 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIS: A Novel Approach to Instance Selection with Graph Attention Networks
Dec 26, 2024



Instance selection (IS) is a crucial technique in machine learning that aims to reduce dataset size while maintaining model performance. This paper introduces a novel method called Graph Attention-based Instance Selection (GAIS), which leverages Graph Attention Networks (GATs) to identify the most informative instances in a dataset. GAIS represents the data as a graph and uses GATs to learn node representations, enabling it to capture complex relationships between instances. The method processes data in chunks, applies random masking and similarity thresholding during graph construction, and selects instances based on confidence scores from the trained GAT model. Experiments on 13 diverse datasets demonstrate that GAIS consistently outperforms traditional IS methods in terms of effectiveness, achieving high reduction rates (average 96\%) while maintaining or improving model performance. Although GAIS exhibits slightly higher computational costs, its superior performance in maintaining accuracy with significantly reduced training data makes it a promising approach for graph-based data selection.
Transformer-based Image and Video Inpainting: Current Challenges and Future Directions
Jun 28, 2024



Image inpainting is currently a hot topic within the field of computer vision. It offers a viable solution for various applications, including photographic restoration, video editing, and medical imaging. Deep learning advancements, notably convolutional neural networks (CNNs) and generative adversarial networks (GANs), have significantly enhanced the inpainting task with an improved capability to fill missing or damaged regions in an image or video through the incorporation of contextually appropriate details. These advancements have improved other aspects, including efficiency, information preservation, and achieving both realistic textures and structures. Recently, visual transformers have been exploited and offer some improvements to image or video inpainting. The advent of transformer-based architectures, which were initially designed for natural language processing, has also been integrated into computer vision tasks. These methods utilize self-attention mechanisms that excel in capturing long-range dependencies within data; therefore, they are particularly effective for tasks requiring a comprehensive understanding of the global context of an image or video. In this paper, we provide a comprehensive review of the current image or video inpainting approaches, with a specific focus on transformer-based techniques, with the goal to highlight the significant improvements and provide a guideline for new researchers in the field of image or video inpainting using visual transformers. We categorized the transformer-based techniques by their architectural configurations, types of damage, and performance metrics. Furthermore, we present an organized synthesis of the current challenges, and suggest directions for future research in the field of image or video inpainting.
A Deep Learning Framework for Spatiotemporal Ultrasound Localization Microscopy
Oct 12, 2023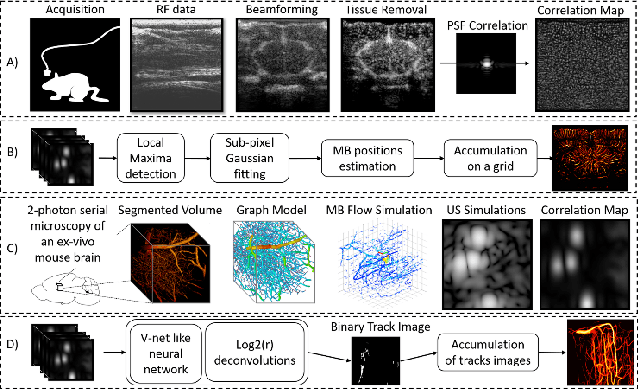
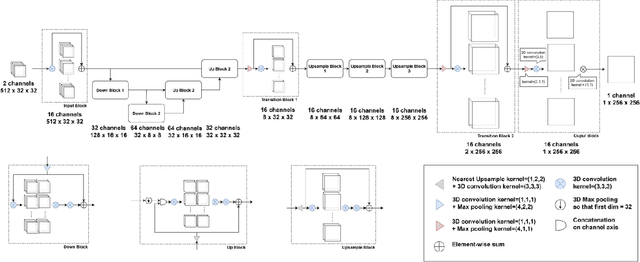
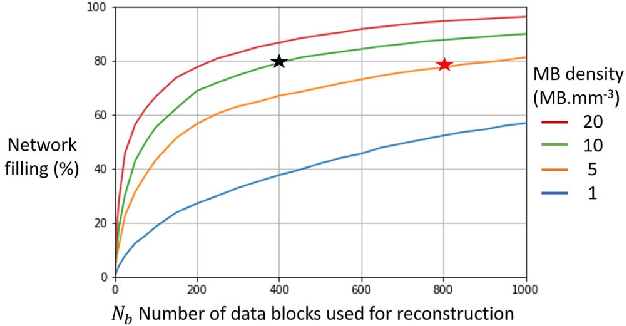
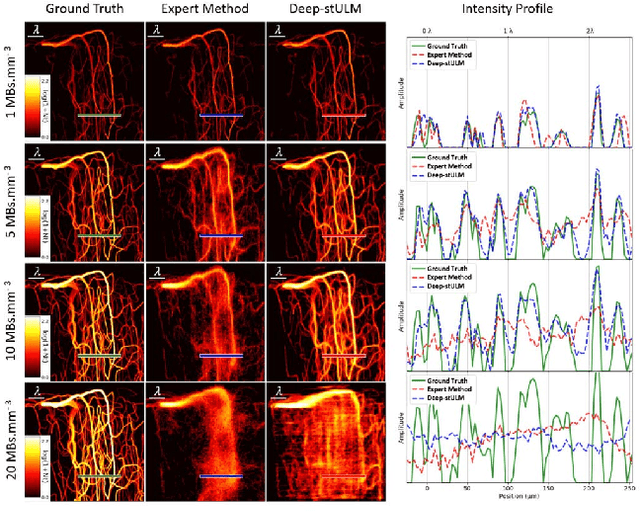
Ultrasound Localization Microscopy can resolve the microvascular bed down to a few micrometers. To achieve such performance microbubble contrast agents must perfuse the entire microvascular network. Microbubbles are then located individually and tracked over time to sample individual vessels, typically over hundreds of thousands of images. To overcome the fundamental limit of diffraction and achieve a dense reconstruction of the network, low microbubble concentrations must be used, which lead to acquisitions lasting several minutes. Conventional processing pipelines are currently unable to deal with interference from multiple nearby microbubbles, further reducing achievable concentrations. This work overcomes this problem by proposing a Deep Learning approach to recover dense vascular networks from ultrasound acquisitions with high microbubble concentrations. A realistic mouse brain microvascular network, segmented from 2-photon microscopy, was used to train a three-dimensional convolutional neural network based on a V-net architecture. Ultrasound data sets from multiple microbubbles flowing through the microvascular network were simulated and used as ground truth to train the 3D CNN to track microbubbles. The 3D-CNN approach was validated in silico using a subset of the data and in vivo on a rat brain acquisition. In silico, the CNN reconstructed vascular networks with higher precision (81%) than a conventional ULM framework (70%). In vivo, the CNN could resolve micro vessels as small as 10 $\mu$m with an increase in resolution when compared against a conventional approach.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works