 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of deep learning with expectation maximization for spatial cue based speech separation in reverberant conditions
Paper and Code
Feb 26, 2021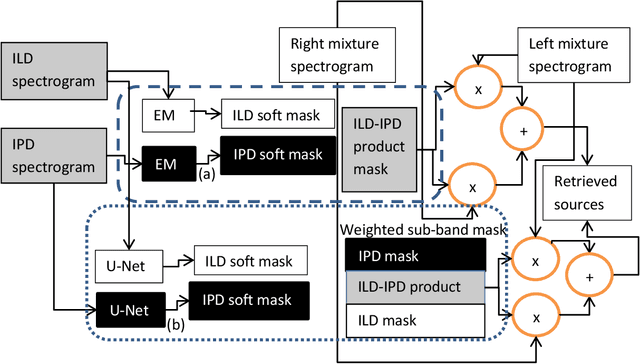
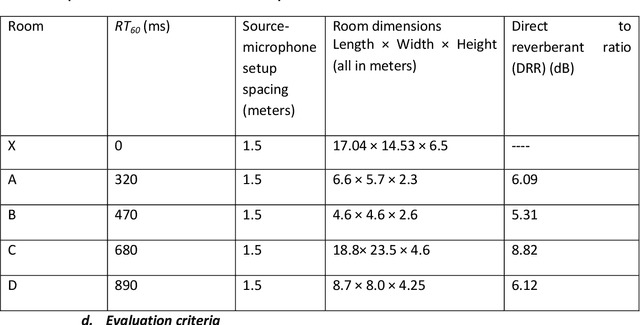


In this paper, we formulate a blind source separation (BSS) framework, which allows integrating U-Net based deep learning source separation network with probabilistic spatial machine learning expectation maximization (EM) algorithm for separating speech in reverberant conditions. Our proposed model uses a pre-trained deep learning convolutional neural network, U-Net, for clustering the interaural level difference (ILD) cues and machine learning expectation maximization (EM) algorithm for clustering the interaural phase difference (IPD) cues. The integrated model exploits the complementary strengths of the two approaches to BSS: the strong modeling power of supervised neural networks and the ease of unsupervised machine learning algorithms, whose few parameters can be estimated on as little as a single segment of an audio mixture. The results show an average improvement of 4.3 dB in signal to distortion ratio (SDR) and 4.3% in short time speech intelligibility (STOI) over the EM based source separation algorithm MESSL-GS (model-based expectation-maximization source separation and localization with garbage source) and 4.5 dB in SDR and 8% in STOI over deep learning convolutional neural network (U-Net) based speech separation algorithm SONET under the reverberant conditions ranging from anechoic to those mostly encountered in the real world.