 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding an Effective Automated Assessment System for C/C++ Introductory Programming Courses in ODL Environment
May 24, 2022
Assessments help in evaluating the knowledge gained by a learner at any specific point as well as in continuous improvement of the curriculum design and the whole learning process. However, with the increase in students' enrollment at University level in either conventional or distance education environment, traditional ways of assessing students' work are becoming insufficient in terms of both time and effort. In distance education environment, such assessments become additionally more challenging in terms of hefty remuneration for hiring large number of tutors. The availability of automated tools to assist the evaluation of students' work and providing students with appropriate and timely feedback can really help in overcoming these problems. We believe that building such tools for assessing students' work for all kinds of courses in not yet possible. However, courses that involve some formal language of expression can be automated, such as, programming courses in Computer Science (CS) discipline. Instructors provide various practical exercises to students as assignments to build these skills. Usually, instructors manually grade and provide feedbacks on these assignments. Although in literature, various tools have been reported to automate this process, but most of these tools have been developed by the host institutions themselves for their own use. We at COMSATS Institute of Information Technology, Lahore are conducting a pioneer effort in Pakistan to automate the marking of assignments of introductory programming courses that involve C or C++ languages with the capability of associating appropriate feedbacks for students. In this paper, we basically identify different components that we believe are necessary in building an effective automated assessment system in the context of introductory programming courses that involve C/C++ programming.
Urdu Morphology, Orthography and Lexicon Extraction
Apr 06, 2022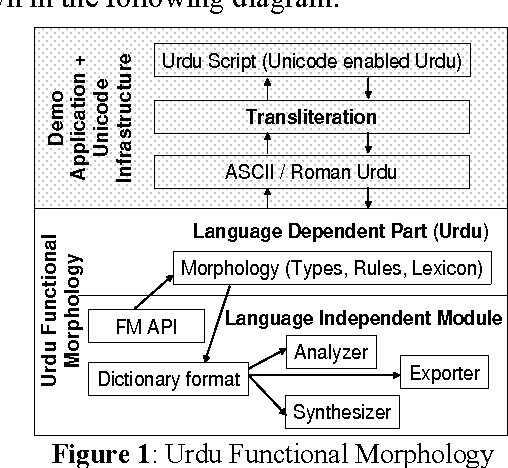
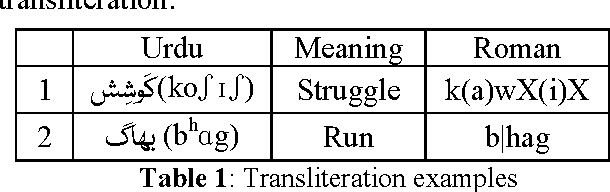
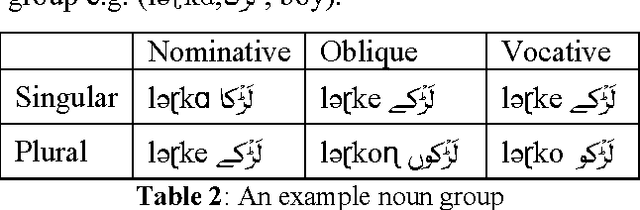
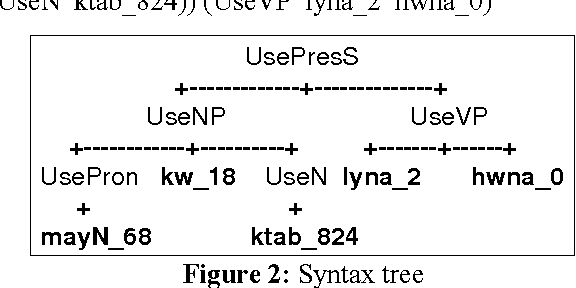
Urdu is a challenging language because of, first, its Perso-Arabic script and second, its morphological system having inherent grammatical forms and vocabulary of Arabic, Persian and the native languages of South Asia. This paper describes an implementation of the Urdu language as a software API, and we deal with orthography, morphology and the extraction of the lexicon. The morphology is implemented in a toolkit called Functional Morphology (Forsberg & Ranta, 2004), which is based on the idea of dealing grammars as software libraries. Therefore this implementation could be reused in applications such as intelligent search of keywords, language training and infrastructure for syntax. We also present an implementation of a small part of Urdu syntax to demonstrate this reusability.
