 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Big to Fool: Resisting Deception in Language Models
Dec 13, 2024Large language models must balance their weight-encoded knowledge with in-context information from prompts to generate accurate responses. This paper investigates this interplay by analyzing how models of varying capacities within the same family handle intentionally misleading in-context information. Our experiments demonstrate that larger models exhibit higher resilience to deceptive prompts, showcasing an advanced ability to interpret and integrate prompt information with their internal knowledge. Furthermore, we find that larger models outperform smaller ones in following legitimate instructions, indicating that their resilience is not due to disregarding in-context information. We also show that this phenomenon is likely not a result of memorization but stems from the models' ability to better leverage implicit task-relevant information from the prompt alongside their internally stored knowledge.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
Jul 07, 2024



The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though recent LLMs seem capable of planning and reasoning given user instructions, their effectiveness in applying these capabilities for autonomous task solving remains underexplored. This is especially true in enterprise settings, where automated agents hold the promise of a high impact. To fill this gap, we propose WorkArena++, a novel benchmark consisting of 682 tasks corresponding to realistic workflows routinely performed by knowledge workers. WorkArena++ is designed to evaluate the planning, problem-solving, logical/arithmetic reasoning, retrieval, and contextual understanding abilities of web agents. Our empirical studies across state-of-the-art LLMs and vision-language models (VLMs), as well as human workers, reveal several challenges for such models to serve as useful assistants in the workplace. In addition to the benchmark, we provide a mechanism to effortlessly generate thousands of ground-truth observation/action traces, which can be used for fine-tuning existing models. Overall, we expect this work to serve as a useful resource to help the community progress toward capable autonomous agents. The benchmark can be found at https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Mar 12, 2024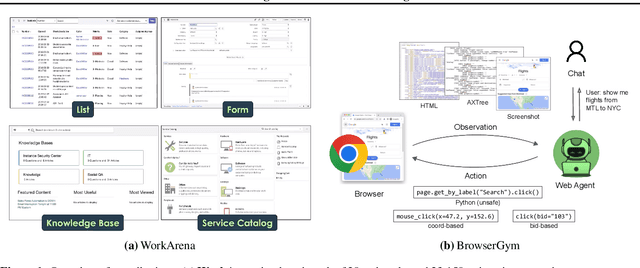
