 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Decision-Focused Learning to Large Problems with Lagrangian Decomposition
Jun 07, 2026Decision-focused learning has shown great promise for addressing predict-then-optimize problems, particularly in the presence of under-specified models. However, its practical deployment is often hindered by high computational costs and limited scalability, as it requires solving a constrained optimization problem for each training instance at every iteration. To address these challenges, we propose a novel framework that incorporates Lagrangian decomposition into the decision-focused learning paradigm. Specifically, we introduce a new surrogate objective along with two loss functions for evaluating and training the underlying prediction model. We further propose two variants of our approach, which offer different trade-offs between computational efficiency and solution quality. Our framework can be seamlessly integrated with standard decision-focused learning methods, including Smart Predict-then-Optimize (SPO+) and Implicit Maximum Likelihood Estimation (IMLE). Through experiments on two standard benchmarks, the multi-dimensional knapsack problem and quadratic portfolio optimization, we demonstrate that our approach achieves competitive performance while remaining amenable to parallelization. In particular, it consistently outperforms traditional decision-focused learning methods on large-scale instances, involving up to eight times more variables than those typically considered in related work. The implementation is available at https://github.com/corail-research/DFL-LD.
Learning Admissible Heuristics via Cost Partitioning
Jun 03, 2026Admissible heuristics are essential for optimal planning, yet learning them remains challenging due to the risk of overestimation. Cost partitioning combines multiple abstraction heuristics while preserving admissibility, but computing optimal partitions online is expensive. We propose a framework that learns to infer admissible cost partitions by leveraging the Lagrangian dual equivalence between cost partitioning and multiplier prediction. Planning states and patterns are encoded as labelled graphs, and an action-centric variant of the Weisfeiler-Leman algorithm extracts structural feature vectors. A deep architecture with axial self-attention and a softmax output layer maps these features to cost weights that satisfy the partition constraints by construction, ensuring admissibility. Experiments demonstrate reduced node expansions compared to suboptimal partitioning baselines while maintaining strict admissibility. To our knowledge, this is the first machine-learned heuristic guaranteed to be admissible.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
Learning Valid Dual Bounds in Constraint Programming: Boosted Lagrangian Decomposition with Self-Supervised Learning
Aug 22, 2024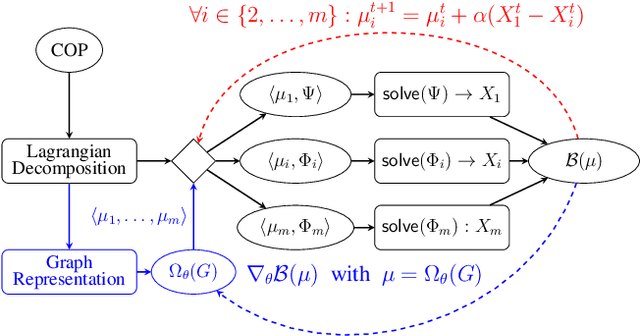

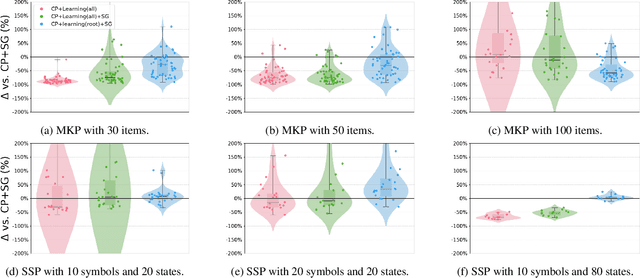
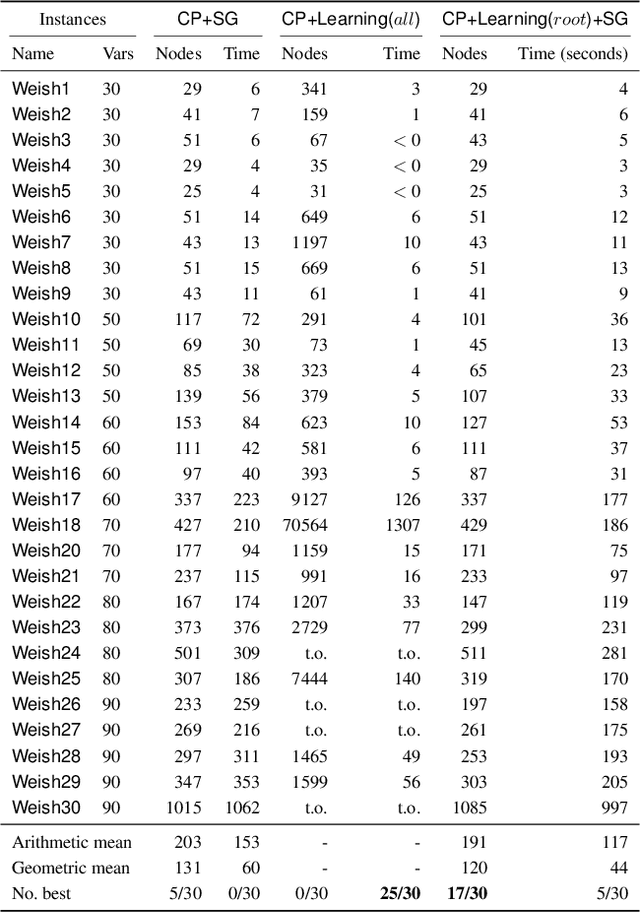
