 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$α^3$-SecBench: A Large-Scale Evaluation Suite of Security, Resilience, and Trust for LLM-based UAV Agents over 6G Networks
Jan 26, 2026Autonomous unmanned aerial vehicle (UAV) systems are increasingly deployed in safety-critical, networked environments where they must operate reliably in the presence of malicious adversaries. While recent benchmarks have evaluated large language model (LLM)-based UAV agents in reasoning, navigation, and efficiency, systematic assessment of security, resilience, and trust under adversarial conditions remains largely unexplored, particularly in emerging 6G-enabled settings. We introduce $α^{3}$-SecBench, the first large-scale evaluation suite for assessing the security-aware autonomy of LLM-based UAV agents under realistic adversarial interference. Building on multi-turn conversational UAV missions from $α^{3}$-Bench, the framework augments benign episodes with 20,000 validated security overlay attack scenarios targeting seven autonomy layers, including sensing, perception, planning, control, communication, edge/cloud infrastructure, and LLM reasoning. $α^{3}$-SecBench evaluates agents across three orthogonal dimensions: security (attack detection and vulnerability attribution), resilience (safe degradation behavior), and trust (policy-compliant tool usage). We evaluate 23 state-of-the-art LLMs from major industrial providers and leading AI labs using thousands of adversarially augmented UAV episodes sampled from a corpus of 113,475 missions spanning 175 threat types. While many models reliably detect anomalous behavior, effective mitigation, vulnerability attribution, and trustworthy control actions remain inconsistent. Normalized overall scores range from 12.9% to 57.1%, highlighting a significant gap between anomaly detection and security-aware autonomous decision-making. We release $α^{3}$-SecBench on GitHub: https://github.com/maferrag/AlphaSecBench
AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems
Jan 23, 2026The rapid advancement of large language models (LLMs) has sparked growing interest in their integration into autonomous systems for reasoning-driven perception, planning, and decision-making. However, evaluating and training such agentic AI models remains challenging due to the lack of large-scale, structured, and safety-critical benchmarks. This paper introduces AgentDrive, an open benchmark dataset containing 300,000 LLM-generated driving scenarios designed for training, fine-tuning, and evaluating autonomous agents under diverse conditions. AgentDrive formalizes a factorized scenario space across seven orthogonal axes: scenario type, driver behavior, environment, road layout, objective, difficulty, and traffic density. An LLM-driven prompt-to-JSON pipeline generates semantically rich, simulation-ready specifications that are validated against physical and schema constraints. Each scenario undergoes simulation rollouts, surrogate safety metric computation, and rule-based outcome labeling. To complement simulation-based evaluation, we introduce AgentDrive-MCQ, a 100,000-question multiple-choice benchmark spanning five reasoning dimensions: physics, policy, hybrid, scenario, and comparative reasoning. We conduct a large-scale evaluation of fifty leading LLMs on AgentDrive-MCQ. Results show that while proprietary frontier models perform best in contextual and policy reasoning, advanced open models are rapidly closing the gap in structured and physics-grounded reasoning. We release the AgentDrive dataset, AgentDrive-MCQ benchmark, evaluation code, and related materials at https://github.com/maferrag/AgentDrive
$α^3$-Bench: A Unified Benchmark of Safety, Robustness, and Efficiency for LLM-Based UAV Agents over 6G Networks
Jan 01, 2026Large Language Models (LLMs) are increasingly used as high level controllers for autonomous Unmanned Aerial Vehicle (UAV) missions. However, existing evaluations rarely assess whether such agents remain safe, protocol compliant, and effective under realistic next generation networking constraints. This paper introduces $α^3$-Bench, a benchmark for evaluating LLM driven UAV autonomy as a multi turn conversational reasoning and control problem operating under dynamic 6G conditions. Each mission is formulated as a language mediated control loop between an LLM based UAV agent and a human operator, where decisions must satisfy strict schema validity, mission policies, speaker alternation, and safety constraints while adapting to fluctuating network slices, latency, jitter, packet loss, throughput, and edge load variations. To reflect modern agentic workflows, $α^3$-Bench integrates a dual action layer supporting both tool calls and agent to agent coordination, enabling evaluation of tool use consistency and multi agent interactions. We construct a large scale corpus of 113k conversational UAV episodes grounded in UAVBench scenarios and evaluate 17 state of the art LLMs using a fixed subset of 50 episodes per scenario under deterministic decoding. We propose a composite $α^3$ metric that unifies six pillars: Task Outcome, Safety Policy, Tool Consistency, Interaction Quality, Network Robustness, and Communication Cost, with efficiency normalized scores per second and per thousand tokens. Results show that while several models achieve high mission success and safety compliance, robustness and efficiency vary significantly under degraded 6G conditions, highlighting the need for network aware and resource efficient LLM based UAV agents. The dataset is publicly available on GitHub : https://github.com/maferrag/AlphaBench