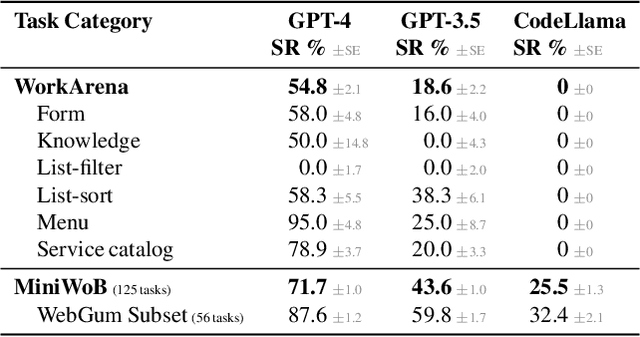

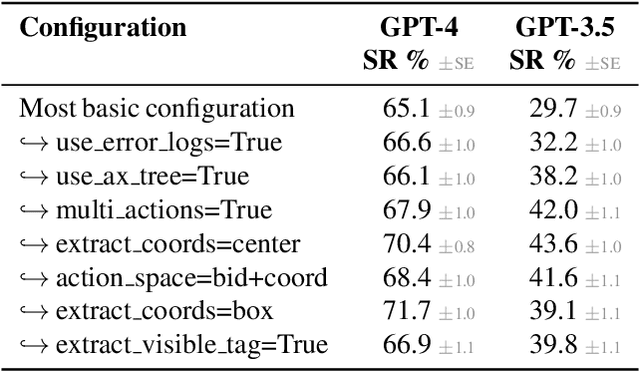
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 29 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
Pruning Sparse Tensor Neural Networks Enables Deep Learning for 3D Ultrasound Localization Microscopy
Feb 14, 2024
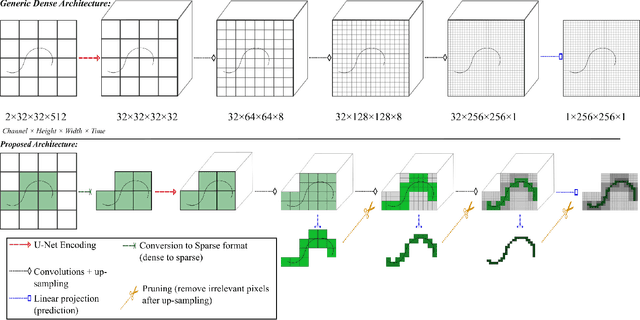
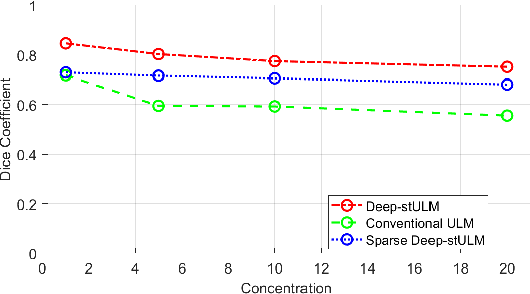
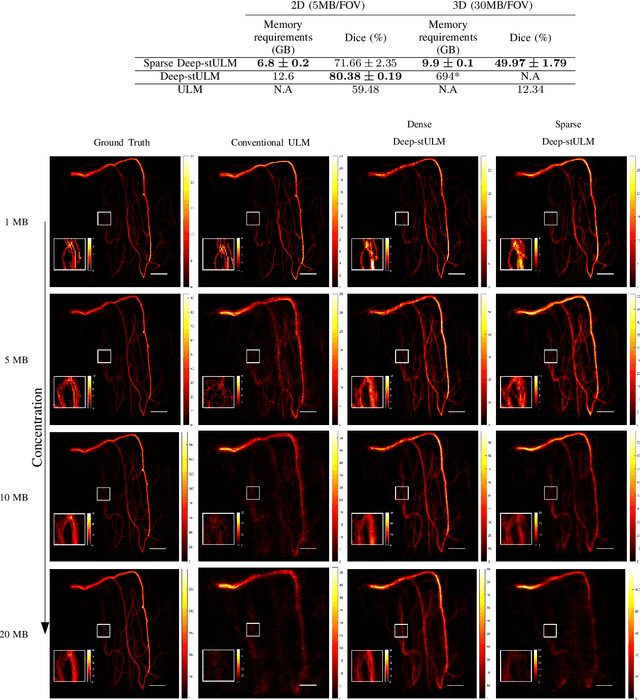
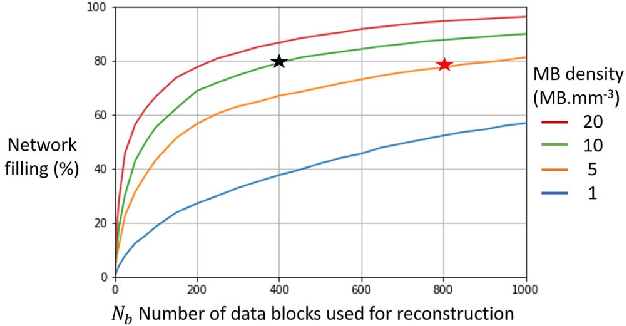
Ultrasound Localization Microscopy (ULM) is a non-invasive technique that allows for the imaging of micro-vessels in vivo, at depth and with a resolution on the order of ten microns. ULM is based on the sub-resolution localization of individual microbubbles injected in the bloodstream. Mapping the whole angioarchitecture requires the accumulation of microbubbles trajectories from thousands of frames, typically acquired over a few minutes. ULM acquisition times can be reduced by increasing the microbubble concentration, but requires more advanced algorithms to detect them individually. Several deep learning approaches have been proposed for this task, but they remain limited to 2D imaging, in part due to the associated large memory requirements. Herein, we propose to use sparse tensor neural networks to reduce memory usage in 2D and to improve the scaling of the memory requirement for the extension of deep learning architecture to 3D. We study several approaches to efficiently convert ultrasound data into a sparse format and study the impact of the associated loss of information. When applied in 2D, the sparse formulation reduces the memory requirements by a factor 2 at the cost of a small reduction of performance when compared against dense networks. In 3D, the proposed approach reduces memory requirements by two order of magnitude while largely outperforming conventional ULM in high concentration settings. We show that Sparse Tensor Neural Networks in 3D ULM allow for the same benefits as dense deep learning based method in 2D ULM i.e. the use of higher concentration in silico and reduced acquisition time.