Lagrangian decomposition (LD) is a relaxation method that provides a dual bound for constrained optimization problems by decomposing them into more manageable sub-problems. This bound can be used in branch-and-bound algorithms to prune the search space effectively. In brief, a vector of Lagrangian multipliers is associated with each sub-problem, and an iterative procedure (e.g., a sub-gradient optimization) adjusts these multipliers to find the tightest bound. Initially applied to integer programming, Lagrangian decomposition also had success in constraint programming due to its versatility and the fact that global constraints provide natural sub-problems. However, the non-linear and combinatorial nature of sub-problems in constraint programming makes it computationally intensive to optimize the Lagrangian multipliers with sub-gradient methods at each node of the tree search. This currently limits the practicality of LD as a general bounding mechanism for constraint programming. To address this challenge, we propose a self-supervised learning approach that leverages neural networks to generate multipliers directly, yielding tight bounds. This approach significantly reduces the number of sub-gradient optimization steps required, enhancing the pruning efficiency and reducing the execution time of constraint programming solvers. This contribution is one of the few that leverage learning to enhance bounding mechanisms on the dual side, a critical element in the design of combinatorial solvers. To our knowledge, this work presents the first generic method for learning valid dual bounds in constraint programming.
MARCO: A Memory-Augmented Reinforcement Framework for Combinatorial Optimization
Aug 05, 2024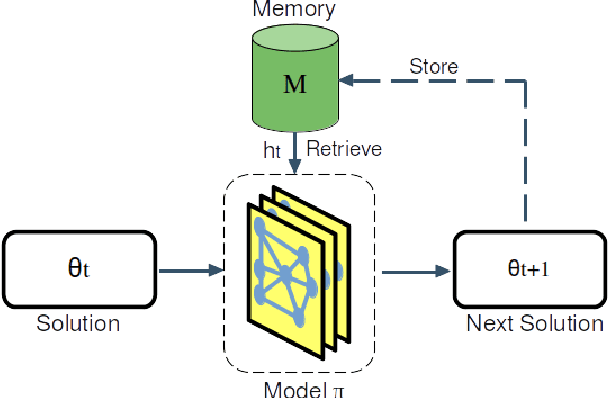

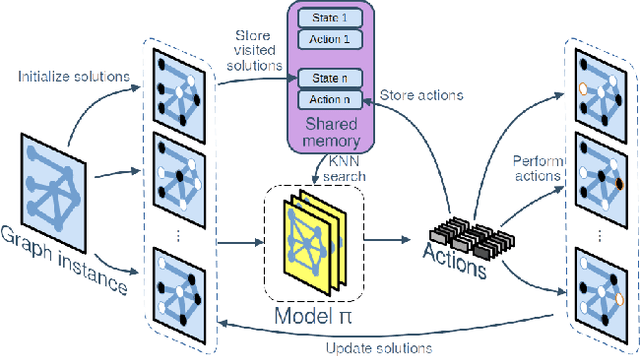
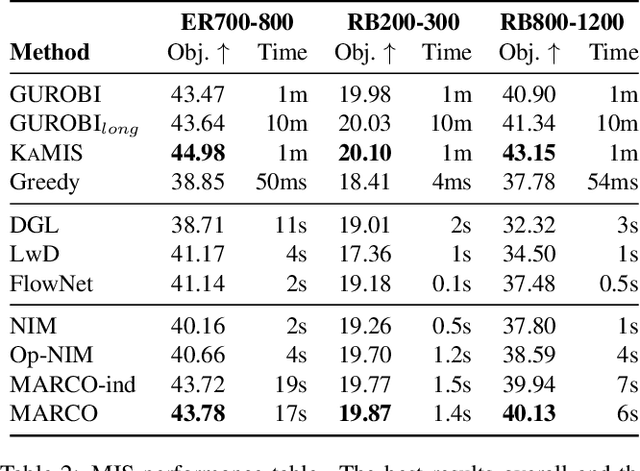
Neural Combinatorial Optimization (NCO) is an emerging domain where deep learning techniques are employed to address combinatorial optimization problems as a standalone solver. Despite their potential, existing NCO methods often suffer from inefficient search space exploration, frequently leading to local optima entrapment or redundant exploration of previously visited states. This paper introduces a versatile framework, referred to as Memory-Augmented Reinforcement for Combinatorial Optimization (MARCO), that can be used to enhance both constructive and improvement methods in NCO through an innovative memory module. MARCO stores data collected throughout the optimization trajectory and retrieves contextually relevant information at each state. This way, the search is guided by two competing criteria: making the best decision in terms of the quality of the solution and avoiding revisiting already explored solutions. This approach promotes a more efficient use of the available optimization budget. Moreover, thanks to the parallel nature of NCO models, several search threads can run simultaneously, all sharing the same memory module, enabling an efficient collaborative exploration. Empirical evaluations, carried out on the maximum cut, maximum independent set and travelling salesman problems, reveal that the memory module effectively increases the exploration, enabling the model to discover diverse, higher-quality solutions. MARCO achieves good performance in a low computational cost, establishing a promising new direction in the field of NCO.
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