UAVBench: An Open Benchmark Dataset for Autonomous and Agentic AI UAV Systems via LLM-Generated Flight Scenarios
Nov 14, 2025



Autonomous aerial systems increasingly rely on large language models (LLMs) for mission planning, perception, and decision-making, yet the lack of standardized and physically grounded benchmarks limits systematic evaluation of their reasoning capabilities. To address this gap, we introduce UAVBench, an open benchmark dataset comprising 50,000 validated UAV flight scenarios generated through taxonomy-guided LLM prompting and multi-stage safety validation. Each scenario is encoded in a structured JSON schema that includes mission objectives, vehicle configuration, environmental conditions, and quantitative risk labels, providing a unified representation of UAV operations across diverse domains. Building on this foundation, we present UAVBench_MCQ, a reasoning-oriented extension containing 50,000 multiple-choice questions spanning ten cognitive and ethical reasoning styles, ranging from aerodynamics and navigation to multi-agent coordination and integrated reasoning. This framework enables interpretable and machine-checkable assessment of UAV-specific cognition under realistic operational contexts. We evaluate 32 state-of-the-art LLMs, including GPT-5, ChatGPT-4o, Gemini 2.5 Flash, DeepSeek V3, Qwen3 235B, and ERNIE 4.5 300B, and find strong performance in perception and policy reasoning but persistent challenges in ethics-aware and resource-constrained decision-making. UAVBench establishes a reproducible and physically grounded foundation for benchmarking agentic AI in autonomous aerial systems and advancing next-generation UAV reasoning intelligence. To support open science and reproducibility, we release the UAVBench dataset, the UAVBench_MCQ benchmark, evaluation scripts, and all related materials on GitHub at https://github.com/maferrag/UAVBench
GAT-RWOS: Graph Attention-Guided Random Walk Oversampling for Imbalanced Data Classification
Dec 20, 2024Class imbalance poses a significant challenge in machine learning (ML), often leading to biased models favouring the majority class. In this paper, we propose GAT-RWOS, a novel graph-based oversampling method that combines the strengths of Graph Attention Networks (GATs) and random walk-based oversampling. GAT-RWOS leverages the attention mechanism of GATs to guide the random walk process, focusing on the most informative neighbourhoods for each minority node. By performing attention-guided random walks and interpolating features along the traversed paths, GAT-RWOS generates synthetic minority samples that expand class boundaries while preserving the original data distribution. Extensive experiments on a diverse set of imbalanced datasets demonstrate the effectiveness of GAT-RWOS in improving classification performance, outperforming state-of-the-art oversampling techniques. The proposed method has the potential to significantly improve the performance of ML models on imbalanced datasets and contribute to the development of more reliable classification systems.
Transformer-based Image and Video Inpainting: Current Challenges and Future Directions
Jun 28, 2024



Image inpainting is currently a hot topic within the field of computer vision. It offers a viable solution for various applications, including photographic restoration, video editing, and medical imaging. Deep learning advancements, notably convolutional neural networks (CNNs) and generative adversarial networks (GANs), have significantly enhanced the inpainting task with an improved capability to fill missing or damaged regions in an image or video through the incorporation of contextually appropriate details. These advancements have improved other aspects, including efficiency, information preservation, and achieving both realistic textures and structures. Recently, visual transformers have been exploited and offer some improvements to image or video inpainting. The advent of transformer-based architectures, which were initially designed for natural language processing, has also been integrated into computer vision tasks. These methods utilize self-attention mechanisms that excel in capturing long-range dependencies within data; therefore, they are particularly effective for tasks requiring a comprehensive understanding of the global context of an image or video. In this paper, we provide a comprehensive review of the current image or video inpainting approaches, with a specific focus on transformer-based techniques, with the goal to highlight the significant improvements and provide a guideline for new researchers in the field of image or video inpainting using visual transformers. We categorized the transformer-based techniques by their architectural configurations, types of damage, and performance metrics. Furthermore, we present an organized synthesis of the current challenges, and suggest directions for future research in the field of image or video inpainting.