A Deep Learning Framework for Spatiotemporal Ultrasound Localization Microscopy
Oct 12, 2023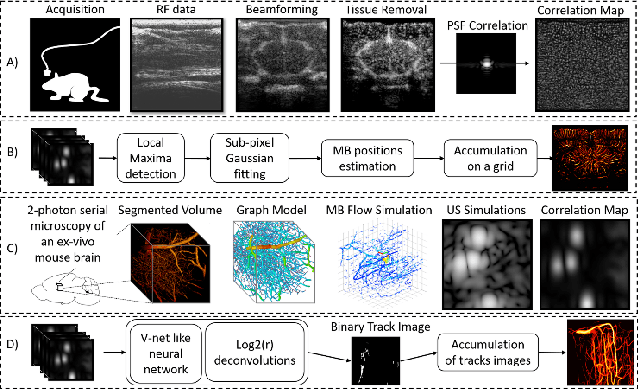
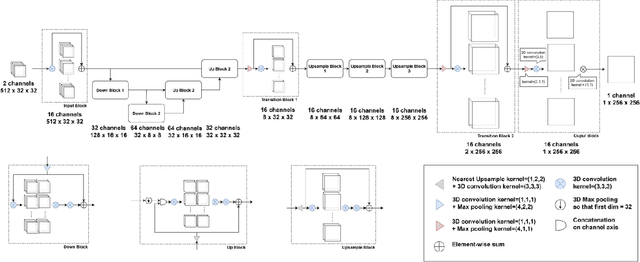
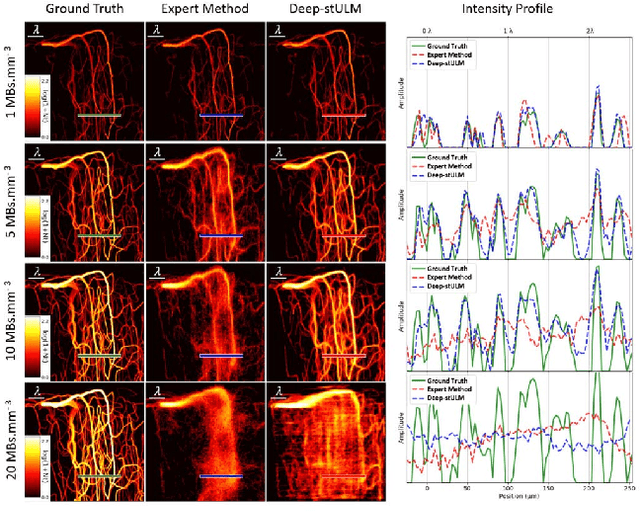
Ultrasound Localization Microscopy can resolve the microvascular bed down to a few micrometers. To achieve such performance microbubble contrast agents must perfuse the entire microvascular network. Microbubbles are then located individually and tracked over time to sample individual vessels, typically over hundreds of thousands of images. To overcome the fundamental limit of diffraction and achieve a dense reconstruction of the network, low microbubble concentrations must be used, which lead to acquisitions lasting several minutes. Conventional processing pipelines are currently unable to deal with interference from multiple nearby microbubbles, further reducing achievable concentrations. This work overcomes this problem by proposing a Deep Learning approach to recover dense vascular networks from ultrasound acquisitions with high microbubble concentrations. A realistic mouse brain microvascular network, segmented from 2-photon microscopy, was used to train a three-dimensional convolutional neural network based on a V-net architecture. Ultrasound data sets from multiple microbubbles flowing through the microvascular network were simulated and used as ground truth to train the 3D CNN to track microbubbles. The 3D-CNN approach was validated in silico using a subset of the data and in vivo on a rat brain acquisition. In silico, the CNN reconstructed vascular networks with higher precision (81%) than a conventional ULM framework (70%). In vivo, the CNN could resolve micro vessels as small as 10 $\mu$m with an increase in resolution when compared against a conventional approach.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Lookback for Learning to Branch
Jun 30, 2022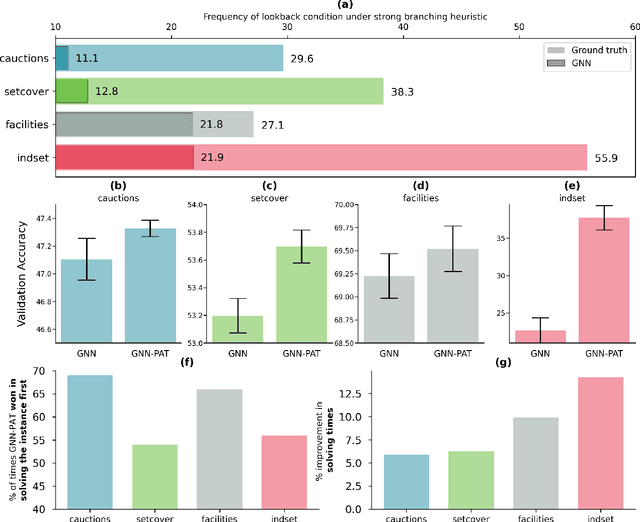

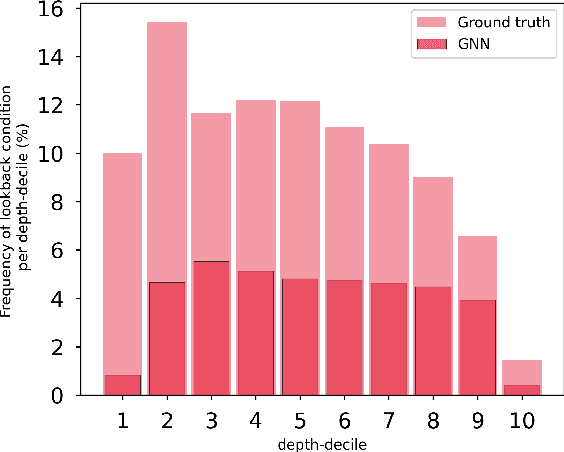

The expressive and computationally inexpensive bipartite Graph Neural Networks (GNN) have been shown to be an important component of deep learning based Mixed-Integer Linear Program (MILP) solvers. Recent works have demonstrated the effectiveness of such GNNs in replacing the branching (variable selection) heuristic in branch-and-bound (B&B) solvers. These GNNs are trained, offline and on a collection of MILPs, to imitate a very good but computationally expensive branching heuristic, strong branching. Given that B&B results in a tree of