Jul 07, 2024



The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though recent LLMs seem capable of planning and reasoning given user instructions, their effectiveness in applying these capabilities for autonomous task solving remains underexplored. This is especially true in enterprise settings, where automated agents hold the promise of a high impact. To fill this gap, we propose WorkArena++, a novel benchmark consisting of 682 tasks corresponding to realistic workflows routinely performed by knowledge workers. WorkArena++ is designed to evaluate the planning, problem-solving, logical/arithmetic reasoning, retrieval, and contextual understanding abilities of web agents. Our empirical studies across state-of-the-art LLMs and vision-language models (VLMs), as well as human workers, reveal several challenges for such models to serve as useful assistants in the workplace. In addition to the benchmark, we provide a mechanism to effortlessly generate thousands of ground-truth observation/action traces, which can be used for fine-tuning existing models. Overall, we expect this work to serve as a useful resource to help the community progress toward capable autonomous agents. The benchmark can be found at https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus.
Towards a Generic Representation of Combinatorial Problems for Learning-Based Approaches
Mar 13, 2024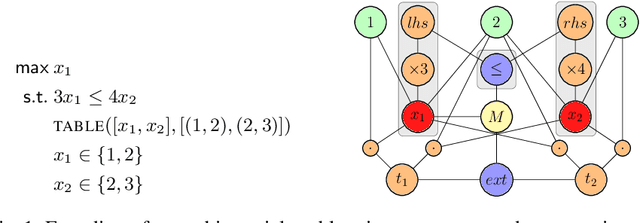


In recent years, there has been a growing interest in using learning-based approaches for solving combinatorial problems, either in an end-to-end manner or in conjunction with traditional optimization algorithms. In both scenarios, the challenge lies in encoding the targeted combinatorial problems into a structure compatible with the learning algorithm. Many existing works have proposed problem-specific representations, often in the form of a graph, to leverage the advantages of \textit{graph neural networks}. However, these approaches lack generality, as the representation cannot be easily transferred from one combinatorial problem to another one. While some attempts have been made to bridge this gap, they still offer a partial generality only. In response to this challenge, this paper advocates for progress toward a fully generic representation of combinatorial problems for learning-based approaches. The approach we propose involves constructing a graph by breaking down any constraint of a combinatorial problem into an abstract syntax tree and expressing relationships (e.g., a variable involved in a constraint) through the edges. Furthermore, we introduce a graph neural network architecture capable of efficiently learning from this representation. The tool provided operates on combinatorial problems expressed in the XCSP3 format, handling all the constraints available in the 2023 mini-track competition. Experimental results on four combinatorial problems demonstrate that our architecture achieves performance comparable to dedicated architectures while maintaining generality. Our code and trained models are publicly available at \url{https://github.com/corail-research/learning-generic-csp}.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Mar 12, 2024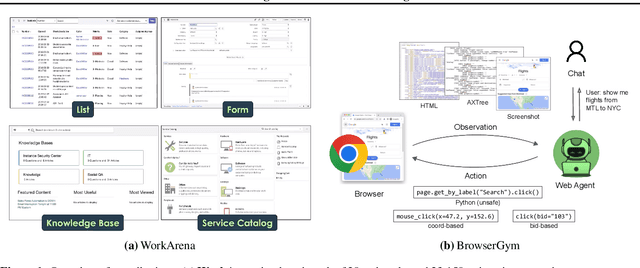