The 2021 Urdu Fake News Detection Task using Supervised Machine Learning and Feature Combinations
Apr 06, 2022
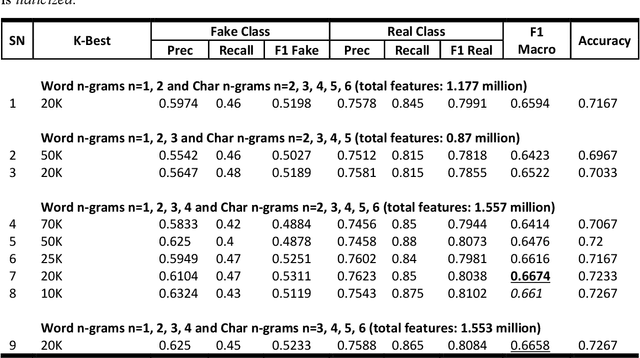
This paper presents the system description submitted at the FIRE Shared Task: "The 2021 Fake News Detection in the Urdu Language". This challenge aims at automatically identifying Fake news written in Urdu. Our submitted results ranked fifth in the competition. However, after the result declaration of the competition, we managed to attain even better results than the submitted results. The best F1 Macro score achieved by one of our models is 0.6674, higher than the second-best score in the competition. The result is achieved on Support Vector Machines (polynomial kernel degree 1) with stopwords removed, lemmatization applied, and selecting the 20K best features out of 1.557 million features in total (which were produced by Word n-grams n=1,2,3,4 and Char n-grams n=2,3,4,5,6). The code is made available for reproducibility.
Abusive and Threatening Language Detection in Urdu using Supervised Machine Learning and Feature Combinations
Apr 06, 2022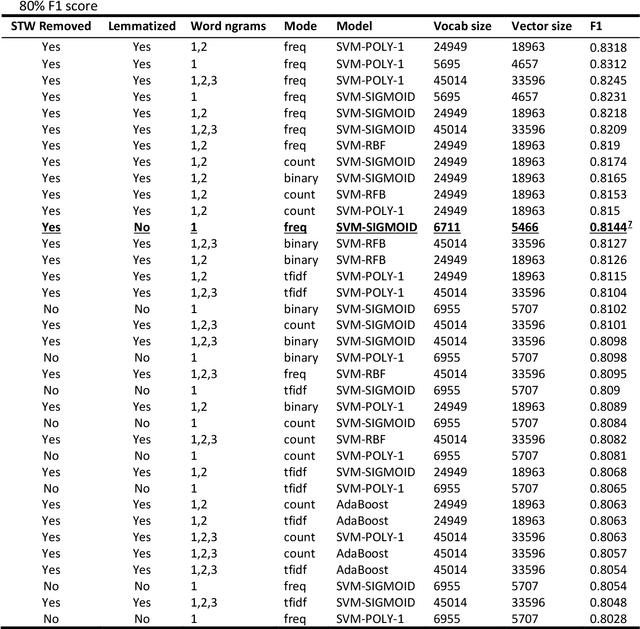



This paper presents the system descriptions submitted at the FIRE Shared Task 2021 on Urdu's Abusive and Threatening Language Detection Task. This challenge aims at automatically identifying abusive and threatening tweets written in Urdu. Our submitted results were selected for the third recognition at the competition. This paper reports a non-exhaustive list of experiments that allowed us to reach the submitted results. Moreover, after the result declaration of the competition, we managed to attain even better results than the submitted results. Our models achieved 0.8318 F1 score on Task A (Abusive Language Detection for Urdu Tweets) and 0.4931 F1 score on Task B (Threatening Language Detection for Urdu Tweets). Results show that Support Vector Machines with stopwords removed, lemmatization applied, and features vector created by the combinations of word n-grams for n=1,2,3 produced the best results for Task A. For Task B, Support Vector Machines with stopwords removed, lemmatization not applied, feature vector created from a pre-trained Urdu Word2Vec (on word unigrams and bigrams), and making the dataset balanced using oversampling technique produced the best results. The code is made available for reproducibility.