 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbusive and Threatening Language Detection in Urdu using Supervised Machine Learning and Feature Combinations
Paper and Code
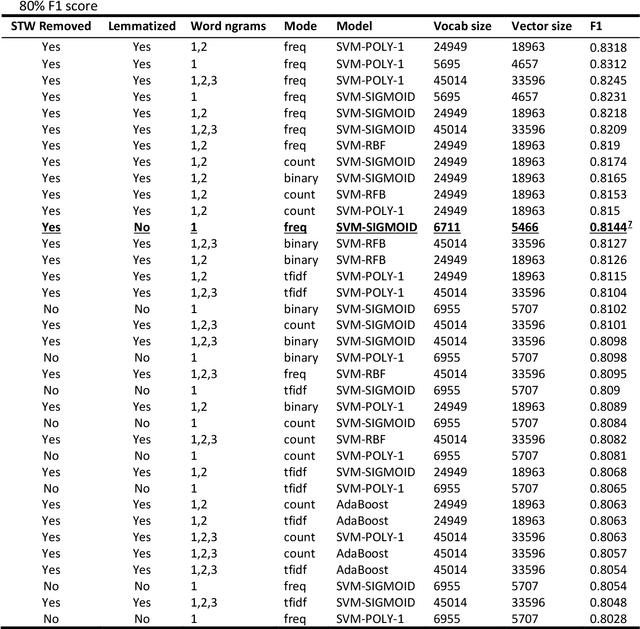



This paper presents the system descriptions submitted at the FIRE Shared Task 2021 on Urdu's Abusive and Threatening Language Detection Task. This challenge aims at automatically identifying abusive and threatening tweets written in Urdu. Our submitted results were selected for the third recognition at the competition. This paper reports a non-exhaustive list of experiments that allowed us to reach the submitted results. Moreover, after the result declaration of the competition, we managed to attain even better results than the submitted results. Our models achieved 0.8318 F1 score on Task A (Abusive Language Detection for Urdu Tweets) and 0.4931 F1 score on Task B (Threatening Language Detection for Urdu Tweets). Results show that Support Vector Machines with stopwords removed, lemmatization applied, and features vector created by the combinations of word n-grams for n=1,2,3 produced the best results for Task A. For Task B, Support Vector Machines with stopwords removed, lemmatization not applied, feature vector created from a pre-trained Urdu Word2Vec (on word unigrams and bigrams), and making the dataset balanced using oversampling technique produced the best results. The code is made available for reproducibility.