 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving the beamforming effect for spatial cue-based pseudo-binaural dereverberation of a single source
Aug 10, 2022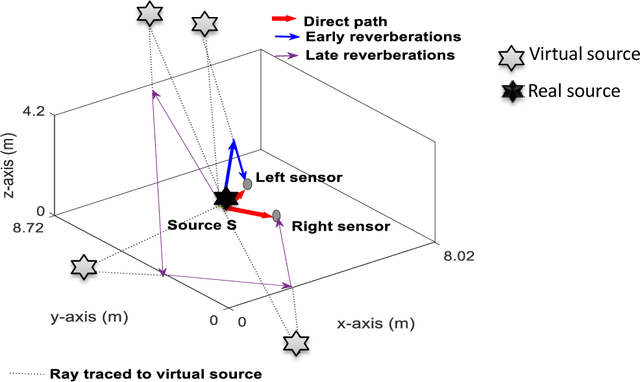

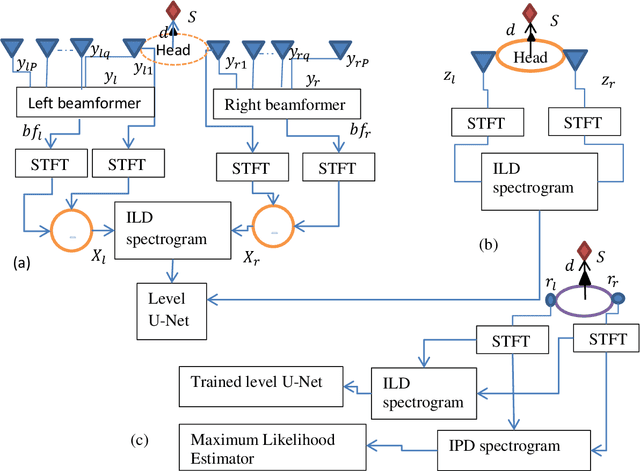

Reverberations are unavoidable in enclosures, resulting in reduced intelligibility for hearing impaired and non native listeners and even for the normal hearing listeners in noisy circumstances. It also degrades the performance of machine listening applications. In this paper, we propose a novel approach of binaural dereverberation of a single speech source, using the differences in the interaural cues of the direct path signal and the reverberations. Two beamformers, spaced at an interaural distance, are used to extract the reverberations from the reverberant speech. The interaural cues generated by these reverberations and those generated by the direct path signal act as a two class dataset, used for the training of U-Net (a deep convolutional neural network). After its training, the beamformers are removed and the trained U-Net along with the maximum likelihood estimation (MLE) algorithm is used to discriminate between the direct path cues from the reverberation cues, when the system is exposed to the interaural spectrogram of the reverberant speech signal. Our proposed model has outperformed the classical signal processing dereverberation model weighted prediction error in terms of cepstral distance (CEP), frequency weighted segmental signal to noise ratio (FWSEGSNR) and signal to reverberation modulation energy ratio (SRMR) by 1.4 points, 8 dB and 0.6dB. It has achieved better performance than the deep learning based dereverberation model by gaining 1.3 points improvement in CEP with comparable FWSEGSNR, using training dataset which is almost 8 times smaller than required for that model. The proposed model also sustained its performance under relatively similar unseen acoustic conditions and at positions in the vicinity of its training position.
Recycling an anechoic pre-trained speech separation deep neural network for binaural dereverberation of a single source
Aug 09, 2022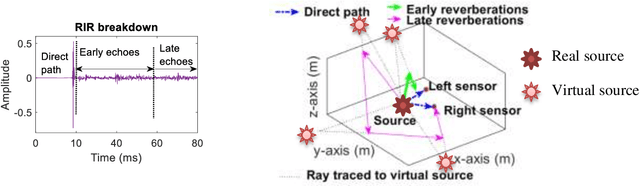

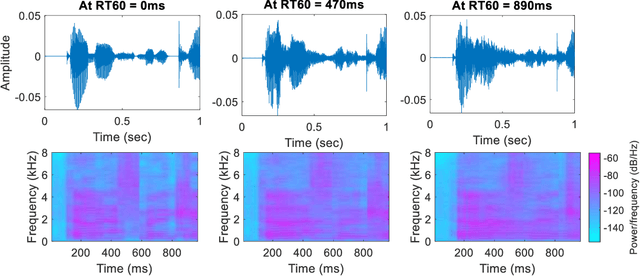

Reverberation results in reduced intelligibility for both normal and hearing-impaired listeners. This paper presents a novel psychoacoustic approach of dereverberation of a single speech source by recycling a pre-trained binaural anechoic speech separation neural network. As training the deep neural network (DNN) is a lengthy and computationally expensive process, the advantage of using a pre-trained separation network for dereverberation is that the network does not need to be retrained, saving both time and computational resources. The interaural cues of a reverberant source are given to this pretrained neural network to discriminate between the direct path signal and the reverberant speech. The results show an average improvement of 1.3% in signal intelligibility, 0.83 dB in SRMR (signal to reverberation energy ratio) and 0.16 points in perceptual evaluation of speech quality (PESQ) over other state-of-the-art signal processing dereverberation algorithms and 14% in intelligibility and 0.35 points in quality over orthogonal matching pursuit with spectral subtraction (OSS), a machine learning based dereverberation algorithm.
Integration of deep learning with expectation maximization for spatial cue based speech separation in reverberant conditions
Feb 26, 2021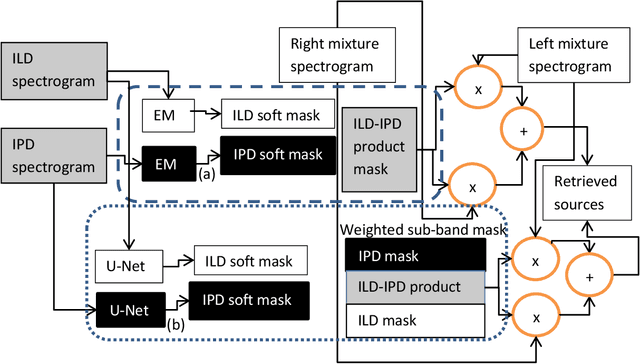


In this paper, we formulate a blind source separation (BSS) framework, which allows integrating U-Net based deep learning source separation network with probabilistic spatial machine learning expectation maximization (EM) algorithm for separating speech in reverberant conditions. Our proposed model uses a pre-trained deep learning convolutional neural network, U-Net, for clustering the interaural level difference (ILD) cues and machine learning expectation maximization (EM) algorithm for clustering the interaural phase difference (IPD) cues. The integrated model exploits the complementary strengths of the two approaches to BSS: the strong modeling power of supervised neural networks and the ease of unsupervised machine learning algorithms, whose few parameters can be estimated on as little as a single segment of an audio mixture. The results show an average improvement of 4.3 dB in signal to distortion ratio (SDR) and 4.3% in short time speech intelligibility (STOI) over the EM based source separation algorithm MESSL-GS (model-based expectation-maximization source separation and localization with garbage source) and 4.5 dB in SDR and 8% in STOI over deep learning convolutional neural network (U-Net) based speech separation algorithm SONET under the reverberant conditions ranging from anechoic to those mostly encountered in the real world.