 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



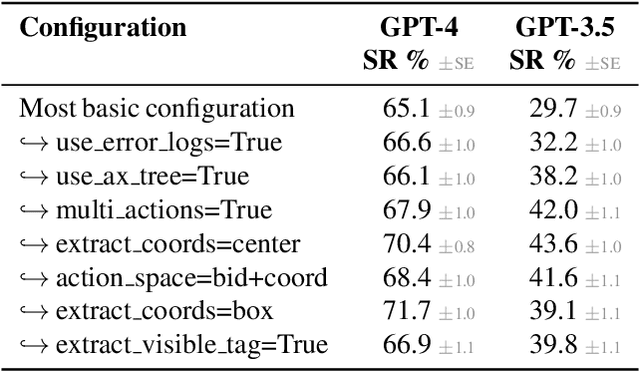
The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
Jul 07, 2024



The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though recent LLMs seem capable of planning and reasoning given user instructions, their effectiveness in applying these capabilities for autonomous task solving remains underexplored. This is especially true in enterprise settings, where automated agents hold the promise of a high impact. To fill this gap, we propose WorkArena++, a novel benchmark consisting of 682 tasks corresponding to realistic workflows routinely performed by knowledge workers. WorkArena++ is designed to evaluate the planning, problem-solving, logical/arithmetic reasoning, retrieval, and contextual understanding abilities of web agents. Our empirical studies across state-of-the-art LLMs and vision-language models (VLMs), as well as human workers, reveal several challenges for such models to serve as useful assistants in the workplace. In addition to the benchmark, we provide a mechanism to effortlessly generate thousands of ground-truth observation/action traces, which can be used for fine-tuning existing models. Overall, we expect this work to serve as a useful resource to help the community progress toward capable autonomous agents. The benchmark can be found at https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus.
Towards a Generic Representation of Combinatorial Problems for Learning-Based Approaches
Mar 13, 2024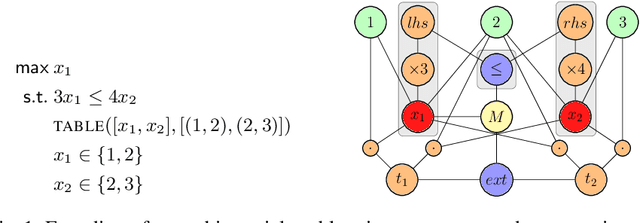


In recent years, there has been a growing interest in using learning-based approaches for solving combinatorial problems, either in an end-to-end manner or in conjunction with traditional optimization algorithms. In both scenarios, the challenge lies in encoding the targeted combinatorial problems into a structure compatible with the learning algorithm. Many existing works have proposed problem-specific representations, often in the form of a graph, to leverage the advantages of \textit{graph neural networks}. However, these approaches lack generality, as the representation cannot be easily transferred from one combinatorial problem to another one. While some attempts have been made to bridge this gap, they still offer a partial generality only. In response to this challenge, this paper advocates for progress toward a fully generic representation of combinatorial problems for learning-based approaches. The approach we propose involves constructing a graph by breaking down any constraint of a combinatorial problem into an abstract syntax tree and expressing relationships (e.g., a variable involved in a constraint) through the edges. Furthermore, we introduce a graph neural network architecture capable of efficiently learning from this representation. The tool provided operates on combinatorial problems expressed in the XCSP3 format, handling all the constraints available in the 2023 mini-track competition. Experimental results on four combinatorial problems demonstrate that our architecture achieves performance comparable to dedicated architectures while maintaining generality. Our code and trained models are publicly available at \url{https://github.com/corail-research/learning-generic-csp}.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Mar 12, 2024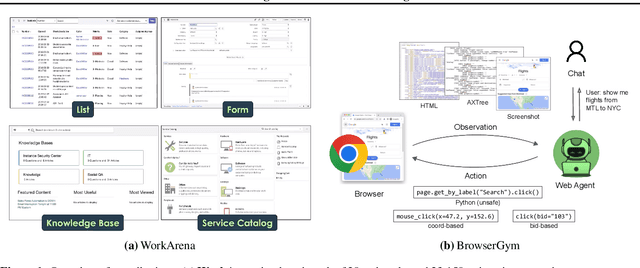
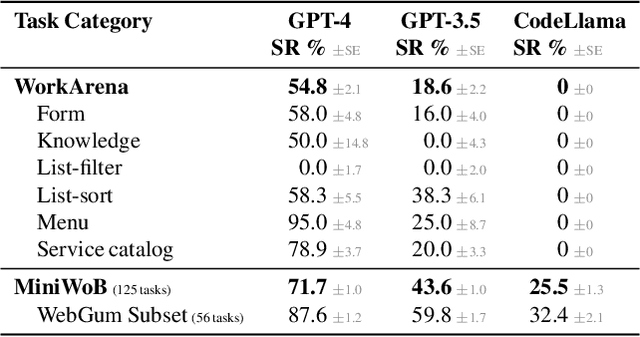

We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 29 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.