sub-MILPs, we ask (a) whether there are strong dependencies exhibited by the target heuristic among the neighboring nodes of the B&B tree, and (b) if so, whether we can incorporate them in our training procedure. Specifically, we find that with the strong branching heuristic, a child node's best choice was often the parent's second-best choice. We call this the "lookback" phenomenon. Surprisingly, the typical branching GNN of Gasse et al. (2019) often misses this simple "answer". To imitate the target behavior more closely by incorporating the lookback phenomenon in GNNs, we propose two methods: (a) target smoothing for the standard cross-entropy loss function, and (b) adding a Parent-as-Target (PAT) Lookback regularizer term. Finally, we propose a model selection framework to incorporate harder-to-formulate objectives such as solving time in the final models. Through extensive experimentation on standard benchmark instances, we show that our proposal results in up to 22% decrease in the size of the B&B tree and up to 15% improvement in the solving times.
Learning to branch with Tree MDPs
May 31, 2022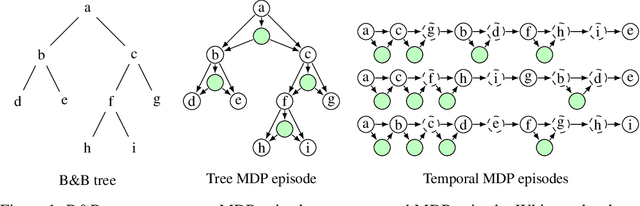

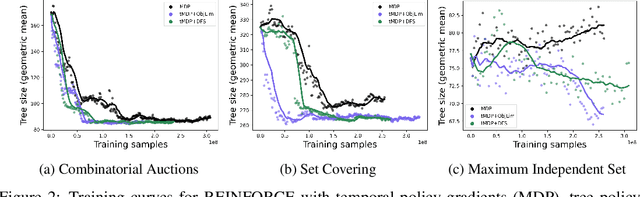
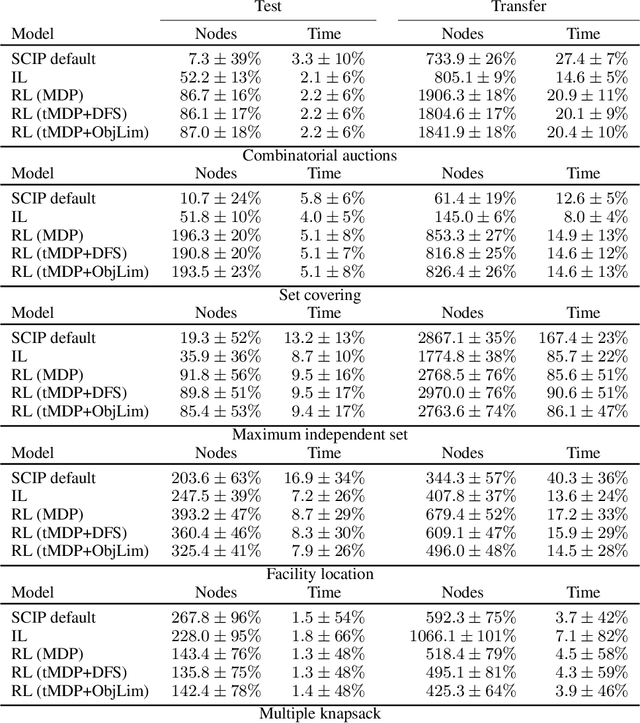
State-of-the-art Mixed Integer Linear Program (MILP) solvers combine systematic tree search with a plethora of hard-coded heuristics, such as the branching rule. The idea of learning branching rules from data has received increasing attention recently, and promising results have been obtained by learning fast approximations of the strong branching expert. In this work, we instead propose to learn branching rules from scratch via Reinforcement Learning (RL). We revisit the work of Etheve et al. (2020) and propose tree Markov Decision Processes, or tree MDPs, a generalization of temporal MDPs that provides a more suitable framework for learning to branch. We derive a tree policy gradient theorem, which exhibits a better credit assignment compared to its temporal counterpart. We demonstrate through computational experiments that tree MDPs improve the learning convergence, and offer a promising framework for tackling the learning-to-branch problem in MILPs.
The Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
Mar 17, 2022

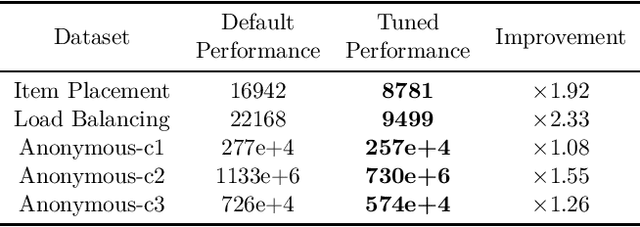
