 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-agnostic Automated Lumbar MRI Segmentation using a Cascaded Model Based on Generative Neurons
Nov 23, 2024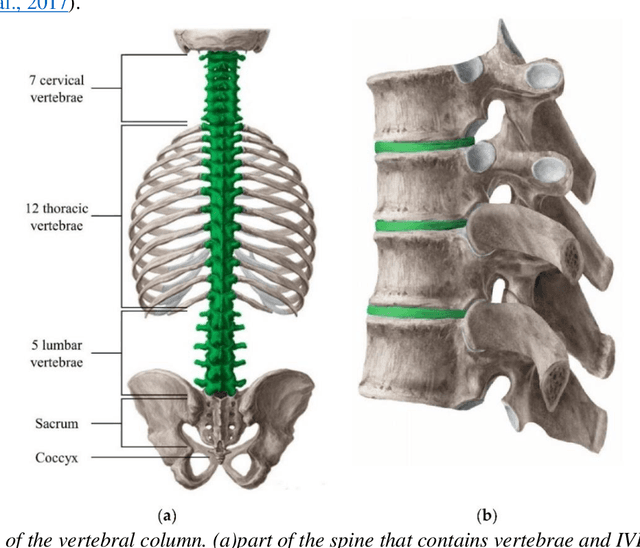

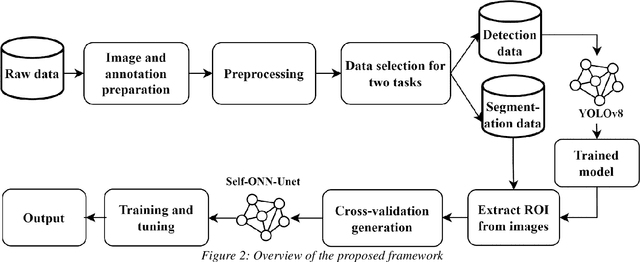
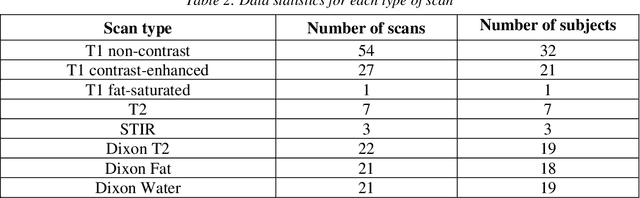
Automated lumbar spine segmentation is very crucial for modern diagnosis systems. In this study, we introduce a novel machine-agnostic approach for segmenting lumbar vertebrae and intervertebral discs from MRI images, employing a cascaded model that synergizes an ROI detection and a Self-organized Operational Neural Network (Self-ONN)-based encoder-decoder network for segmentation. Addressing the challenge of diverse MRI modalities, our methodology capitalizes on a unique dataset comprising images from 12 scanners and 34 subjects, enhanced through strategic preprocessing and data augmentation techniques. The YOLOv8 medium model excels in ROI extraction, achieving an excellent performance of 0.916 mAP score. Significantly, our Self-ONN-based model, combined with a DenseNet121 encoder, demonstrates excellent performance in lumbar vertebrae and IVD segmentation with a mean Intersection over Union (IoU) of 83.66%, a sensitivity of 91.44%, and Dice Similarity Coefficient (DSC) of 91.03%, as validated through rigorous 10-fold cross-validation. This study not only showcases an effective approach to MRI segmentation in spine-related disorders but also sets the stage for future advancements in automated diagnostic tools, emphasizing the need for further dataset expansion and model refinement for broader clinical applicability.
Can Ensemble of Classifiers Provide Better Recognition Results in Packaging Activity?
Nov 05, 2022Skeleton-based Motion Capture (MoCap) systems have been widely used in the game and film industry for mimicking complex human actions for a long time. MoCap data has also proved its effectiveness in human activity recognition tasks. However, it is a quite challenging task for smaller datasets. The lack of such data for industrial activities further adds to the difficulties. In this work, we have proposed an ensemble-based machine learning methodology that is targeted to work better on MoCap datasets. The experiments have been performed on the MoCap data given in the Bento Packaging Activity Recognition Challenge 2021. Bento is a Japanese word that resembles lunch-box. Upon processing the raw MoCap data at first, we have achieved an astonishing accuracy of 98% on 10-fold Cross-Validation and 82% on Leave-One-Out-Cross-Validation by using the proposed ensemble model.