Advanced Artificial Intelligence Algorithms in Cochlear Implants: Review of Healthcare Strategies, Challenges, and Perspectives
Mar 17, 2024



Automatic speech recognition (ASR) plays a pivotal role in our daily lives, offering utility not only for interacting with machines but also for facilitating communication for individuals with either partial or profound hearing impairments. The process involves receiving the speech signal in analogue form, followed by various signal processing algorithms to make it compatible with devices of limited capacity, such as cochlear implants (CIs). Unfortunately, these implants, equipped with a finite number of electrodes, often result in speech distortion during synthesis. Despite efforts by researchers to enhance received speech quality using various state-of-the-art signal processing techniques, challenges persist, especially in scenarios involving multiple sources of speech, environmental noise, and other circumstances. The advent of new artificial intelligence (AI) methods has ushered in cutting-edge strategies to address the limitations and difficulties associated with traditional signal processing techniques dedicated to CIs. This review aims to comprehensively review advancements in CI-based ASR and speech enhancement, among other related aspects. The primary objective is to provide a thorough overview of metrics and datasets, exploring the capabilities of AI algorithms in this biomedical field, summarizing and commenting on the best results obtained. Additionally, the review will delve into potential applications and suggest future directions to bridge existing research gaps in this domain.
End-to-End AI-Based Point-of-Care Diagnosis System for Classifying Respiratory Illnesses and Early Detection of COVID-19
Jun 28, 2020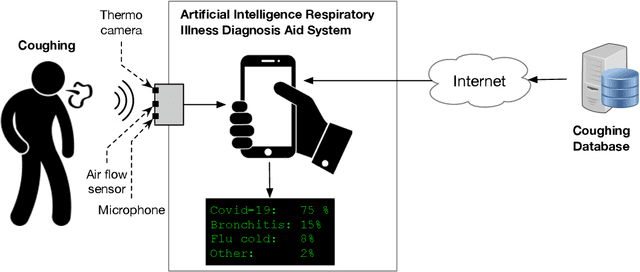
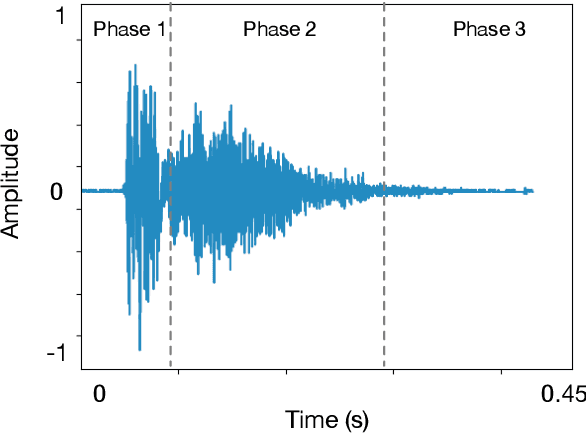
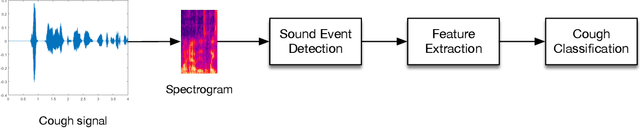

Respiratory symptoms can be a caused by different underlying conditions, and are often caused by viral infections, such as Influenza-like illnesses or other emerging viruses like the Coronavirus. These respiratory viruses, often, have common symptoms, including coughing, high temperature, congested nose, and difficulty breathing. However, early diagnosis of the type of the virus, can be crucial, especially in cases such as the recent COVID-19 pandemic. One of the factors that contributed to the spread of the pandemic, was the late diagnosis or confusing it with regular flu-like symptoms. Science has proved that one of the possible differentiators of the underlying causes of these different respiratory diseases is coughing, which comes in different types and forms. Therefore, a reliable lab-free tool for early and more accurate diagnosis that can differentiate between different respiratory diseases is very much needed. This paper proposes an end-to-end portable system that can record data from patients with symptom, including coughs (voluntary or involuntary) and translate them into health data for diagnosis, and with the aid of machine learning, classify them into different respiratory illnesses, including COVID-19. With the ongoing efforts to stop the spread of the COVID-19 disease everywhere today, and against similar diseases in the future, our proposed low cost and user-friendly solution can play an important part in the early diagnosis.