Combinatorial optimization is a well-established area in operations research and computer science. Until recently, its methods have focused on solving problem instances in isolation, ignoring that they often stem from related data distributions in practice. However, recent years have seen a surge of interest in using machine learning as a new approach for solving combinatorial problems, either directly as solvers or by enhancing exact solvers. Based on this context, the ML4CO aims at improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components. The competition featured three challenging tasks: finding the best feasible solution, producing the tightest optimality certificate, and giving an appropriate solver configuration. Three realistic datasets were considered: balanced item placement, workload apportionment, and maritime inventory routing. This last dataset was kept anonymous for the contestants.
Causal Reinforcement Learning using Observational and Interventional Data
Jun 28, 2021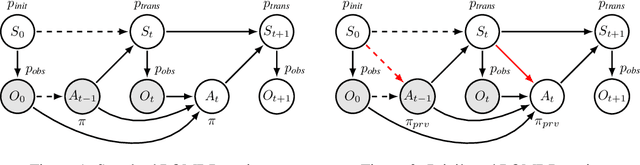



Learning efficiently a causal model of the environment is a key challenge of model-based RL agents operating in POMDPs. We consider here a scenario where the learning agent has the ability to collect online experiences through direct interactions with the environment (interventional data), but has also access to a large collection of offline experiences, obtained by observing another agent interacting with the environment (observational data). A key ingredient, that makes this situation non-trivial, is that we allow the observed agent to interact with the environment based on hidden information, which is not observed by the learning agent. We then ask the following questions: can the online and offline experiences be safely combined for learning a causal model ? And can we expect the offline experiences to improve the agent's performances ? To answer these questions, we import ideas from the well-established causal framework of do-calculus, and we express model-based reinforcement learning as a causal inference problem. Then, we propose a general yet simple methodology for leveraging offline data during learning. In a nutshell, the method relies on learning a latent-based causal transition model that explains both the interventional and observational regimes, and then using the recovered latent variable to infer the standard POMDP transition model via deconfounding. We prove our method is correct and efficient in the sense that it attains better generalization guarantees due to the offline data (in the asymptotic case), and we illustrate its effectiveness empirically on synthetic toy problems. Our contribution aims at bridging the gap between the fields of reinforcement learning and causality.