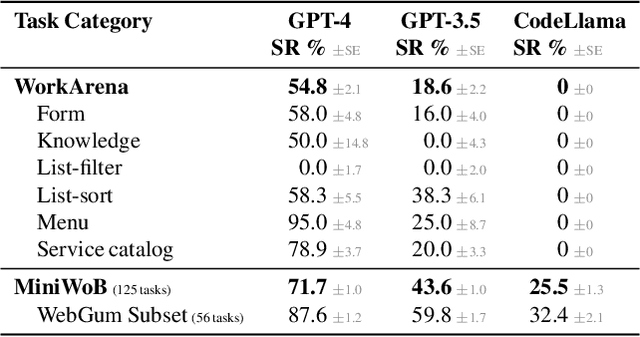

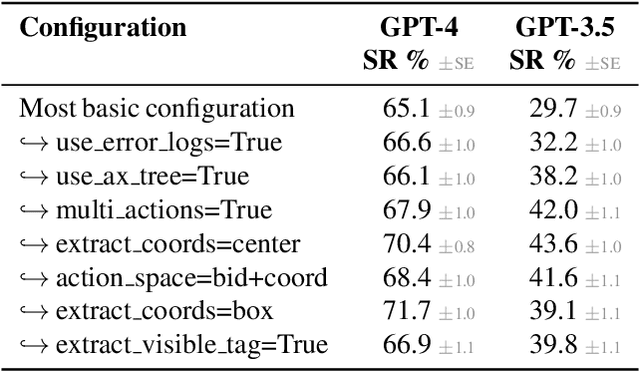
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 29 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
Learning Lagrangian Multipliers for the Travelling Salesman Problem
Dec 22, 2023



Lagrangian relaxation is a versatile mathematical technique employed to relax constraints in an optimization problem, enabling the generation of dual bounds to prove the optimality of feasible solutions and the design of efficient propagators in constraint programming (such as the weighted circuit constraint). However, the conventional process of deriving Lagrangian multipliers (e.g., using subgradient methods) is often computationally intensive, limiting its practicality for large-scale or time-sensitive problems. To address this challenge, we propose an innovative unsupervised learning approach that harnesses the capabilities of graph neural networks to exploit the problem structure, aiming to generate accurate Lagrangian multipliers efficiently. We apply this technique to the well-known Held-Karp Lagrangian relaxation for the travelling salesman problem. The core idea is to predict accurate Lagrangian multipliers and to employ them as a warm start for generating Held-Karp relaxation bounds. These bounds are subsequently utilized to enhance the filtering process carried out by branch-and-bound algorithms. In contrast to much of the existing literature, which primarily focuses on finding feasible solutions, our approach operates on the dual side, demonstrating that learning can also accelerate the proof of optimality. We conduct experiments across various distributions of the metric travelling salesman problem, considering instances with up to 200 cities. The results illustrate that our approach can improve the filtering level of the weighted circuit global constraint, reduce the optimality gap by a factor two for unsolved instances up to a timeout, and reduce the execution time for solved instances by 10%.
Global Rewards in Multi-Agent Deep Reinforcement Learning for Autonomous Mobility on Demand Systems
Dec 14, 2023We study vehicle dispatching in autonomous mobility on demand (AMoD) systems, where a central operator assigns vehicles to customer requests or rejects these with the aim of maximizing its total profit. Recent approaches use multi-agent deep reinforcement learning (MADRL) to realize scalable yet performant algorithms, but train agents based on local rewards, which distorts the reward signal with respect to the system-wide profit, leading to lower performance. We therefore propose a novel global-rewards-based MADRL algorithm for vehicle dispatching in AMoD systems, which resolves so far existing goal conflicts between the trained agents and the operator by assigning rewards to agents leveraging a counterfactual baseline. Our algorithm shows statistically significant improvements across various settings on real-world data compared to state-of-the-art MADRL algorithms with local rewards. We further provide a structural analysis which shows that the utilization of global rewards can improve implicit vehicle balancing and demand forecasting abilities. Our code is available at https://github.com/tumBAIS/GR-MADRL-AMoD.