to stratify the mortality risk among the high-risk patients identified in the first stage. Lactate Dehydrogenase (LDH), O2 percentage, White Blood Cells (WBC) Count, Age, and C-reactive protein (CRP) were identified as useful predictor using random forest feature selection model. Five predictors parameters and a CXR image based nomogram score was developed for quantifying the probability of death and categorizing them into two risk groups: survived (<50%), and death (>=50%), respectively. The multi-modal technique was able to predict the death probability of high-risk patients with an F1 score of 92.88 %. The area under the curves for the development and validation cohorts are 0.981 and 0.939, respectively.
Building an Effective Automated Assessment System for C/C++ Introductory Programming Courses in ODL Environment
May 24, 2022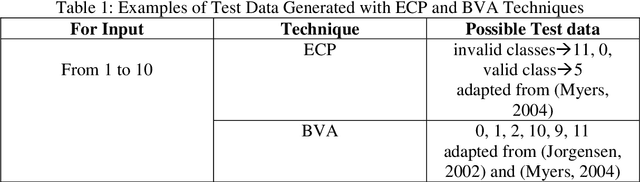
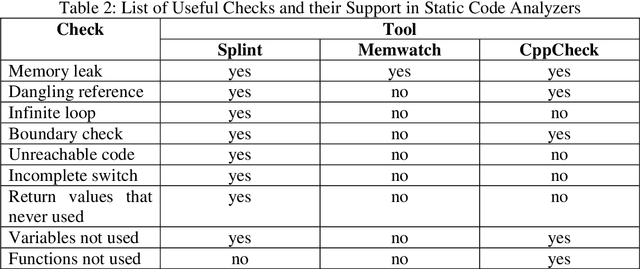
Assessments help in evaluating the knowledge gained by a learner at any specific point as well as in continuous improvement of the curriculum design and the whole learning process. However, with the increase in students' enrollment at University level in either conventional or distance education environment, traditional ways of assessing students' work are becoming insufficient in terms of both time and effort. In distance education environment, such assessments become additionally more challenging in terms of hefty remuneration for hiring large number of tutors. The availability of automated tools to assist the evaluation of students' work and providing students with appropriate and timely feedback can really help in overcoming these problems. We believe that building such tools for assessing students' work for all kinds of courses in not yet possible. However, courses that involve some formal language of expression can be automated, such as, programming courses in Computer Science (CS) discipline. Instructors provide various practical exercises to students as assignments to build these skills. Usually, instructors manually grade and provide feedbacks on these assignments. Although in literature, various tools have been reported to automate this process, but most of these tools have been developed by the host institutions themselves for their own use. We at COMSATS Institute of Information Technology, Lahore are conducting a pioneer effort in Pakistan to automate the marking of assignments of introductory programming courses that involve C or C++ languages with the capability of associating appropriate feedbacks for students. In this paper, we basically identify different components that we believe are necessary in building an effective automated assessment system in the context of introductory programming courses that involve C/C++ programming.
Evaluation of Preprocessing Techniques for U-Net Based Automated Liver Segmentation
Mar 26, 2021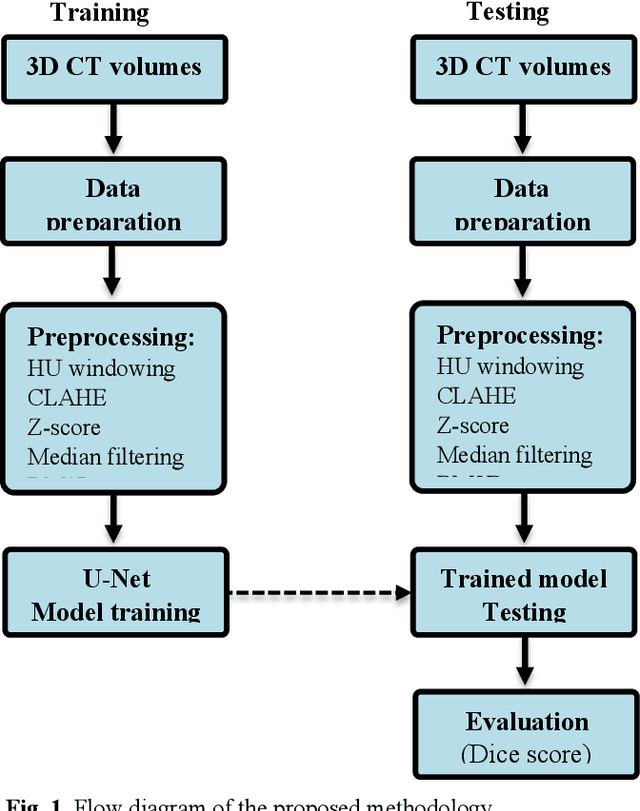
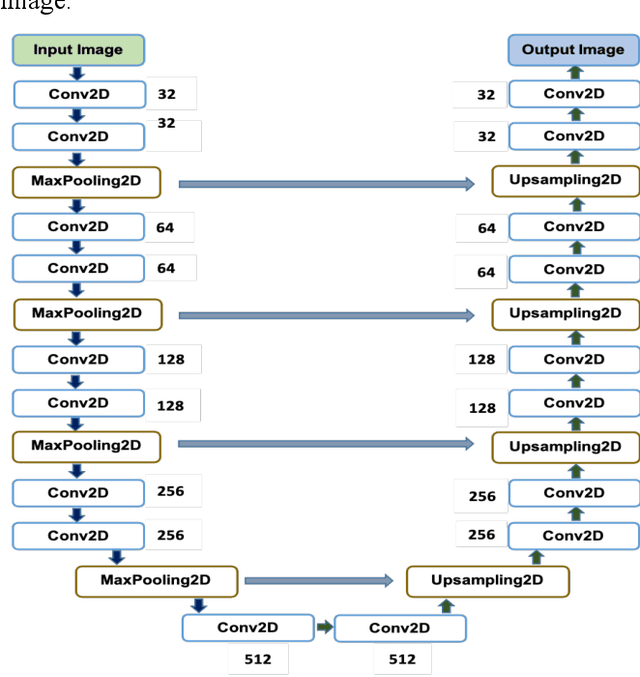
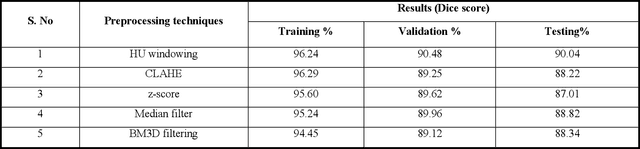
To extract liver from medical images is a challenging task due to similar intensity values of liver with adjacent organs, various contrast levels, various noise associated with medical images and irregular shape of liver. To address these issues, it is important to preprocess the medical images, i.e., computerized tomography (CT) and magnetic resonance imaging (MRI) data prior to liver analysis and quantification. This paper investigates the impact of permutation of various preprocessing techniques for CT images, on the automated liver segmentation using deep learning, i.e., U-Net architecture. The study focuses on Hounsfield Unit (HU) windowing, contrast limited adaptive histogram equalization (CLAHE), z-score normalization, median filtering and Block-Matching and 3D (BM3D) filtering. The segmented results show that combination of three techniques; HU-windowing, median filtering and z-score normalization achieve optimal performance with Dice coefficient of 96.93%, 90.77% and 90.84% for training, validation and testing respectively.